 1464
1464 
Содержание
Data Flow (Поток данных) — это концепция перемещения информации от источника к получателю через цепочку преобразований. Если представить IT-систему как завод, то Data Flow — это конвейерная лента. По ней движутся детали, превращаясь из сырья в готовый продукт.
В мире Big Data данные никогда не стоят на месте. Они рождаются в логах серверов, кликах пользователей или датчиках IoT. Затем они летят через шины сообщений, очищаются, агрегируются и оседают в аналитических витринах. Понимание Data Flow — это навык видеть не отдельные скрипты, а всю «кровеносную систему» организации.
Архитектор данных не просто пишет код. Он проектирует маршруты движения информации. Он должен предусмотреть «пробки», аварии и возможность расширения дорог. Без грамотно выстроенного потока данных даже самые мощные алгоритмы Machine Learning останутся без топлива.
Анатомия Data Flow: Из чего состоит поток
Любой поток данных, будь то простейший скрипт или сложная банковская система, состоит из трех фундаментальных элементов. Эта абстракция помогает декомпозировать любую задачу, какой бы страшной она ни казалась.
Рассмотрим ключевые узлы архитектуры:
- Source (Источник). Точка входа данных. Это может быть база данных (PostgreSQL), очередь сообщений (Kafka), файлы (HDFS) или HTTP-запрос. Источник ничего не знает о дальнейшей судьбе данных.
- Processor (Преобразователь). «Сердце» потока. Здесь происходит работа: фильтрация мусора, объединение с другими таблицами (join), смена формата или агрегация. Узлов обработки может быть сколько угодно.
- Sink (Сток). Конечная точка маршрута. Очищенные данные сохраняются в Data Lake, обновляют дэшборд или отправляют уведомление в Telegram.
Эти компоненты выстраиваются в DAG (Directed Acyclic Graph) — направленный ациклический граф. Данные движутся строго вперед, от источника к стоку. Они никогда не зацикливаются сами на себя, чтобы избежать бесконечных петель обработки.
Data Flow против Control Flow: Сдвиг парадигмы
Для программистов, пришедших из классической разработки (backend), переход в Data Engineering часто сложен. Причина кроется в разнице мышления. Нужно переключиться с управления потоком исполнения (Control Flow) на управление потоком данных.
В классическом программировании мы мыслим инструкциями Control Flow:
Если (if) переменная X больше 10,
то сделай это.
Иначе (else) сделай то.
Потом повтори (loop) 5 раз.
Здесь вы управляете порядком действий процессора. Логика диктует движение.
В инженерии данных мы мыслим декларативно в стиле Data Flow:
Возьми поток событий.
Оставь только те, где X > 10.
Сгруппируй их по пользователям.
Положи в базу.
Здесь вы описываете трансформацию, а не порядок шагов. Вы не говорите системе, как брать данные (в цикле или параллельно). Вы говорите, что хотите получить. Это позволяет системам вроде Spark или Flink автоматически распараллеливать задачи на сотни серверов.
Типология потоков: Batch vs Streaming
В современной инженерии данных существует два режима передачи данных. Выбор между ними определяет архитектуру проекта и стоимость инфраструктуры.
Давайте разберем их особенности на простых примерах:
- Batch Processing (Пакетная обработка)
Исторически первый подход. Мы накапливаем данные за период (час, день) в «пакет». Затем запускаем тяжелый процесс, который перемалывает этот архив. Это похоже на стирку белья: вы копите одежду неделю, чтобы запустить машинку один раз в воскресенье. - Stream Processing (Потоковая обработка)
Обработка данных по мере поступления, в реальном времени. Событие произошло — система мгновенно отреагировала. Это похоже на мытье посуды сразу после еды: грязных тарелок не накапливается.
Сравним подходы наглядно:
| Характеристика | Batch Processing | Stream Processing |
| Задержка (Latency) | Высокая (минуты, часы) | Низкая (миллисекунды, секунды) |
| Данные | Ограниченный набор (Bounded) | Бесконечный поток (Unbounded) |
| Сложность | Низкая (легко перезапустить) | Высокая (нужна отказоустойчивость) |
| Нагрузка | Пиковая (в момент расчета) | Равномерная (постоянная) |
Проблема Backpressure: Когда труба слишком узкая
Это коварная проблема Data Flow, о которой новички часто забывают. Backpressure (Обратное давление) возникает, когда источник (Producer) генерирует данные быстрее, чем получатель (Consumer) успевает их обрабатывать.

