1508
1508 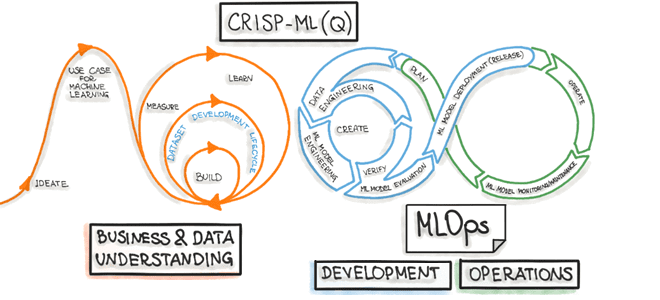
Что представляет собой межотраслевой стандартный процесс машинного обучения CRISP-ML(Q), из каких этапов и задач он состоит, а также как согласуется с концепцией MLOps.
Что такое CRISP-ML(Q) и при чем здесь MLOps
Стандартизация подходов и процессов позволяет унифицировать и масштабировать лучшие практики управления исследованиями и разработкой, в т.ч. распространяя их на другие домены. Например, CRISP-DM (Cross-Industry Standard Process for Data Mining) как наиболее распространенная методология выполнения Data Science проектов описывает их жизненный цикл в 6 фазах, каждая из которых включает ряд задач. Аналогично свод знаний по бизнес-анализу BABOK®Guide структурирует задачи, которые решает бизнес-аналитик, по 6 областям знаний. Подробно об этом мы писали здесь.
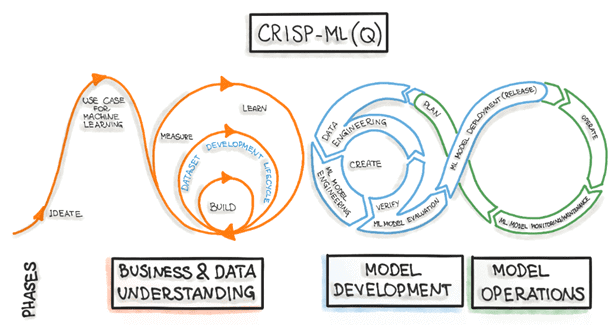
Аналогичный подход к организации машинного обучения был опубликован в 2012 году под названием CRISP-ML(Q). Это аббревиатура от CRoss-Industry Standard Process model for the development of Machine Learning applications with Quality assurance methodology. Будучи основанной на CRISP-DM, модель процесса CRISP-ML(Q) описывает шесть этапов:
- Понимание бизнеса и данных;
- Инженерия данных (подготовка данных);
- Моделирование машинного обучения;
- Обеспечение качества приложений машинного обучения;
- Развертывание ML-модели;
- Мониторинг и обслуживание ML-системы.
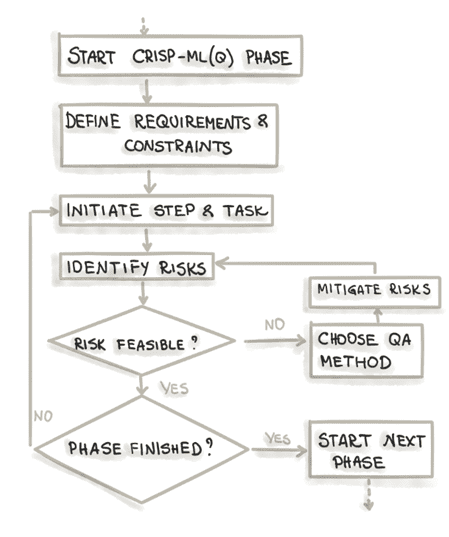
Для каждого этапа модели процесса подход к обеспечению качества в CRISP-ML(Q) требует определения требований и ограничений, таких как производительность, требования к качеству данных, к устойчивости модели и пр. Также должны быть определены этапы создания экземпляра модели процесса, конкретные задачи, например, выбор алгоритма Machine Learning, обучение ML-модели. Особое внимание уделяется рискам, которые могут негативно повлиять на эффективность и успех ML-приложения, например, смещение данных, переобучение алгоритмов, отсутствие воспроизводимости и т. д. Для этого должны быть определены методы обеспечения качества, такие как перекрестная проверка, документирование процесса и результатов, логирование экспериментов и пр. Инструментально это поддерживается средствами MLOps-концепции, которая стремится устранить организационные и технические барьеры между разнопрофильными участниками процессов создания ML-систем, от подготовки данных до развертывания в производстве.
