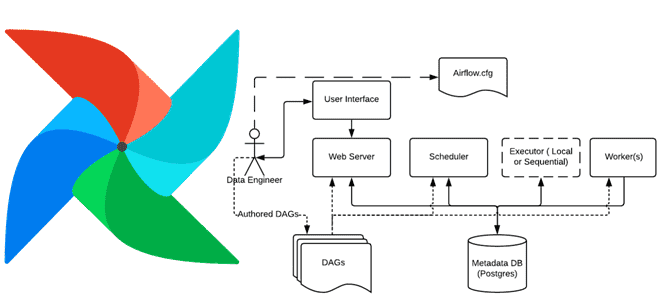
Сегодня рассмотрим, как в Apache AirFlow реализуется обмен данными между задачами с использованием технологии XCom. Чем хорош XCom и почему его не стоит использовать для передачи больших объемов данных: практика организации ETL-конвейеров для дата-инженера. Что такое XCom и зачем это в Apache AirFlow Apache AirFlow не зря является одним из...
Практически каждый Python-разработчик и Data Scientist использует в своем коде сторонние библиотеки и внешние решения, которые хранятся в разных репозиториях и связаны со множеством других файлов. Этот открытый код настолько распределен, что возникает «ад зависимостей», что сильно осложняет разработку. Читайте, как справиться с этой проблемой, используя методы анализа графов. Проблема...

Как повысить качество данных и пакетных конвейеров с их обработки в Apache AirFlow с Python-библиотекой Whylogs. Что это за средство регистрации и профилирования, как оно работает, каким образом совместимо с DAG-графом задач Apache AirFlow и чем полезно дата-инженеру. Что такое Whylogs и зачем это Apache AirFlow Apache AirFlow активно используется...
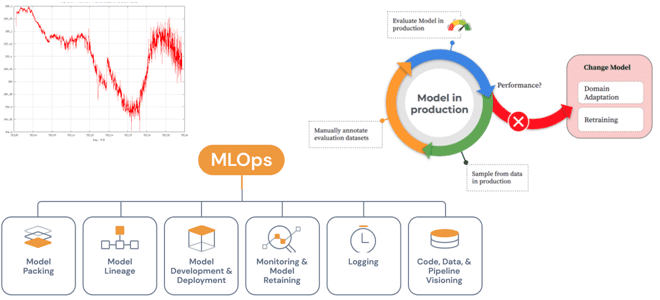
Специально для обучения ML-разработчиков сегодня разберем проблемы развертывания моделей Machine Learning в производстве и способы их решения с помощью MLOps-инструментов. А также поговорим про дрейф данных и его обнаружение методами математической статистики. Жизненный цикл ML-моделей и MLOps Каждый проект машинного обучения начинается с данных, подготовка которых занимает большую часть жизненного...
Мы уже писали о Python-клиентах Apache Kafka, которые позволяют разрабатывать приложения потоковой передачи события, используя популярный Python вместо сложных языков Java и Scala. Сегодня познакомимся с еще одной Python-библиотекой, которая представляет асинхронный клиент для Kafka. Что такое aiokafka и чем это отличается от kafka-python: краткий обзор для обучения инженеров данных...

Сегодня рассмотрим тему анализа и оптимизации бизнес-процессов средствами графовой аналитики больших данных. Как устроены информационные системы класса Process Mining, где еще применяются эти идеи и другие приложения теории графов в бизнесе на примере Python-библиотеки PM4Py. Что такое Process Mining Чтобы понять, как выполняется процесс, бизнес-аналитик строит его схему в виде подробной EPC...
Мы уже рассказывали про важность переносимости ML-моделей, что является одним из аспектов MLOps-концепции. Сегодня разберем, почему популярный формат Pickle не лучший выбор для сохранения модели Machine Learning и что использовать вместо него. Пара достоинств и 7 главных недостатков формата Pickle Согласно концепции MLOps, направленной на сокращение разрыва между различными специалистами,...

