
Будучи популярным фреймворком для оркестрации пакетных процессов обработки Apache AirFlow образует вокруг себя целую экосистему. Сегодня познакомимся с некоторыми инструментами, которые пригодятся дата-инженеру для проектирования и отладки конвейеров данных: ADA, Ditto, Amundsen, gusty и Viewflow. Аналитика системных метрик Apache AirFlow с ADA и Amundsen ADA — это микросервис, созданный для...
Как использовать функции обратного вызова для отладки конвейера обработки данных в Apache AirFlow, а также отправки оповещений об ошибках. Полезные примеры регистрации и мониторинга сбоев на уровне задачи и всего DAG с on_failure_callback(). Польза обратных вызовов Apache AirFlow на примере on_failure_callback По мере роста и усложнения конвейеров данных, построенных с...
Недавно мы разбирали, чем внутренне устройство графовых баз данных отличается от реляционных. Поэтому именно графовые базы целесообразно использовать для анализа больших графовов. Однако, на малых датасетах вполне можно обойтись и Python-библиотекой Networkx, что мы и рассмотрим далее на примере анализа банковских транзакций. Python-скрипт поиска сообществ в графе с библиотекой...
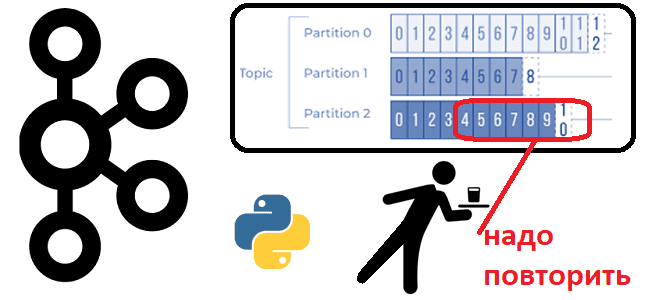
Иногда возникает потребность в повторном чтении данных из Apache Kafka с определенного момента времени. Сегодня рассмотрим, как это сделать, написав простенький Python-скрипт потребления из раздела топика. Публикация данных в Kafka В качестве примера возьмем ранее рассмотренный в этой статье кейс приема потока обращений в интернет-магазин. Обращения могут представлять собой заявки...
Недавно мы писали про устранение зависших в очереди задач в Apache AirFlow 2.6. Сегодня разберемся с другими новинками этого релиза, которые особенно важны для дата-инженера: настраиваемые поля DAG, добавление собственных уведомлений, управление ресурсами, кластеризация исполнителей Kubernetes и еще множество полезных возможностей. Главные новинки и исправления весенних выпусков Apache AirFlow в...

Сегодня посмотрим, как запустить Spark-приложение в Google Colab и увидеть сведения о его выполнении в веб-интерфейсе на удаленной машине, тунеллированной с помощью утилиты ngrok. Проброска туннеля в Google Colab с ngrok для Spark-приложения Хотя назвать Google Colab удобной средой для разработки приложений или исследования данных, нельзя, им часто пользуются аналитики...

