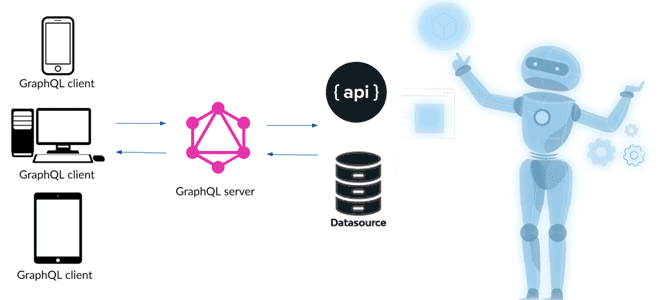
Недавно мы упоминали GraphQL как мощный и гибкий язык запросов к данным, хранящимся в графовых СУБД. Сегодня рассмотрим, чем эта технология может быть полезна в проектах Machine Learning, какие сложности с ней связаны и как их решить с помощью MLOps. GraphQL для ML: возможности и примеры Не будучи в чистом...

28 октября 2022 года вышел мажорный релиз Apache Flink. Что нового в выпуске 1.16.0, который сегодня имеет официальный статус стабильного: зачем нужен SQL Gateway, как улучшен Changelog State Backend, какие DDL-выражения добавлены и зачем внесена поддержка кэширования результата преобразования в PyFlink. Главные обновления Apache Flink 1.16 В версии 1.16 Flink...

В рамках продвижения наших курсов по машинному обучению и Data Science, сегодня познакомимся с полезным инструментом визуализации данных. Что такое RawGraphs, как он работает и чем полезен для аналитики больших данных: смотрим на практическом примере. Что такое RawGraphs и как это работает Специалисты по Data Science и аналитики данных часто...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...

В рамках продвижения наших курсов по Data Science и Machine Learning, сегодня познакомимся с Python-библиотекой spaCy и русскоязычной NLP-моделью, развернув их в интерактивной среде Google Colab. В качестве практического примера решим небольшую SEO-задачу: определим части речи для каждого слова в небольшом тексте и количество их повторений. Применение библиотеки spaCy на...
Сегодня рассмотрим, чем отличаются подходы к представлению данных в глубоком машинном обучении и реляционной логике, как это связано с декларативной парадигмой логического программирования и при чем здесь графы. А в качестве примера реализации этих идей рассмотрим комбинацию принципов Deep Learning с реляционной логикой и GNN-нейросетями в Python-библиотеке PyNeuraLogic. Машинное обучение...

Сегодня поговорим про Python-библиотеку River, которая позволяет быстро и дешево обновлять модели машинного обучения в производственной среде в режиме реального времени. Чем потоковые ML-конвейеры отличаются от пакетных и с какими сложностями при их реализации может столкнуться Data Scientist. Что такое потоковое машинное обучение Data Scientist’ы обычно используют пакетное обучение для...

Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...

