
Специально для обучения начинающих аналитиков данных и дата-инженеров сегодня рассмотрим примеры выполнения простых SQL-запросов и оконных функций в Apache Spark на Google Colab. Как быстро проанализировать датафрейм из CSV-файлов с помощью нескольких строк на PySpark. Запуск и использование PySpark в Google Colab Предположим, необходимо определить потенциальный доход от проведения обучающих...
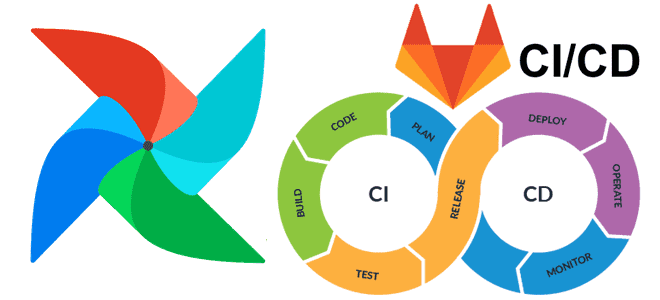
Интеграция Apache Airflow с инструментами CI/CD является одной из лучших практик современной дата-инженерии, о чем мы недавно писали. Читайте далее, зачем нужно управлять кодом DAG с помощью популярных систем управления версиями и как это сделать на примере GitLab CI/CD. Сложности управления DAG в разных средах AirFlow Apache Airflow считается наиболее...

В продолжение недавней статьи для дата-инженеров по эффективной работе с Apache AirFlow, сегодня разберем еще несколько рекомендаций от компании Astronomer, которая продвигает и коммерциализирует этот ETL-оркестратор. Чем полезна микрооркестрация с несколькими средами AirFlow, как обеспечить повторное использование и воспроизводимость, зачем нужна интеграция с инструментами и процессами CI/CD. Микрооркестрация с множеством...
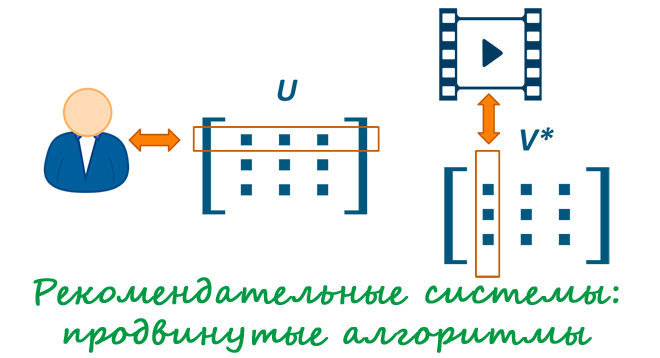
В прошлой статье мы разобрали методы построения рекомендательных систем: коллаборативная фильтрация; фильтрация на контенте; фильтрация на знаниях; гибридный подход. Мы намеренно не упомянули об одном важном подходе построения рекомендаций: об использовании матричных разложений. Описание данного метода заслуживает отдельной статьи! Будем эксплуатировать традиционный для рекомендательных систем кейс рекомендации фильмов пользователям. Напомним,...
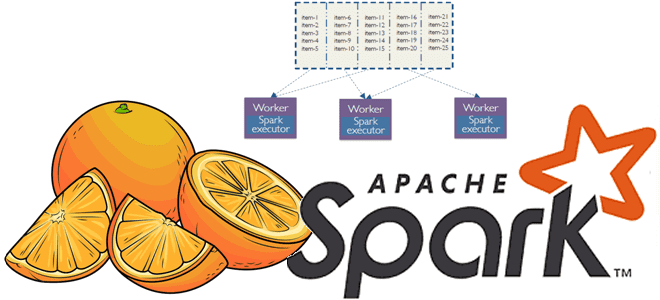
Мы уже рассказывали про функции перераспределения данных по разделам coalesce() и repartition(). Сегодня сравним их работу с еще одним методом управления разделами в Apache Spark и разберем, как все они могут помочь дата-инженеру и разработчику распределенных приложений повысить эффективность этого популярного фреймворка аналитики больших данных. Отобрать и поделить: лучшие практики партиционирования данных...