Рассмотрим фазы CRISP-ML(Q) более подробно.
6 фаз CRISP-ML(Q)
Начнем с 1-ой фазы, понимание бизнеса и данных. Разработка любого приложения, в т.ч. системы машинного обучения, начинается с определения ее области применения, критериев успеха и проверки качества данных. Целью этого первого этапа является обеспечение осуществимости проекта. На этом этапе необходимо определить измеримые критерии успеха в бизнесе, машинном обучении и экономике. Для этого следует определить четкие и измеримые ключевые показатели эффективности (KPI), например, ускорение какой-либо операции. Полезным подходом является определение эвристического теста, не связанного с машинным обучением, для информирования стейкхолдеров со стороны бизнеса об эффекте Machine Learning на результат.
Также следует подтвердить осуществимость идеи перед запуском ML-проекта в промышленных условиях, определив доступность данных, нормативные ограничения и нефункциональные требования к приложению, такие как надежность, масштабируемость, объяснимость и потребность в ресурсах.
Поскольку именно данные определяют процесс, сбор данных и проверка их качества имеют важное значение для достижения бизнес-целей, важно документировать статистические свойства данных и процесса их генерации. Аналогично, требования к данным также должны быть сформулированы и задокументированы, поскольку это становится основой для обеспечения качества данных на этапе эксплуатации ML-проекта. Сделать это позволяют MLOps-инструменты, такие как MLflow, Kubeflow и т.д.
Второй этап модели процесса CRISP-ML(Q) называется инженерия данных и направлен на их подготовку для следующего этапа моделирования. На этом этапе выполняются задачи выбора данных, их очистки, разработки фичей и стандартизации. В задаче выбора используются методы фильтрации и отбора данных, включая отбрасывание образцов, которые не удовлетворяют требованиям качества. На этом шаге также можно решить проблему несбалансированных классов, применяя стратегии избыточной или недостаточной выборки.
Задача очистки данных подразумевает, что мы выполняем действия по обнаружению и исправлению ошибок для имеющихся данных. Добавление модульного тестирования данных снизит риск распространения ошибок на следующий этап. В зависимости от задачи машинного обучения может потребоваться выполнить действия по проектированию фичей и увеличение количества данных, включая их кластеризацию или дискретизацию непрерывных атрибутов.
Задача стандартизации данных включает процесс унификации входных данных инструментов ML, чтобы избежать риска ошибочных данных. Наконец, задача нормализации снизит риск смещения фичей в более крупных масштабах. Здесь создаются конвейеры преобразования данных, их предварительной обработки и создания фичей, чтобы обеспечить воспроизводимость работы ML-приложения.
Третьим этапом CRISP-ML(Q) является моделирование машинного обучения, чтобы определить одну или нескольких ML-моделей, которые будут развернуты в производстве. Этот этап определяется ограничениями и требованиями, полученными на этапе понимания бизнеса и данных. Например, метрики оценки модели предметной области приложения могут включать в себя метрики производительности, надежности, справедливости, масштабируемости, интерпретируемости, степени сложности модели и потребности ML-приложения в ресурсах. MLOps-специалист должен скорректировать важность каждой из этих метрик в соответствии со сценарием использования.
Как правило, этап моделирования включает в себя выбор ML-модели, ее специализацию и обучение. Можно использовать предварительно обученную модель, сжимать ее или применять методы ансамблевого обучения, чтобы получить окончательный алгоритм машинного обучения. Чтобы обеспечить воспроизводимость метода обучения и результатов этапа моделирования следует собирать метаданные этого процесса, такие как алгоритм, датасеты для обучения, валидации и тестирования, гиперпараметры модели и описание среды выполнения. Воспроизводимость результатов предполагает проверку средней производительности модели на различных случайных начальных числах. Поскольку этапы разработки ML-системы являются итеративными, важно обеспечить реестр моделей и экспериментов. Наконец, MLOps-инженер упаковывает процесс в конвейер, чтобы сделать его повторяемым и воспроизводимым.