Чтобы добавить в наши практические курсы по Apache Spark еще больше приемов, полезных для дата-инженеров и разработчиков, сегодня рассмотрим, как упаковать PySpark-приложение, используя нативные Python-функции и сторонние решения. Отличия Virtualenv от PEX и Conda. 4 способа упаковать PySpark-приложение для запуска в кластере Apache Spark Разработчики распределенных приложений знают, что недостаточно...
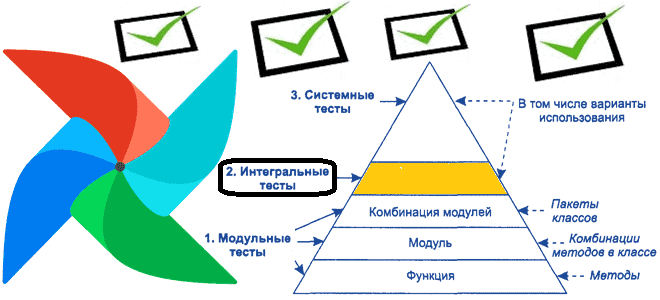
Продолжая тему тестирования DAG в Apache Airflow, сегодня рассмотрим следующий этап проверки качества ПО – разработку интеграционных тестов. Разберемся, как при этом дата-инженер может использовать Docker Compose и Pytest, а также познакомимся с возможностями REST API самого популярного в Big Data batch-оркестратора. Идеи и инструменты интеграционного тестирования DAG в Apache...
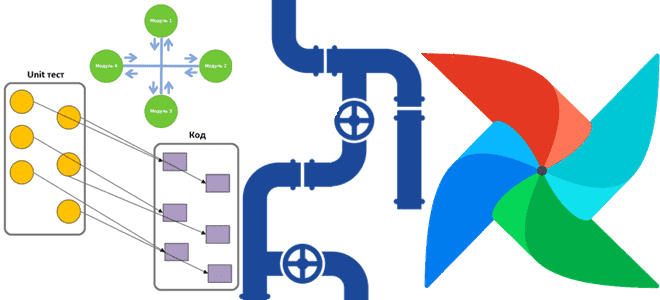
Мы уже писали про важность модульного тестирования DAG Apache Airflow, а также лучшие практики и инструменты реализации этого процесса. Как протестировать структуру DAG со сложной условной логикой, сделав тест детерминированным с помощью простой сортировки идентификаторов задач, а также каким образом дата-инженеру помогут шаблоны Jinja. Проверка структуры DAG в AirFlow С...
Чтобы добавить в наши курсы для дата-инженеров и специалистов по Machine Learning еще больше практических примеров, сегодня рассмотрим, как построить ETL-конвейер для преобразования речи в текст с использованием Apache Kafka, Airflow и Spark. А также познакомимся с популярными фреймворками и готовыми сервисами распознавания речи. ETL-конвейер распознавания речи: используемые технологии Предположим,...

Сегодня в рамках обучения дата-инженеров разберем, как организовать логическое ветвление рабочего процесса в Apache AirFlow с помощью операторов. Какие операторы позволяют организовать условную логику в DAG, чем BranchPythonOperator отличается от ShortCircuitOperator, как запустить задачу в зависимости от времени и/или дня недели, а также результата выполнения SQL-запроса. Условная логика в DAG:...

Сегодня разберемся, когда для Data Science-проектов вместо Apache Spark, самого популярного вычислительного движка аналитики больших данных, стоить выбрать Dask – легковесную Python-библиотеку для параллельных вычислений. И, наоборот, в каких случаях инженер данных и Data Scientist получают преимущества, выбирая Spark. Что такое Dask и зачем он нужен Data Scientist’у Прежде чем...

16 июня 2022 года вышла новая версия Apache Spark – 3.3.0. Разбираем главные фичи этого минорного релиза, особенно важные для дата-инженера и разработчика распределенных приложений: от расширения поддержки ANSI SQL до профилирования UDF на Python. Главные изменения Apache Spark 3.3.0 Apache Spark 3.3.0 — это четвертый релиз линейки 3.x, в...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое связность в графе, зачем вычислять компоненты связности и как это сделать для ориентированных графов. Продемонстрируем все вычисления с помощью методов Python-библиотеки Networkx в Google Colab. Основы теории графов и применения Networkx в Google...
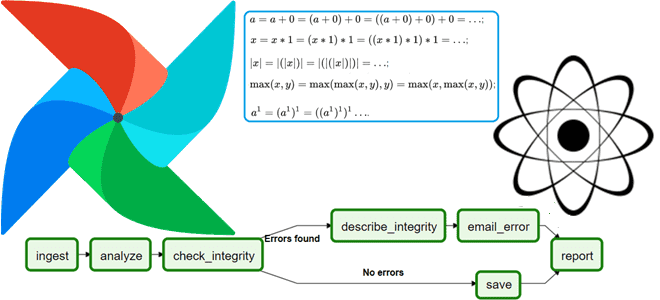
В этой статье для обучения дата-инженеров рассмотрим практическое применение 2-х важных принципов обработки данных: атомарность и идемпотентность задач в Apache Airflow. Читайте далее, как применить их к своим ETL-конвейерам, чтобы получить корректные и согласованные результаты. Все или ничего: атомарность задач Будучи популярным инструментом дата-инженерии, Apache Airflow снижает порог входа в...

Как писать UDF-функции Greenplum на Python: краткий обзор расширения PL/Python для дата-инженера и разработчика распределенных приложений. Как его установить, настроить и использовать: сопоставления типов данных, SQL-запросы, модули и функции. Поддержка Python в MPP-СУБД Поскольку освоить Python намного проще других языков программирования, например, Java или C#, неудивительно, что он сегодня очень...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...

Весна богата на новые релизы: в начале мая 2022 года вышел Apache Flink 1.15. Рассказываем, что нового в свежем выпуске: краткий обзор самых полезных фич для разработчика распределенных приложений, а также интересные изменения, исправления ошибок и улучшения для дата-инженера. Scala под капотом и спецификация REST API по стандарту OpenAPI Apache...

30 апреля 2022 года вышел новый релиз Apache Airflow, который содержит более 700 коммитов с предыдущей версии 2.2.0 и включает 50 новых функций, 99 улучшений, 85 исправлений ошибок и несколько изменений в документации. Разбираемся, что особенно важно для дата-инженера в Apache Airflow 2.3.0. ТОП-7 главных фич Apache AirFlow 2.3.0: краткий...