Сегодня рассмотрим несколько рекомендаций по построению масштабной и устойчивой экосистемы интеграции корпоративных данных на базе Apache AirFlow от компании Astronomer, которая активно способствует продвижению и коммерциализации этого популярного инструмента дата-инженерии. Как организовать эффективную маршрутизацию рабочих процессов с пакетным ETL-оркестратором: 3 лучших практики. Стандартизация сред разработки и промышленной эксплуатации с Kubernetes...
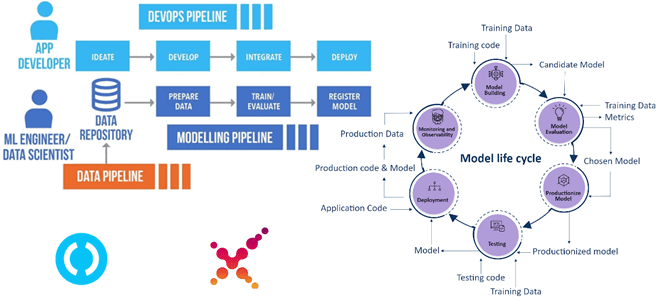
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка...
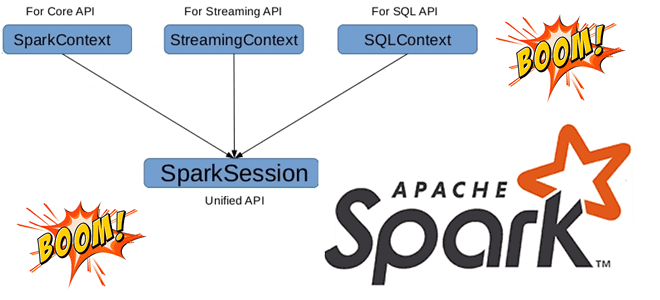
Может ли быть несколько сеансов в одном Spark-приложении с разной конфигурацией, зачем нужен метод foreachBatch() в структурированной потоковой передаче и чем он отличается от foreach(), почему возникает ошибка Table or view not found: microBatch и как ее обойти. В рамках обучения разработчиков Apache Spark и дата-инженеров заглядываем под капот этого...

Почему следует избегать PythonOperator в конвейере обработки пакетных данных на Apache Airflow и что использовать вместо этого оператора для описания задач DAG. Когда лаконичный CLI лучше наглядного GUI, где и как применять библиотеку Python Fire для оркестрации, а также планирования запуска batch-заданий. Зачем нам CLI или что не так с PythonOperator...

Практически на каждом маркетплейсе есть раздел с рекомендованными товарами, фильмами, объявлениями и т.д. Сервисы аудиокниг предлагают пользователям обратить внимание на определенные аудиокниги, которые выбираются исходя из предпочтений пользователя. Площадки с объявлениями стремятся показать наиболее интересные для пользователя объявления в разделе рекомендаций. Примеры есть практически на каждом интернет ресурсе. Давайте разберемся...
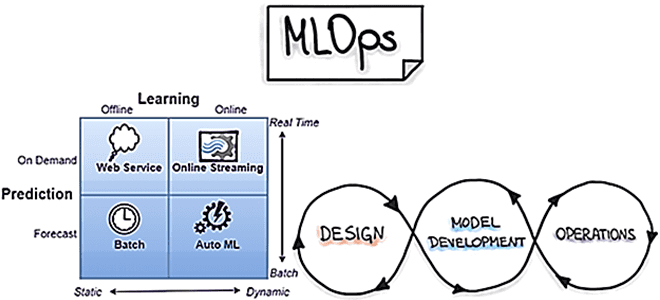
Сегодня рассмотрим наиболее распространенные в MLOps стратегии развертывания, т.е. подходы к внедрению моделей машинного обучения в производство. Выбор стратегии зависит от бизнес-требований и от контекста применения результатов ML-моделирования. Какие бывают стратегии и как они реализуются: краткий ликбез с примерами для ML-инженеров и MLOps-специалистов. Пакетное прогнозирование и веб-сервисы для MLOps Это...
В этой статье для дата-инженеров и аналитиков данных, рассмотрим, что такое широковещательные соединение в Apache Spark SQL, чем оно полезно и как работает на практических примерах. BROADCAST JOIN в SELECT-запросах Spark SQL, а также краткий ликбез по подсказкам или хинтам. Что такое широковещательное соединение в Apache Spark SQL Распределенная природа...

