 1179
1179 
Содержание
Как установить и отследить в Apache AirFlow зависимости экземпляров задач друг от друга, узнать о запуске конкретной задачи в DAG, использовать обратные вызовы и правила триггеров, а также шаблоны и макросы Jinja. Полезные примеры управления ETL-конвейерами для дата-инженера в GUI и CLI-интерфейсах.
Как узнать время запуска последнего экземпляра задачи?
Будучи популярным и зрелым ETL-оркестратором с длительной историей успешного использования в реальных проектах, Apache AirFlow до сих пор содержит множество ошибок и неочевидных особенностей. В частности, возврат последнего успешного запуска всего DAG вместо отдельного экземпляра конкретной задачи из него. Но для тестирования и отладки ETL-конвейера обработки данных дата-инженеру бывает нужно знать именно сбой отдельно взятой задачи, а не всего DAG, например, чтобы убедиться в актуальности извлекаемых данных. Однако, по умолчанию Apache AirFlow, отображается предыдущая дата успешного выполнения DAG, а не TaskInstance, что фактически делает конвейер неспособными автоматически наверстать упущенное, если только вся цепочка задач не выйдет из строя.
Напомним, Apache AirFlow определяет задачи как единицу работы в DAG, которая написана на Python и представляет собой выполнение оператора Python. При выполнении задача каждый раз реализует оператор со значениями для определения этого конкретного оператора. Например, PythonOperator используется для запуска Python-кода, а BashOperator по умолчанию является командой Bash.
Можно сказать, что DAG — это графовое представление задач в иерархическом порядке. Каждая задача показана на диаграмме с потоком выполнения от одной задачи к другой. Запуск DAG работает как расширение DAG во времени. У всех запусков DAG есть расписание, которое необходимо соблюдать, но у DAG может быть расписание, а может и не быть. Примеры полезных лайфхаков по работе с DAG смотрите в нашей новой статье.
Экземпляры задач AirFlow определяются как представление конкретного запуска задачи и категоризации с набором DAG, задачи и момента времени. У каждого экземпляра задачи есть последующий цикл, который указывает, в каком состоянии он находится, например, работа. успешное завершение или сбой. Всего у экземпляра задачи может быть одно из 14 возможных состояний.
Когда DAG включен, планировщик AirFlow создает несколько его запусков, для каждого определяя дату исполнения (execution_date), позволяя дата-инженеру планировать запуски конвейера обработки данных с нужным интервалом. Для каждого запуска DAG создаются экземпляры задач, входящих в него. Причем дата выполнения для каждого экземпляра определяется значением даты выполнения этого конкретного запуска DAG.
Исправить это, чтобы получить сведения о запуске конкретной задачи, можно, напрямую обратившись к модели данных AirFlow. Как и многие другие Python-фреймворки, Apache AirFlow использует ORM (Object Relational Mapper) для абстрагирования доступа к своей внутренней базе данных, т.е. библиотеку SQLAlchemy. Это позволяет напрямую обращаться к базе данных метаданных, реализуя решение рассматриваемой проблемы в виде следующих 4-х шагов:
- Получить объекты TaskInstance на основе указанного состояния;
- Получить последний успешный экземпляр TaskInstance для предоставленной задачи;
- Получить DAGRun, связанный с последним успешным экземпляром TaskInstance, для предоставленной задачи;
- Использовать эту информацию в DAG.
Примеры Python-кода, реализующего эту идею, доступны в источнике [2].
Еще 5 полезных рекомендаций по работе с задачами Apache AirFlow
Для непрерывного мониторинга работоспособности ETL-конвейера бывает полезно установить оповещение в Slack, Teams и других мессенджерах, если задача не удалась. Это можно сделать с помощью метода on_failure_callback(), передав функцию, которая позже будет вызываться с параметром словаря контекста. Аналогично можно использовать обратные вызовы on_success_callback(), on_retry_callback() и sla_miss_callback(). Также можно поддерживать дополнительные параметры для обратных вызовов с помощью пакета functools.partial, например:
from functools import partial
from airflow.operators.dummy import DummyOperator
SLACK_CHANNEL = "#help-dataengineering"
def allert_to_slack(context: dict, channel: str):
# Handle you slack allert here
pass
task1 = DummyOperator(
task_id="task1", on_failure_callback=partial(allert_to_slack, channel=SLACK_CHANNEL)
)
Однако, запустить отдельный оператор в качестве обратного вызова нельзя. Но есть способ реализовать это, чтобы каждый из шагов был отдельной задачей AirFlow, запускаемой по какому-то правилу и триггеру. Например, установка кластера за один шаг, запуск задания на втором этапе и удаление кластера в конце. Каждый из этих шагов должен быть отдельной задачей AirFlow, при этом кластер должен быть уничтожен независимо от результата предыдущих задач. По умолчанию AirFlow ожидает успешного выполнения всех вышестоящих задач. Изменить это поведение можно с помощью trigger_rule. Правило триггера по умолчанию all_success. В следующем примере используем правило all_done:
from airflow.providers.google.cloud.operators.dataproc import DataprocDeleteClusterOperator
delete_cluster = DataprocDeleteClusterOperator(
task_id="delete_cluster",
trigger_rule="all_done",
project_id=PROJECT_ID,
cluster_name=CLUSTER_NAME,
region=REGION
)
create_cluster >> run_job >> delete_cluster
Впрочем, помимо зависимостей задач, устанавливаемых с помощью оператора >> / << или set_downstream / set_upstream, можно также установить прошлые зависимости, чтобы экземпляр задачи зависел от состояния предыдущего экземпляра задачи. В AirFlow это можно сделать одним из следующих способов:
- depend_on_past — если установлено значение True, экземпляр задачи будет зависеть от успеха его предыдущего экземпляра. При этом последний экземпляр задачи не будет запланирован, если предыдущий экземпляр не завершился успешно.
