
Python считается из основных языков программирования в областях Data Science и Big Data, поэтому не удивительно, что Apache Spark предлагает интерфейс и для него. Data Scientist’ы, которые знают Python, могут запросто производить параллельные вычисления с PySpark. Читайте в нашей статье об инициализации Spark-приложения в Python, различии между Pandas и PySpark,...
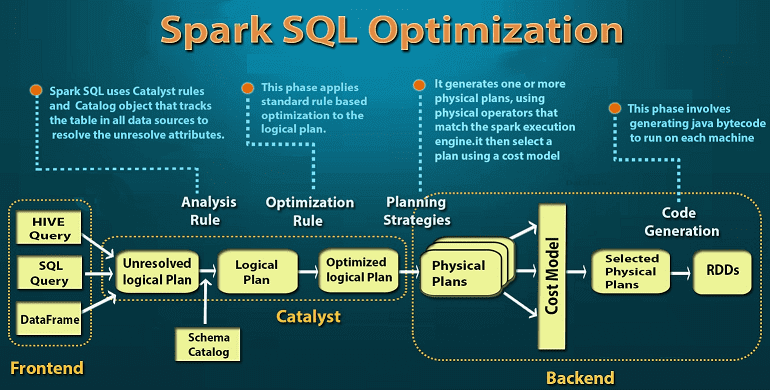
Завершая тему SQL-оптимизации в Big Data на примере Apache Spark, сегодня мы подробнее расскажем, какие действия выполняются на каждом этапе преобразования дерева запросов в исполняемый код. А рассмотрим, за счет чего так эффективна автоматическая кодогенерация в Catalyst. Читайте в нашей статье про планы выполнения запросов, квазиквоты Scala и операции с...
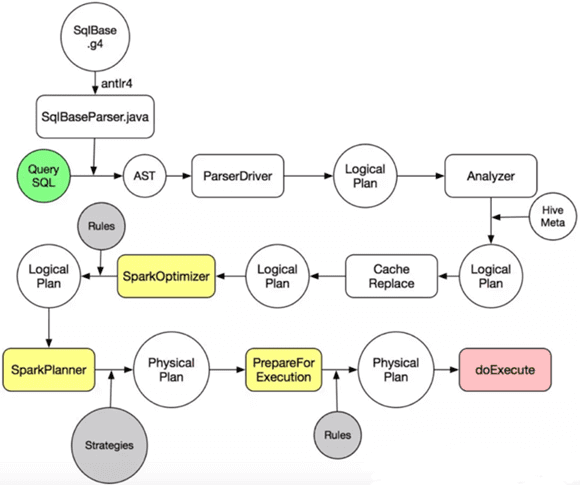
Продолжая разговор про SQL-оптимизацию в Apache Spark, сегодня мы рассмотрим, что такое дерево запросов и как оптимизатор Catalyst преобразует его в исполняемый байт-код при аналитической обработке Big Data в рамках Спарк. Деревья структурированных запросов и правила управления ими в Apache Spark Отметим, что деревья запросов отличаются от алгебраических деревьев операций тем, что...
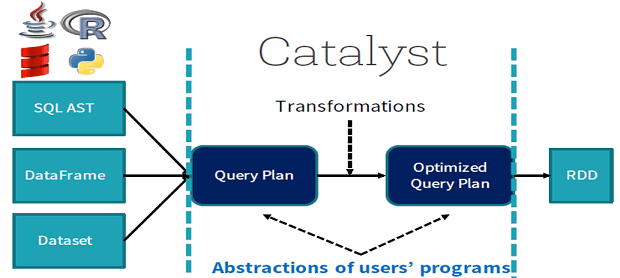
Мы уже немного рассказывали об SQL-оптимизации в Apache Spark. Продолжая эту тему, сегодня рассмотрим подробнее, что такое Catalyst – встроенный оптимизатор структурированных запросов в Spark SQL, а также поговорим про базовые понятия SQL-оптимизации. Читайте в нашей статье о логической и физической оптимизации, плане выполнения запросов и зачем эти концепции нужны...
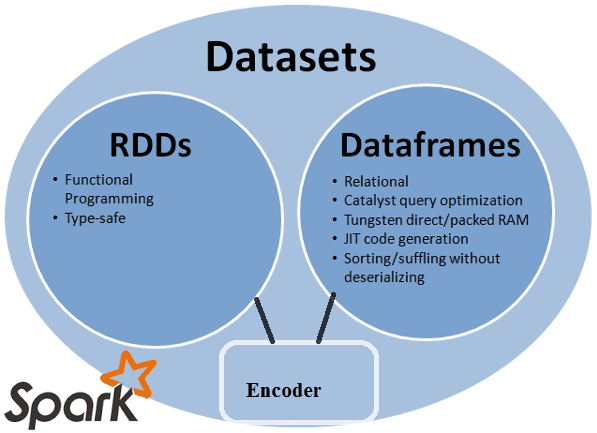
В прошлый раз мы рассмотрели понятия датафрейм (DataFrame), датасет (DataSet) и RDD в контексте интерактивной аналитики больших данных (Big Data) с помощью Spark SQL. Сегодня поговорим подробнее, чем отличаются эти структуры данных, сравнив их по разным характеристикам: от времени возникновения до специфики вычислений. Критерии сравнения структур данных Apache Spark Прежде...
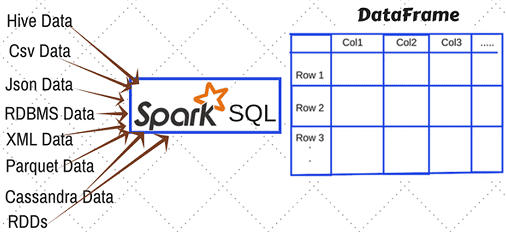
Этой статьей мы открываем цикл публикаций по аналитике больших данных (Big Data) с помощью SQL-инструментов: Apache Impala, Spark SQL, KSQL, Drill, Phoenix и других средств работы с реляционными базами данных и нереляционными хранилищами информации. Начнем со Spark SQL: сегодня мы рассмотрим, какие структуры данных можно анализировать с его помощью и...