Что такое внешние веб-таблицы, зачем они нужны, чем отличаются от обычных external tables и как создать такую таблицу в Greenplum на основе команд и на основе URL. Зачем нужны внешние веб-таблицы в Greenplum О том, что в Greenplum есть внешние (external) и сторонние (foreign) таблицы, которые обеспечивают доступ к данным,...

2 августа 2024 года вышел свежий релиз Apache Flink. Знакомимся с главными новинками выпуска 1.20 для упрощения потоковой обработки данных в мощных управляемых конвейерах: новые материализованные таблицы, единый механизм слияния файлов для контрольных точек, улучшения DataStream API и пакетных операций. Улучшения Flink SQL Начнем с новинок Flink SQL, одной из...
Почему пользовательские функции лучше применять как можно реже, каковы их возможности и ограничения: краткий обзор особенностей разработки и эксплуатации UDF в Apache Spark SQL, ksqlDB, Flink SQL, Greenplum и ClickHouse. Чем полезны и опасны пользовательские функции в обработке больших данных? Пользовательские функции (User-Defined Functions, UDF) позволяют разработчику расширить возможности фреймворка,...

Как расширить возможности ksqlDB, реализовав пользовательскую функцию обработки данных, хранящихся в топиках Kafka, с помощью SQL-запросов: ликбез по UDF и практический пример. Пользовательские функции в ksqlDB для работы с данными в топиках Apache Kafka Поскольку Apache Kafka – то не просто брокер сообщений, а целая экосистема потоковой передачи событий, вокруг...

Новая логика дедупликации данных, ограничения работы с матпредставлениями, дополнительные SQL-функции и улучшения производительности ClickHouse 24.7: краткий обзор ключевых особенностей июльского выпуска. Несовместимые изменения и новые фичи 30 июля 2024 года вышел очередной релиз ClickHouse, в котором довольно много изменений, несовместимых с прошлыми версиями. В частности, в реплицированных базах данных теперь...
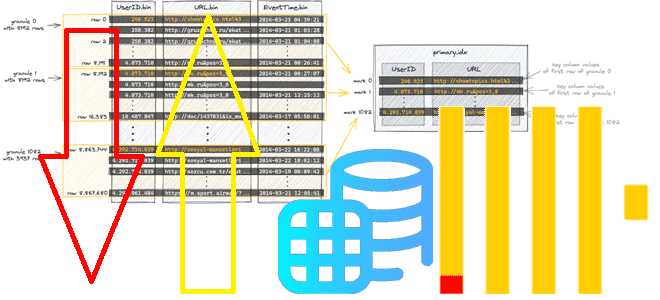
Зачем в ClickHouse 24.6 добавлена настройка optimize_row_order для оптимизации порядка строк MergeTree-таблиц, как она работает и где ее применять. Как связаны индексация и сортировка таблиц в ClickHouse Даже не будучи классической реляционной СУБД, ClickHouse поддерживает индексацию, насколько это возможно в его колоночной природе, индексируя первичным ключом целую группу строк (гранулу)...
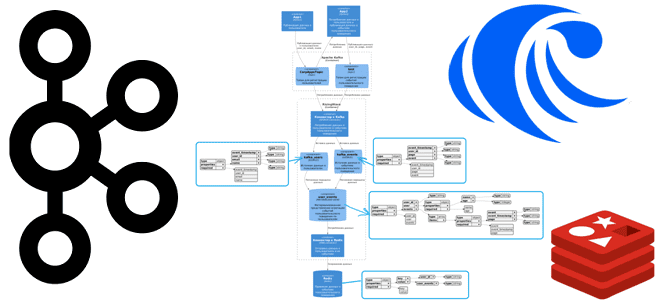
Как SQL-запросами соединить потоки из разных топиков Apache Kafka и отправить результаты в Redis: демонстрация ETL-конвейера на материализованных представлениях в RisingWave. Постановка задачи и проектирование потоковой системы Продолжая недавний пример потоковой агрегации данных из разных топиков Kafka с помощью SQL-запросов, сегодня расширим потоковый конвейер в RisingWave, добавив приемник данных –...
Как соединить данные из разных топиков Apache Kafka с помощью пары SQL-запросов: коннекторы, материализованные представления и потоковая база данных вместо полноценного потребителя. Подробная демонстрация запросов в RisingWave. Проектирование и реализация потоковой агрегации данных из Kafka в RisingWave Вчера я показывала пример потоковой агрегации данных из разных топиков Kafka с помощью...