Сегодня разберем опыт австралийской ИТ-компании hipages по построению самообслуживаемого ETL-конвейера с Apache Airflow и Amazon Athena, призванного обеспечить высокое качество данных и облегчить дата-инженерам управление информационными активами. Изящное решение сложных проблем управления данными с примерами SQL-запросов к корпоративному Data Lake на AWS S3. Что не так с монолитной архитектурой платформы данных...

В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, как повысить эффективность выполнения Python-кода с помощью кросс-языковой платформы Apache Arrow. Что такое PyArrow и как это улучшает производительность PySpark-программ. Почему Spark Java быстрее PySpark и как это исправить с Apache Arrow Будучи популярным вычислительным движком в области Big Data, Apache...

Постоянно добавляя в наши курсы по Apache Spark и машинному обучению практические примеры для эффективного повышения квалификации Data Scientist’ов и инженеров данных, сегодня рассмотрим задачу пакетного прогнозирования и планирование ее запуска по расписанию без применения масштабных MLOps-решений. Apache Spark для пакетного прогнозирования Есть много готовых решений и инструментов для пакетного...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...
Иногда в распределенных системах требуется строгий порядок событий, т.е. сообщений или записей с полезными данными и состоянием, который должен поддерживаться между продюсерами и потребителями в конвейере их обработки. Например, чтобы сохранить корректный порядок транзакций для правильного расчета остатков по счетам. Читайте далее, как это реализовать в Apache Kafka. Настройка продюсера...
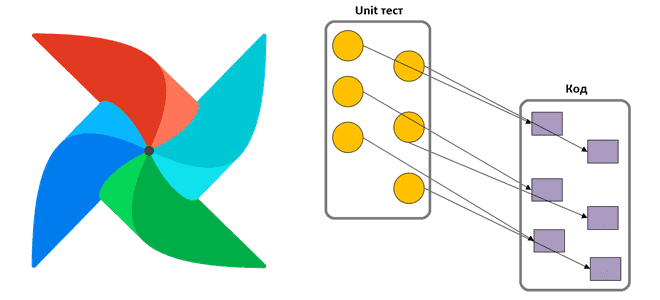
Благодаря возможности написать собственный Python-код для операторов и задач DAG’ов, Apache Airflow позволяет разработчикам Data Flow и инженерам данных создавать сложные и эффективные конвейеры пакетной обработки данных. Обеспечить надежность этого многообразия поможет качественное тестирование пользовательского кода. Рассмотрим примеры и рекомендации по написанию модульных тестов. Зачем тестировать DAG AirFlow? Модульные тесты...

Практический пример аналитики больших данных в реальном времени с Apache Spark, Kafka, ClickHouse и AWS S3: возможности, архитектура, также специально для дата-инженеров и разработчиков распределенных приложений рассмотрим, сколько времени нужно для разрешения каждого вызова API в определенном временном диапазоне. Анализ событий пользовательского поведения в реальном времени Основным продуктом международной ИТ-компании...
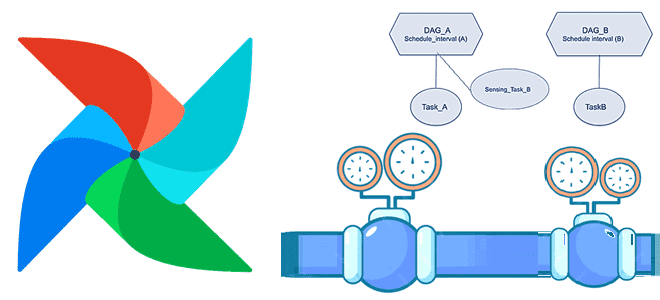
Мы уже писали про датчики или сенсоры - особый тип операторов Apache AirFlow, предназначенных для ожидания какого-то события. Сегодня рассмотрим практический пример обучения дата-инженеров и разработчиков по использованию внешнего сенсора в рамках типовой задачи дата-инженерии по организации ETL/ELT-процессов при поэтапной загрузке данных в DWH для OLAP-систем. Постановка задачи: поэтапная загрузка...