В рамках продвижения нашего нового курса по графовой для аналитики больших данных аналитике больших данных, сегодня познакомимся с клиентской Python-библиотекой Neo4j под названием Py2neo, которая позволяет отказаться от языка запросов Cypher. Читайте далее, что это такое, как работает и где пригодится. Python вместо Cypher в приложениях для Neo4j Манипуляции с...
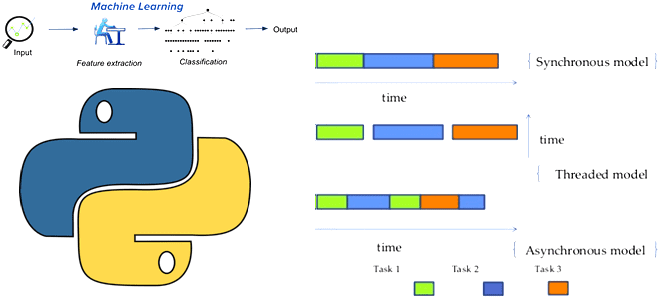
Поскольку концепция MLOps стремится устранить разрывы между разработкой ML-модели и ее имплементацией в эффективный программный код, сегодня поговорим про важную идею программирования, связанную с синхронностью и асинхронностью вызовов. Что такое асинхронное программирования, зачем это нужно в Machine Learning и какие Python-библиотеки поддерживают это. Проблемы синхронных вызовов в ML-системах В реальных...
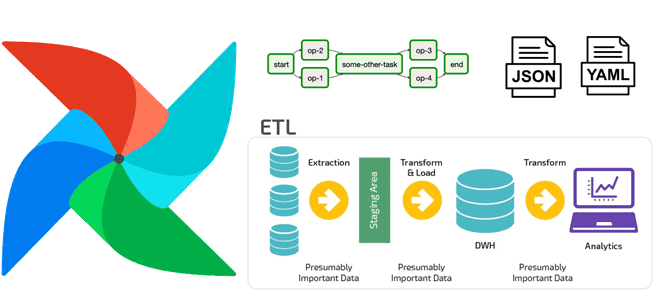
Дата-инженеры часто сталкиваются с изменением структуры конвейера обработки данных в Apache AirFlow, например, когда добавляются новые источники или приемники данных. Однако, менять DAG каждый раз при изменении внешних условий довольно утомительно. Читайте далее, как автоматизировать реорганизацию DAG, используя JSON, YAML-файл или другую плоскую структуру данных для хранения динамической конфигурации рабочего...
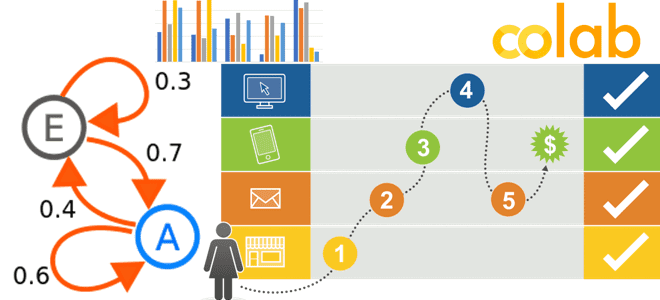
Недавно мы писали, что такое цепь Маркова, как это используется в практических приложениях Data Science и с помощью каких инструментов реализуется этот граф состояний. В продолжение этой полезной для обучения дата-аналитиков темы посмотрим на модели маркетинговой атрибуции как на марковские цепи и разберем пользу этого представления. Практический пример в Google...

В этой статье для обучения дата-инженеров и администраторов кластера Apache AirFlow рассмотрим, как обновить этот ETL-планировщик, используя концепцию сине-зеленого развертывания. Также рассмотрим, с какими ошибками можно столкнуться, выполняя миграцию базы данных метаданных и как их решить. Сине-зеленое развертывание для обновления AirFlow Как и любое программное обеспечение, Apache AirFlow нужно периодически...
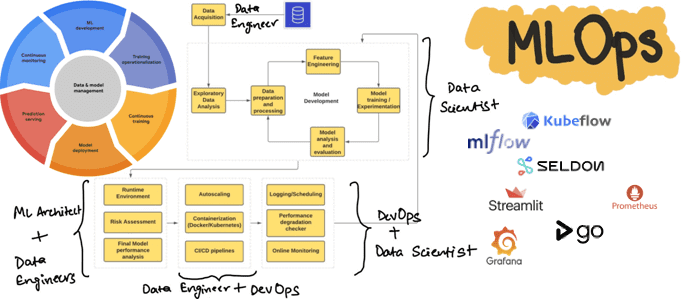
Сегодня рассмотрим, как реализовать полноценный MLOps-цикл, используя свободные инструменты с открытым исходным кодом: MLflow, Kubeflow, Seldon, Streamlit, AirFlow, Git, Prometheus и Grafana. Процессы жизненного цикла ML-систем Концепция MLOps использует проверенные методы DevOps для автоматизации создания, развертывания и мониторинга конвейеров машинного обучения в производственной среде, устраняя рост технического долга в ML-проектах....
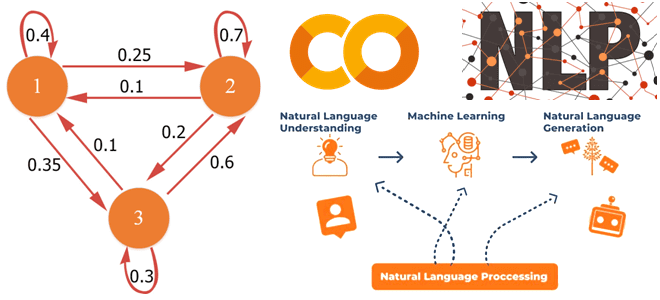
В этой статье для обучения аналитиков данных и специалистов по Data Science рассмотрим, что такое цепь Маркова, где это используется в практических приложениях и с помощью каких инструментов можно реализовать этот граф состояний. В качестве примера рассмотрим генерацию фраз из небольшого текста с помощью методов библиотеки markovify в интерактивном блокноте...
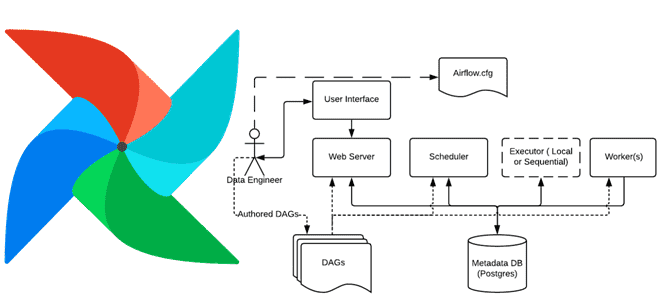
Сегодня рассмотрим, как в Apache AirFlow реализуется обмен данными между задачами с использованием технологии XCom. Чем хорош XCom и почему его не стоит использовать для передачи больших объемов данных: практика организации ETL-конвейеров для дата-инженера. Что такое XCom и зачем это в Apache AirFlow Apache AirFlow не зря является одним из...
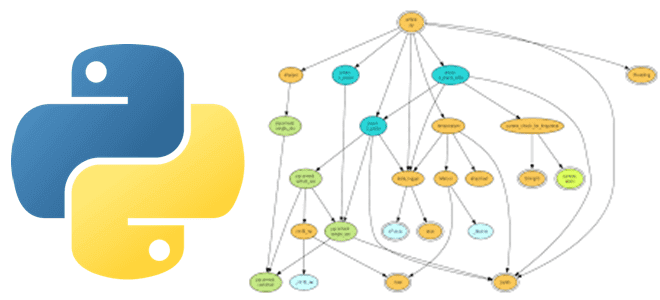
Практически каждый Python-разработчик и Data Scientist использует в своем коде сторонние библиотеки и внешние решения, которые хранятся в разных репозиториях и связаны со множеством других файлов. Этот открытый код настолько распределен, что возникает «ад зависимостей», что сильно осложняет разработку. Читайте, как справиться с этой проблемой, используя методы анализа графов. Проблема...