20 июня 2024 года вышел очередной релиз Greenplum. Разбираемся с ключевыми новинками выпуска 7.2: сканирование индекса в AO-таблицах, изменения в оптимизаторе GPORCA, улучшенная обработка геопространственных данных и новая служба централизованного управления сегментами Postmaster. Новинки Greenplum 7.2 для дата-инженера Начнем с изменений, повышающих производительность Greenplum. Одним из них стало сканирование индекса...
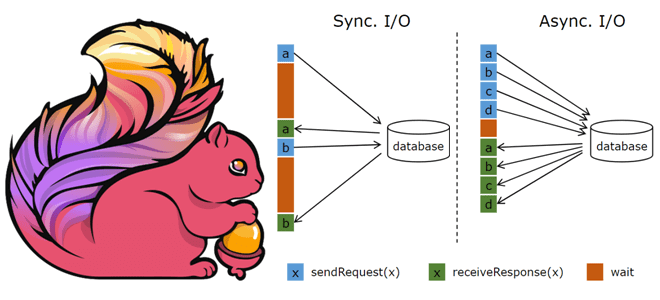
API асинхронного ввода-вывода в Apache Flink и как его использовать для асинхронной интеграции данных из внешней системы с потоком событий. Основы асинхронной обработки в Apache Flink Обогащение потоков данных информацией из внешних систем является довольно сложным кейсом из-за необходимости синхронизировать скорость поступления событий с задержкой доступа к внешнему источнику. При...
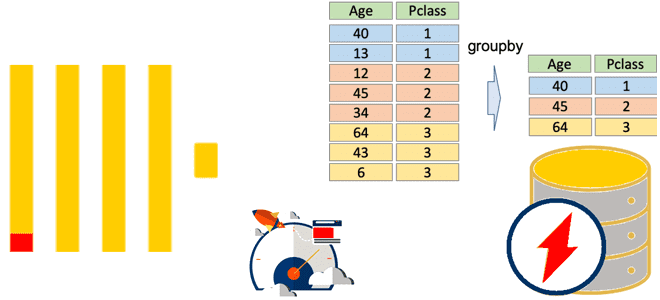
Как работают агрегатные функции в ClickHouse, почему SQL-запросы с GROUP BY потребляют много памяти и что поможет сделать их быстрее и эффективнее: лайфхаки многопоточной агрегации в колоночной базе данных. Особенности выполнения оператора GROUP BY в ClickHouse Агрегатные функции позволяют вычислить экстремум (минимум/максимум), среднее значение, количество, сумму или другое результирующее значение...
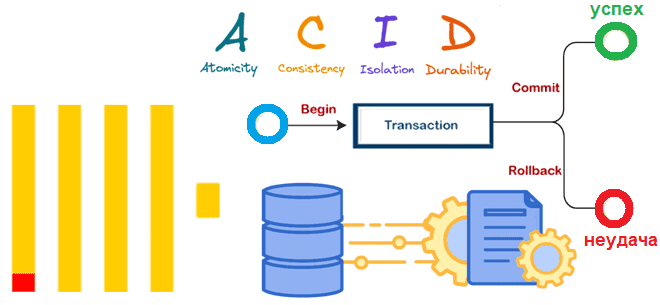
Почему в ClickHouse нет полноценных транзакций, но введена экспериментальная поддержка ACID для операций вставки в таблицы движка MergeTree, как это реализуется и чем синхронная вставка отличается от асинхронной. Особенности операций вставки в ClickHouse В ClickHouse нет полноценных транзакций, поскольку это колоночное хранилище в первую очередь ориентировано на чтение большого объема...
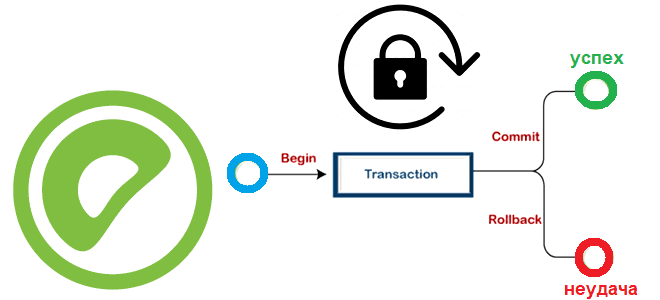
Какие SQL-команды есть в Greenplum для транзакционной обработки данных, как MVCC исключает явные блокировки, можно ли установить их вручную и как это сделать: режимы блокировки и глобальный детектор взаимоблокировок в MPP-СУБД. Транзакции, MVCC и режимы блокировки Greenplum Про изоляцию транзакций в Greenplum и Arenadata DB мы уже писали здесь. Транзакции...