- wait_for_downstream — если установлено значение True, экземпляр задачи будет ожидать успешного завершения задач, непосредственно следующих за предыдущим экземпляром этой же задачи, прежде чем он запустится. Например, третий экземпляр задачи не запланирован, если 2-ой экземпляр этой же задачи не выполнен.
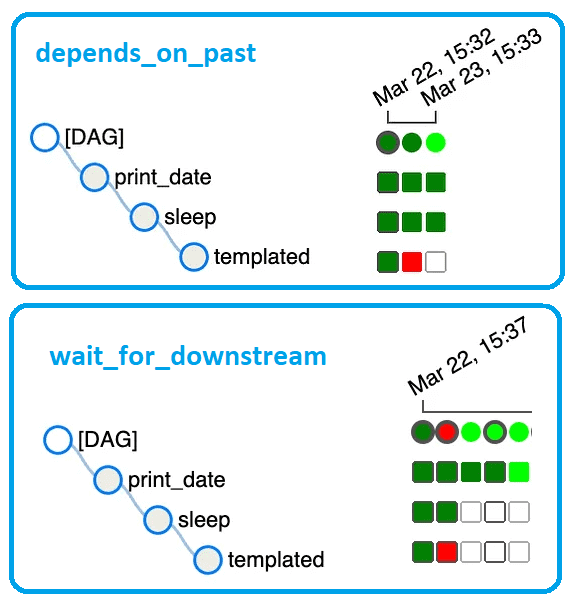
Понять, почему задача не запланирована, можно с помощью пользовательского интерфейса AirFlow, просмотрев сведения об экземпляре задачи, где отображаются зависимости, блокирующие задачу от планирования.
Также упростить управление задачами в Apache AirFlow можно, используя шаблоны Jinja – фреймворк шаблонов на Python. В частности, дата-инженеры часто используют шаблонную переменную для логической (ранее выполненной) даты {{ ds }}, которая означает начало интервала расписания. Через {{ dag }} можно обратиться к объекту DAG, через {{ task }} — к объекту задачи, а {{ var.value.my_var }} означает словарь с глобально определенными переменными. Например, следующим образом можно получить данные с помощью SQL-запроса для всего интервала DAG:
from airflow.operators.bash import BashOperator
BashOperator(
task_id="print_data_interval",
bash_command="Start of schedule interval {{ data_interval_start }}, end of schedule interval {{ data_interval_end }}",
)
Также можно применять макросы, чтобы пользоваться возможностями Python-библиотек (datetime, random, dateutil и пр.) внутри своих шаблонов. Следующий пример будет печатать год дня за четыре дня до логической даты:
{{ (execution_date — macros.timedelta(days=4)).strftime('%Y') }}
Однако, не все аргументы каждого оператора могут использовать шаблоны, а только те, которые прописаны в свойстве оператора template_fields. Узнать, какие поля являются шаблонными, можно в определении оператора или в пользовательском интерфейсе AirFlow, просмотрев сведения об экземпляре задачи. Почему важно следить за значениями этих полей, читайте в нашей новой статье.
В заключение отметим несколько полезных команд в CLI-интерфейсе AirFlow:
- airflow config list/get-value — просмотреть текущую конфигурацию;
- airflow dags next-execution — получить дату и время следующего выполнения DAG;
- airflow dags show — отображать граф DAG в виде файла PNG или DOT;
- airflow dags test — выполнить один единственный dagrun для заданного DAG и даты выполнения, используя DebugExecutor;
- airflow variable list/get — просмотреть текущие переменные.
О другой полезной для дата-инженера функции управления целым DAG или его отдельными задачами читайте в нашей новой статье. А про лучшие практики работы с XCom-объектами и правилами триггеров вы узнаете здесь.
Узнайте больше про администрирование и эксплуатацию Apache AirFlow для дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