Как повысить качество данных и пакетных конвейеров с их обработки в Apache AirFlow с Python-библиотекой Whylogs. Что это за средство регистрации и профилирования, как оно работает, каким образом совместимо с DAG-графом задач Apache AirFlow и чем полезно дата-инженеру. Что такое Whylogs и зачем это Apache AirFlow Apache AirFlow активно используется...
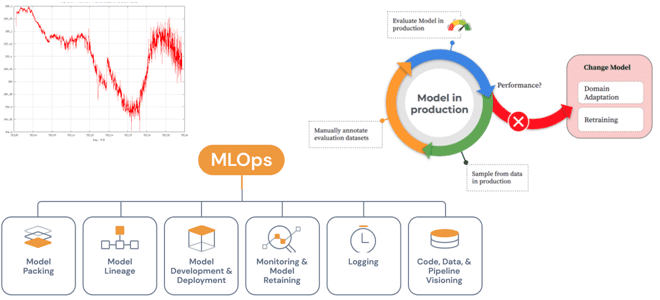
Специально для обучения ML-разработчиков сегодня разберем проблемы развертывания моделей Machine Learning в производстве и способы их решения с помощью MLOps-инструментов. А также поговорим про дрейф данных и его обнаружение методами математической статистики. Жизненный цикл ML-моделей и MLOps Каждый проект машинного обучения начинается с данных, подготовка которых занимает большую часть жизненного...
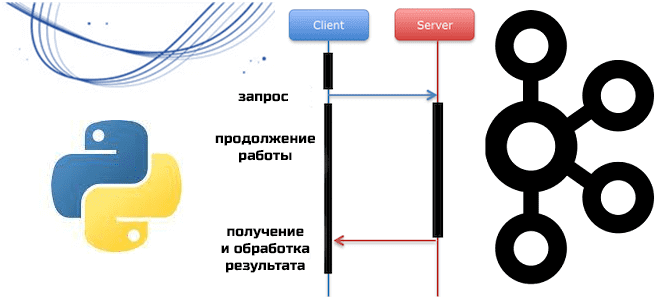
Мы уже писали о Python-клиентах Apache Kafka, которые позволяют разрабатывать приложения потоковой передачи события, используя популярный Python вместо сложных языков Java и Scala. Сегодня познакомимся с еще одной Python-библиотекой, которая представляет асинхронный клиент для Kafka. Что такое aiokafka и чем это отличается от kafka-python: краткий обзор для обучения инженеров данных...