Представьте воронку, в которую вы льете воду из ведра. Если лить слишком быстро, воронка переполнится, и вода польется через край. В Data Engineering «вода через край» — это потерянные данные или упавший с ошибкой Out of Memory сервер.
Как инженеры решают эту проблему:
- Буферизация: Временно складывать излишки в очередь (Kafka). Это сглаживает пики. Но если очередь переполнится, проблема вернется.
- Dropping (Сброс): Если данные не критичны (например, частые метрики температуры), мы можем выкидывать старые пакеты.
- Блокировка источника: Consumer посылает сигнал Producer’у: «Горшочек, не вари!». Источник приостанавливает отправку. Это часть стандартов Reactive Streams.
- Масштабирование: Если один Consumer не справляется, мы добавляем еще пять параллельных Consumer’ов.
Грамотно спроектированный поток всегда имеет защиту от Backpressure. Иначе ваша система рухнет при первой же пиковой нагрузке.
Инструменты реализации Data Flow
Экосистема Big Data огромна, но есть «большая четверка» инструментов. С ними вы столкнетесь в большинстве проектов.
Краткий обзор технологий:
- Apache NiFi: Инструмент для визуального программирования. Вы перетаскиваете кубики на холсте и соединяете их стрелками. Идеально для простых задач перекладки данных без кода.
- Apache Kafka: Центральная нервная система архитектуры. Распределенный лог событий, который отвязывает источники от приемников. Гарантирует, что данные не потеряются.
- Apache Spark: Самый популярный движок для «тяжелой» обработки. Умеет работать и с пакетами, и с потоками (Spark Structured Streaming). Позволяет писать сложную логику на SQL или Python.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
1 июня, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
- Apache Airflow: Оркестратор процессов. Он не обрабатывает данные сам, но управляет запуском задач. Airflow рисует красивый граф зависимостей и следит за расписанием.
Практикум: Реализация Data Flow (Docker + Python)
Перейдем от теории к практике. Чтобы не тратить время на облака, мы поднимем мини-кластер Apache Kafka локально через Docker. Это бесплатно, быстро и безопасно.
Что нам понадобится:
- Docker и Docker Compose.
- Python 3.x.
- Библиотека kafka-python (ставится через pip install kafka-python).
Шаг 0: Запуск инфраструктуры
Создайте файл docker-compose.yml с кодом ниже. Мы используем образ Apache Kafka в режиме KRaft (без Zookeeper) для экономии ресурсов.
version: "3.7"
services:
kafka:
image: 'apache/kafka:latest'
ports:
- '9092:9092'
environment:
KAFKA_NODE_ID: "0"
KAFKA_PROCESS_ROLES: "controller,broker"
KAFKA_CONTROLLER_QUORUM_VOTERS: "0@kafka:9093"
KAFKA_LISTENERS: "PLAINTEXT://:9092,CONTROLLER://:9093"
KAFKA_ADVERTISED_LISTENERS: "PLAINTEXT://localhost:9092"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: "CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT"
KAFKA_CONTROLLER_LISTENER_NAMES: "CONTROLLER"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: "1"
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: "1"
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: "1"
Запустите контейнер командой: docker-compose up -d. Теперь у вас есть свой брокер сообщений на порту 9092.

Шаг 1: Producer (Генератор данных)
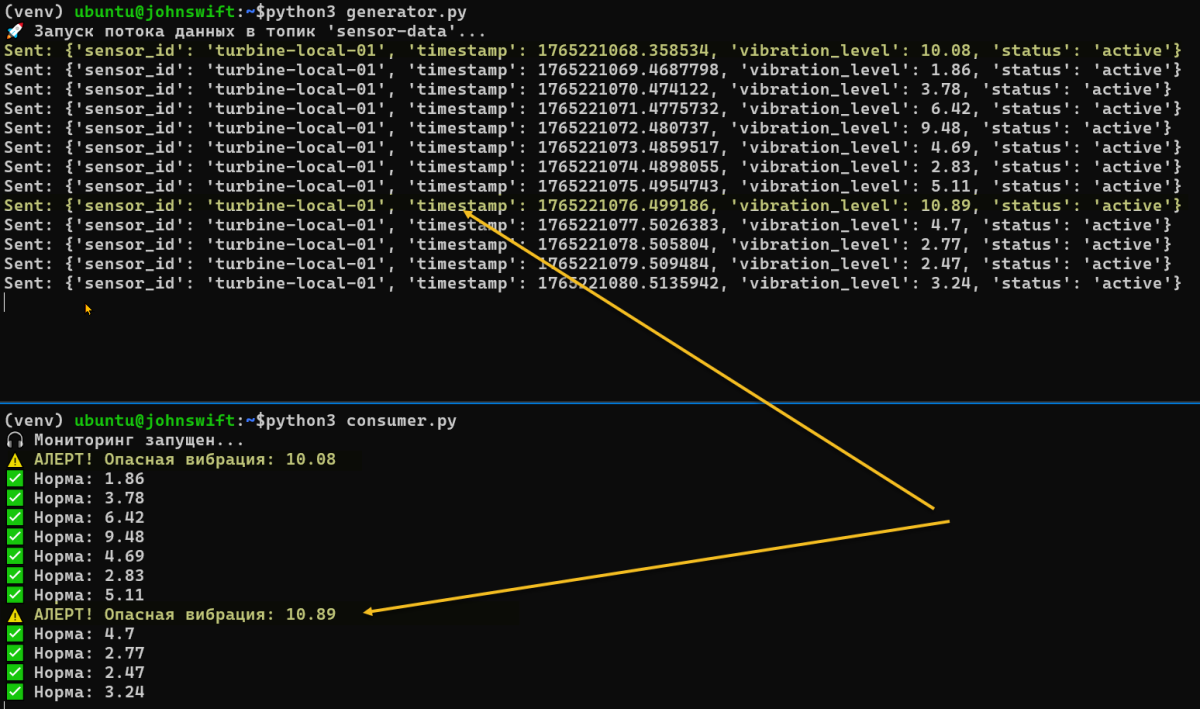
Скрипт имитирует датчик турбины. Он создает JSON-события и отправляет их в поток. Создадим файлик generator.py для работы Producer Kafka и запустим его командой
python3 generator.py
import time
import json
import random
from kafka import KafkaProducer
# Подключение к локальному Docker-контейнеру
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
TOPIC_NAME = 'sensor-data'
print(f"🚀 Запуск потока данных в топик '{TOPIC_NAME}'...")
try:
while True:
# Эмуляция данных
data = {
"sensor_id": "turbine-local-01",
"timestamp": time.time(),
"vibration_level": round(random.uniform(0.5, 12.0), 2),
"status": "active"
}
producer.send(TOPIC_NAME, value=data)
producer.flush() # Принудительная отправка из буфера
print(f"Sent: {data}")
time.sleep(1)
except KeyboardInterrupt:
producer.close()
Шаг 2: Consumer (Обработчик)
Этот скрипт Consumer «слушает» эфир. Если вибрация превышает норму, он выводит алерт.
import json
from kafka import KafkaConsumer
CRITICAL_THRESHOLD = 10.0
consumer = KafkaConsumer(
'sensor-data',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest', # Читать только новые
group_id='alert-system-group',
value_deserializer=lambda x: json.loads(x.decode('utf-8'))
)
print("🎧 Мониторинг запущен...")
for message in consumer:
event = message.value
vibration = event.get('vibration_level')
if vibration > CRITICAL_THRESHOLD:
print(f"⚠️ АЛЕРТ! Опасная вибрация: {vibration} Покинуть помещение")
else:
print(f"✅ Норма: {vibration}")
Запустите скрипты в разных терминалах. Вы увидите, как данные перелетают между процессами. Это и есть живой Data Flow.
Заключение
Data Flow — это больше, чем просто передача байтов из точки А в точку Б. Это философия проектирования устойчивых систем.2
Начиная свой путь, запомните три правила:
- Думайте графами: Рисуйте, откуда данные приходят и куда уходят.
- Учитывайте время: Понимайте разницу между Batch и Streaming.
- Ожидайте сбоев: Проектируйте так, чтобы при падении узла данные сохранялись в буфере.
Понимание этих принципов отличает новичка от инженера, способного построить надежную платформу.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
8 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Референсные ссылки
-
[Apache Kafka Documentation] (https://kafka.apache.org/documentation/)
-
[Google Cloud: Dataflow & Beam Model] (https://cloud.google.com/dataflow/docs/concepts/beam-programming-model)
-
[Enterprise Integration Patterns] (https://www.enterpriseintegrationpatterns.com/)
-
[The Reactive Manifesto] (https://www.reactivemanifesto.org/)