Почему потоковый сервер Greenplum выгружает данные во внешние системы пакетно: тонкости утилиты gpfdist и YAML-файла конфигурации выгрузки. Возможности и ограничения GPSS-сервера при выгрузке данных во внешние системы из MPP-СУБД. Потоковый сервер Greenplum Ключевым отличием Greenplum от PostgreSQL является поддержка механизма массово-параллельной обработки, благодаря чему эта MPP-СУБД относится к стеку Big...
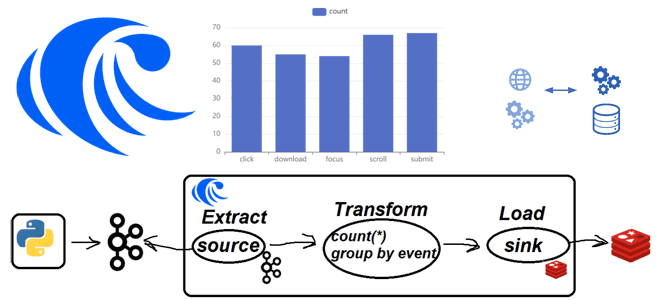
Практическая демонстрация потоковой агрегации событий пользовательского поведений из Apache Kafka с записью результатов в Redis на платформе RisingWave: примеры Python-кода и конвейера из SQL-инструкций. Постановка задачи Одной из ярких тенденций в современном стеке Big Data сегодня стали платформы данных, которые позволяют интегрировать разные системы между собой, поддерживая как пакетную, так...
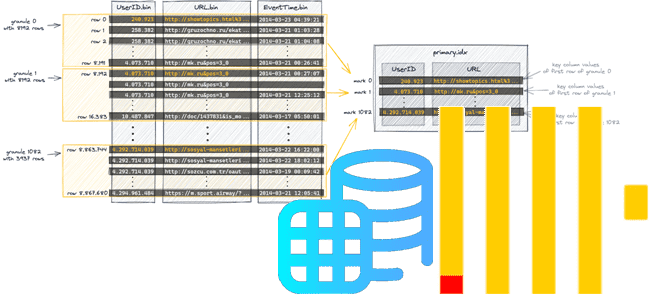
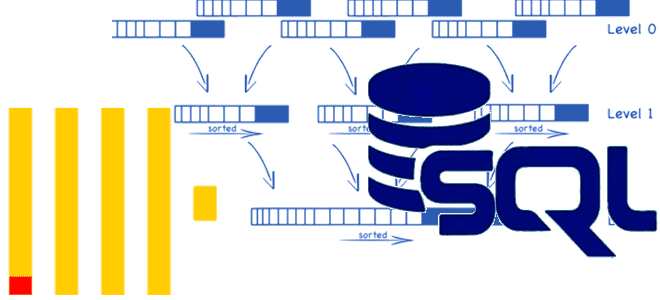
Как ClickHouse реализует разреженные индексы, что такое гранула, чем отличается широкий формат хранения данных от компактного, и почему значения первичного ключа в диапазоне параметров запроса должны быть монотонной последовательностью. Тонкости индексации в ClickHouse Индексация считается одним из наиболее известных способов повышения производительности базы данных. Индекс определяет соответствие значения ключа записи...
Что такое модификатор FINAL в SELECT-запросе ClickHouse, с какими табличными движками он работает, почему снижает производительность и как этого избежать. Тонкости потокового выполнения SQL-запросов в колоночной СУБД. Зачем в SELECT-запросе ClickHouse нужен модификатор FINAL? Хотя SQL-запросы в ClickHouse имеют типовую структуру, их реализация зависит от используемого движка таблиц. Например, запрос...
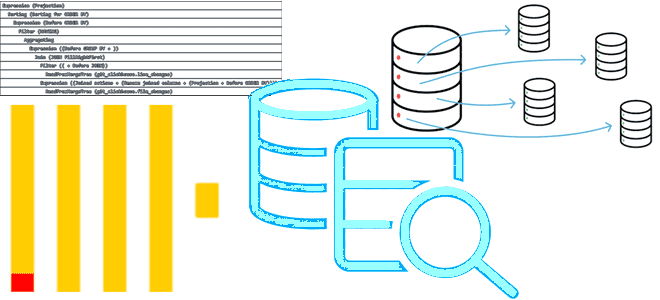
Как равномерно распределить по шардам ClickHouse уже существующие данные, зачем профилировать запросы, какие профилировщики поддерживает эта колоночная СУБД и каким образом их использовать. Ребалансировка шардов в ClickHouse Какой бы быстрой не была база данных, ее работу всегда хочется ускорить еще больше. Одним из популярных способов ускорения распределенной СУБД является шардирование...

Как прочитать данные из ClickHouse в Apache NiFi или загрузить их в таблицу колоночной СУБД: настройки подключения, использование процессоров и тонкости потоковой интеграции. Подключение к ClickHouse из Apache NiFi Как и интеграция ClickHouse с Apache AirFlow, связь этой колоночной СУБД с приложением NiFi реализуется с помощью решения сообщества, средствами самого...
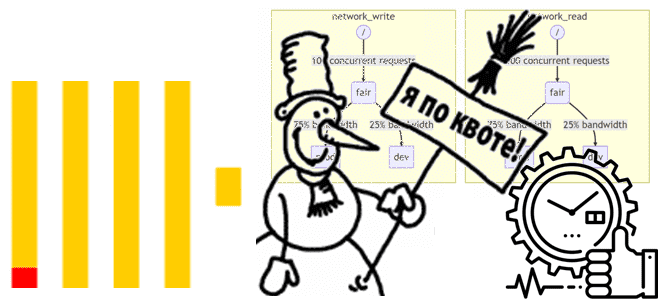
Как эффективно распределять и использовать ресурсы ClickHouse, зачем ограничивать возможности пользователей с помощью квот и классифицировать рабочие нагрузки. Управление ресурсами в ClickHouse Благодаря своей децентрализованной архитектуре ClickHouse, когда один экземпляр включает несколько серверов, к которым напрямую приходят запросы пользователей, эта колоночная СУБД работает очень быстро. Для репликации данных и выполнения...