После этапа ML-моделирования следует этап оценки модели Machine Learning или автотестирование, когда производительность обученной модели проверяется на тестовом наборе данных. Надежность модели следует оценивать с использованием зашумленных или неправильных входных данных. Рекомендуется разработать объяснимую ML-модель, чтобы обеспечить доверие пользователей и соответствовать нормативным требованиям. Итоговое решение о развертывании ML-модели в производстве принимается на основе критериев успеха с учетом мнения экспертов в предметной области и машинном обучении. Как и на предыдущих этапах, все результаты оценки необходимо документировать.
Следующим этапом CRISP-ML(Q) является развертывание ML-модели в производственной среде, включая интеграцию математических алгоритмов в программную инфраструктуру. Подходы к развертыванию определяются на первом этапе жизненного цикла разработки ML-системы и зависят от варианта использования, а также методов обучения и прогнозирования: пакетного или потокового. В частности, развертывание ML-модели означает раскрытие ее прогнозных фичей в виде интерактивных информационных панелей, предварительно вычисленных прогнозов, включение алгоритма в качестве плагина в микроядерную архитектуру ПО или конечной точки веб-сервиса в микросервисной системе.
Развертывание включает определение аппаратного обеспечения вывода, оценку модели в производственной среде (A/B-тесты), обеспечение приемлемости результатов для пользователя, тестирование удобства использования, организацию плана на случай сбоев и стратегию постепенного развертывания новой модели, например, канареечное или сине-зеленое развертывание, о чем мы писали здесь.
Наконец, после запуска ML-модели в производство важно отслеживать ее производительность и поддерживать ее. Когда ML-модель работает с реальными данными, главным риском становится эффект ее устаревания, когда производительность модели падает из-за работы с ранее неизвестными данными. Также на производительность алгоритма Machine Learning влияют производительность программного и аппаратного обеспечения. Чтобы предотвратить падение производительности, следует обеспечить непрерывный мониторинг этой метрики. Такая оценка позволяет MLOps-инженеру понять, нужно ли переобучать модель.
Визуализируем этапы и задачи CRISP-ML(Q) в табличном виде.
|
Этап CRISP-ML(Q) |
Задачи |
|
Понимание бизнеса и данных |
· Определить бизнес-цели · Преобразовать бизнес-цели в цели машинного обучения · Собрать и проверить данные · Оценить осуществимость проекта · Подтвердить концепцию с помощью POC (Prof Of Concept) |
|
Инженерия данных |
· Выбор фичей · Выбор данных · Балансировка классов · Очистка данных (подавление шума) · Разработка фичей · Увеличение данных · Стандартизация данных |
|
Разработка моделей машинного обучения |
· Определить показатель качества модели · Выбрать алгоритма машинного обучения (базовый выбор) · Добавить специфику предметной области для специализации модели · Обучить модель · Сжатие модели · Ансамблевое обучение · Документировать ML-модели и эксперименты |
|
Оценка модели машинного обучения |
· Проверить производительность модели · Определить надежность · Улучшить объяснимость модели · Принять решение о развертывании в производстве · Документировать этап оценки |
|
Развертывание модели |
· Оценить модель в рабочем состоянии · Обеспечить приемлемость и удобство использования · Организовать управление моделью · Выбрать стратегию развертывания и реализовать ее |
|
Мониторинг и обслуживание модели |
· Обеспечить мониторинг эффективности и результативности предоставления прогнозов модели · Сравнить результаты с ранее указанными критериями успеха (пороговыми значениями) · Повторно обучить модель (при необходимости) · Собрать новые данные · Выполнить разметку новых точек данных · Повторить задачи этапов моделирования и оценки, чтобы обеспечить непрерывность MLOps-процессов |
Таким образом, CRISP-ML(Q) как систематическая методология процесса разработки ПО машинного обучения неразрывно связана с концепцией и инструментарием MLOps. Совместное использование этих подходов позволяет осознать возможные риски и обеспечить качества результирующего продукта для успеха применения Machine Learning к задачам реального бизнеса.
Узнайте больше про использование MLOps-инструментов в системах аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники