Практическая демонстрация потокового SQL-конвейера, который преобразует данные, потребленные из Apache Kafka, и записывает результаты в Elasticsearch, используя Debezium-коннекторы и задания Apache Flink в облачной платформе Decodable. Потребление сообщений из Apache Kafka Я уже показывала пример интеграции Apache Kafka и Elasticsearch с помощью sink-коннектора, а также конвейер с ClickHouse Cloud. Сегодня...
Как Greenplum хранит и обрабатывает XML-документы, зачем для этого нужны утилиты gpfdist и gpload, каковы их конфигурации для выполнения XSLT-преобразований XML-файлов и их загрузки/выборки во внешние таблицы MPP-СУБД. Работа с XML-документами и XSLT-преобразования в Greenplum Greenplum, как и PostgreSQL, также поддерживает работу со сложными типами данных и может вести себя...

Чем полезна интеграция ClickHouse с Apache Airflow и как ее реализовать: операторы в пакете провайдера и плагине на основе Python-драйвера. Принципы работы и примеры использования. 2 способа интеграции ClickHouse с AirFlow Продолжая разговор про интеграцию ClickHouse с другими системами, сегодня рассмотрим, как связать эту колоночную СУБД с мощным ETL-движком Apache...
От чего зависит задержка передачи данных из Apache Kafka в ClickHouse, как ее определить и ускорить интеграцию брокера сообщений с колоночной СУБД: настройки и лучшие практики. Интеграция ClickHouse с Kafka Чтобы связать ClickHouse с внешними системами, в этой колоночной СУБД есть специальные механизмы – интеграционные движки таблиц. Например, для взаимодействия...
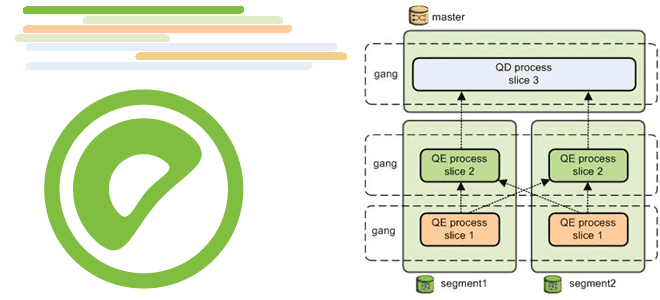
Как координатор Greenplum на мастер-хосте рассылает сегментам планы выполнения запросов, что такое курсор параллельного получения результатов оператора SELECT и каким образом его использовать для аналитики больших данных в этой MPP-СУБД. Особенности рассылки планов SQL-запросов в Greenplum на выполнение Хотя Greenplum основана на PostgreSQL, некоторые механизмы работы этих СУБД отличаются. Например,...
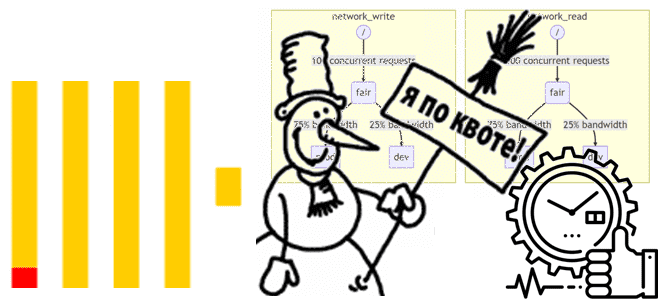
Как эффективно распределять и использовать ресурсы ClickHouse, зачем ограничивать возможности пользователей с помощью квот и классифицировать рабочие нагрузки. Управление ресурсами в ClickHouse Благодаря своей децентрализованной архитектуре ClickHouse, когда один экземпляр включает несколько серверов, к которым напрямую приходят запросы пользователей, эта колоночная СУБД работает очень быстро. Для репликации данных и выполнения...

Чем кэширование в OLAP-системах отличается от OLTP и как устроен кэш запросов ClickHouse: принципы работы, конфигурационные настройки и примеры использования SELECT-оператора. Особенности кэширования в ClickHouse Кэширование является одним из методов повышения производительности, который сокращает время на получение результатов вычислений за счет их хранения в области быстрого доступа. Обычно кэшируются результаты...
Как с Apache Flink настроить локальную службу OLAP, а также развернуть ее в рабочей среде производственного кластера: архитектура, принципы работы и параметры конфигурации для сложных аналитических сценариев. Служба Flink OLAP: архитектура и принципы работы Идея выделить в Apache Flink механизм OLAP для анализа данных в потоковом хранилище появилась еще год...
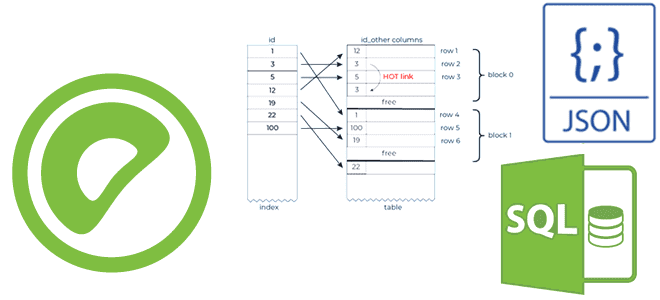
Как Greenplum индексирует JSON-документы, что такое GIN-индекс в PostgreSQL, чем он отличается от B-дерева и хэш-таблицы, когда и как их использовать, а также почему поддерживается только индексация JSONB-полей. Как Greenplum индексирует JSONB-документы Поскольку Greenplum основана на PostgreSQL, она также поддерживает работу со сложными типами данных и может вести себя подобно...

30 апреля 2024 года опубликован очередной выпуск ClickHouse, который включает 13 новых функций, 16 улучшений производительности и 65 исправлений ошибок. Знакомимся с самими интересными новинками релиза 24.4. Значимые новинки Clickhouse 24.2 Начнем с повседневных операций с таблицами: теперь в ClickHouse можно зараз удалить несколько таблиц со всем их содержимым, используя...
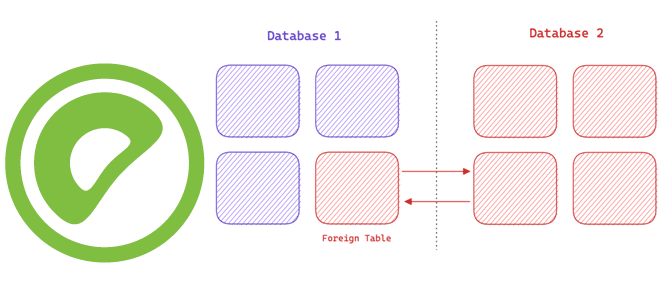
Чем внешняя таблица Greenplum отличается от сторонней, и как они преобразуются друг в друга: организация доступа к данным вне базы, FDW-обертки и протоколы для интеграции MPP-СУБД с другими источниками информации. Сторонняя таблица в Greenplum Термины внешняя (external) и сторонняя (foreign) table похожи, но нюансы их использования в Greenplum отличаются. Такие...
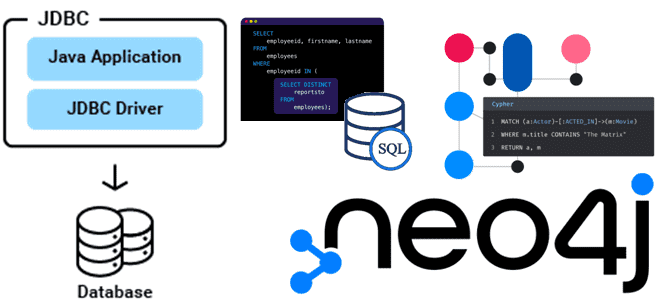
Что не так с общим Java-драйвером Neo4j, зачем нужен JDBC-драйвер, какие функции он поддерживает, а что не позволяет разработчику делать с этой графовой базой данных. Что не так с общим Java-драйвером Neo4j и зачем нужен JDBC-драйвер 25 марта 2024 года вышла 6-я версия драйвера JDBC для графовой СУБД Neo4j, поддерживаемого...
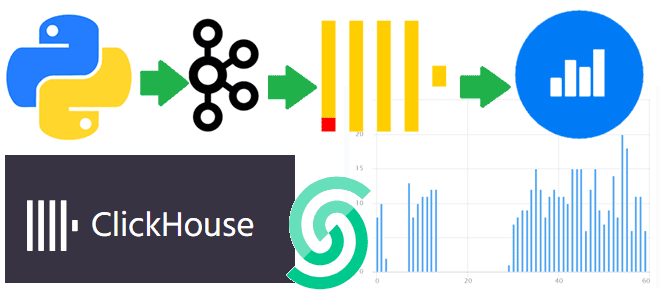
Как связать ClickHouse с Apache Kafka: примеры проектирования и реализации онлайн-аналитики с использованием облачного сервиса колоночной СУБД, брокера сообщений и BI-системы Яндекса. Постановка задачи и проектирование потокового конвейера Для взаимодействия с внешними хранилищами ClickHouse использует специальные механизмы – интеграционные движки таблиц. Вчера я показывала пример интеграции ClickHouse со встроенной key-value...

Сегодня разберем, как из ClickHouse обратиться к встроенной key-value БД RockDB, используя табличный движок EmbeddedRocksDB, и познакомимся с возможностями новой песочницы колоночной базы данных. Постановка задачи и DDL-скрипты Колоночная СУБД ClickHouse поддерживает несколько движков таблиц, включая интеграционные механизмы для взаимодействия со сторонними системами, одной из которых является key-value база данных...
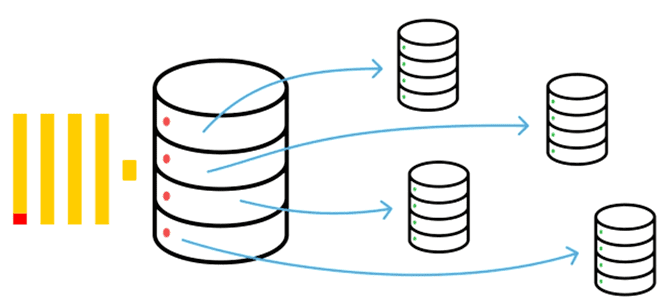
Как повысить производительность ClickHouse с помощью горизонтального масштабирования, разделив данные на шарды: принципы шардирования, стратегии выбора ключа, особенности работы с distributed-таблицами и настройки конфигураций сервера. Шардирование в ClickHouse Именно хранилище данных всегда является узким местом любой системы. Поэтому именно его надо расширить для повышения производительности. Это можно сделать с помощью...
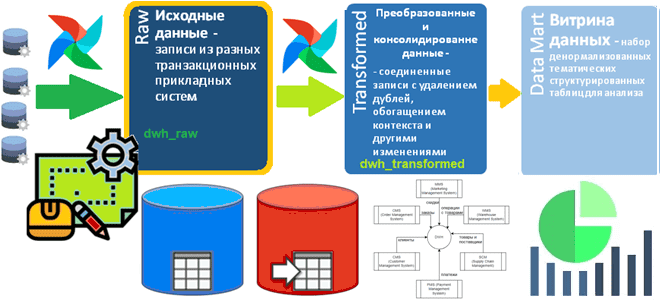
Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных. Постановка задачи: анализ систем-источников Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на...
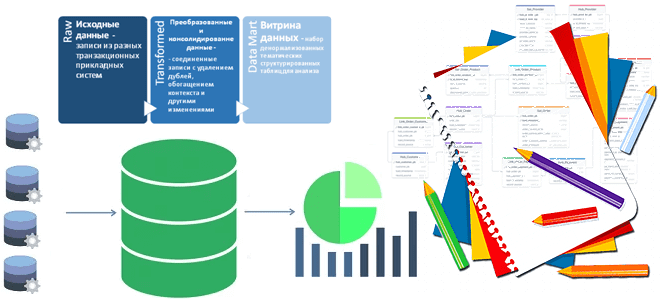
Как построить хранилище данных с подходом Data Vault: пример проектирования схемы данных и разработка DDL-скрипта для Transformed-слоя DWH интернет-магазина. Слоистая структура DWH и подход Data Vault Корпоративное хранилище данных (DWH, Data Warehouse) часто бывает гетерогенным, т.к. организованным с помощью нескольких баз данных, связанных ETL-процессами. Согласно концепции слоистой архитектуры (LSA, Layered...

Что такое гонка данных, почему она опасна в ETL-заданиях и как ее избежать: зачем разделять задания репликации в RAW-слой хранилища от их преобразования и сохранения в Transformed-слое DWH перед созданием витрин данных для BI-приложений. Что такое гонка данных в дата-инженерии Одна из главных особенностей распределенных систем – это задержка между...

Как найти зависший процесс в базе данных Greenplum, создать резервную копию каталога, разделить лог-файл по тестам и проверить его на наличие повреждений. Знакомимся с набором утилит gpsupport. 6 инструментов утилиты gpsupport для техподдержки Greenplum Как и любая крупная система Greenplum, помимо компонентов, обеспечивающих ее ключевые функции, также включает дополнительные инструменты,...

Как с помощью Flink SQL организовать потоковую агрегацию данных из таблицы PostgreSQL: знакомство с API таблиц в Ververica Cloud на практическом примере. API таблиц Ververica Cloud: создаем внешние источники и приемники данных Как я недавно рассказывала, немецкая фирма Ververica создала высокопроизводительный облачный сервис для обработки данных в реальном времени на...