Сегодня рассмотрим, как написать и запустить в Google Colab свое Python-приложение считывания данных из топика Kafka с помощью коннектора FlinkKafkaConsumer из библиотеки pyflink.datastream.connectors и почему заставить его работать оказалось не так просто. Использование FlinkKafkaConsumer для доступа к Kafka из Flink приложения Недавно я показывала, как написать PyFlink-скрипт считывания данных из...
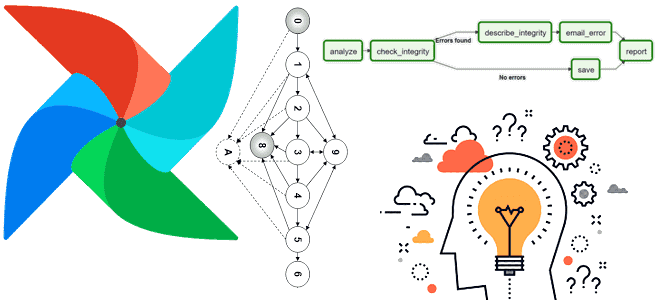
Что такое код верхнего уровня в Apache AirFlow, почему его следует избегать и как это сделать: шаблонные переменные, динамическое сопоставление задач, Python-функции и библиотеки для кэширования. А также 3 нативных способа создания перекрестных зависимостей между DAG для их запуска: TriggerDagRunOperator, ExternalTaskSensor и SimpleHttpOperator. Что такое код верхнего уровня в Apache...
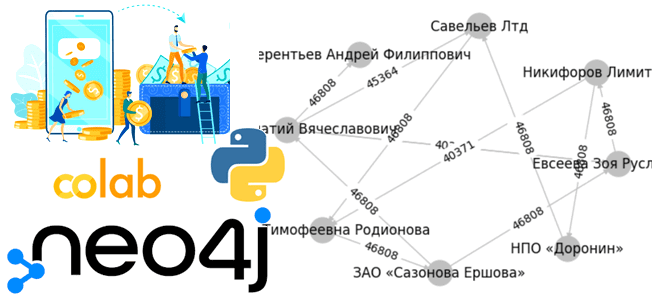
Чтобы показать еще один вариант использования графовой базы данных Neo4j, сегодня реализуем небольшое Python-приложение, которое генерирует граф знаний в облачной платформе Aura DB. Ищем финансовые переводы между компаниями и физическими лицами, считаем общую сумму и визуализируем найденные транзакции с помощью библиотеки Networkx. Python-приложение для работы с Neo4j в AuraDB Как...
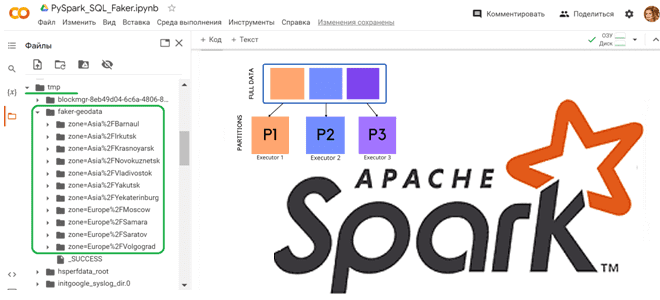
Как сгенерировать набор тестовых данных с Python-библиотекой Faker и разделить данные по разделам, используя функцию partitionBy() в PySpark. Работаем с Apache Spark в Google Colab. Как работает partitionBy() в Apache Spark Чтобы записать на диск один большой датафрейм, разделив его на несколько более мелких файлов, в Python API фреймворка Apache...

Как сделать запуск UDF-функций Python или R на узлах сегмента Greenplum более быстрым и безопасным с помощью Docker-контейнеров и расширения PL/Container. Что такое PL/Container и как это использовать в Greenplum Запуск пользовательского кода для базы данных всегда имеет риск нарушения информационной безопасности. Если речь идет о стеке Big Data, ущерб...

Что появилось нового в мажорном релизе самой популярной Python-библиотеки pandas, чем она похожа на Rust-пакет с Python API polars и в чем между ними разница: тестирование производительности и польза для дата-инженера. Главные новинки pandas 2.0 3 апреля 2023 года вышел долгожданный релиз Python-библиотеки pandas, которая для многих дата-инженеров, аналитиков данных...
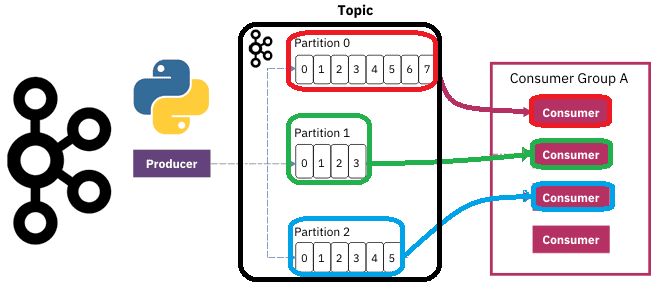
Чтобы разобраться, как на самом деле работают разделы и потребители Apache Kafka, сегодня рассмотрим небольшой демонстрационный пример, иллюстрирующий потребление сообщений. Пишем Python-скрипты публикации и потребления сообщений из разных разделов топика Kafka с занесением данных в несколько вкладок Google-таблицы. Как сообщения распределяются по разделам топика Kafka Напомним, в Apache Kafka раздел...
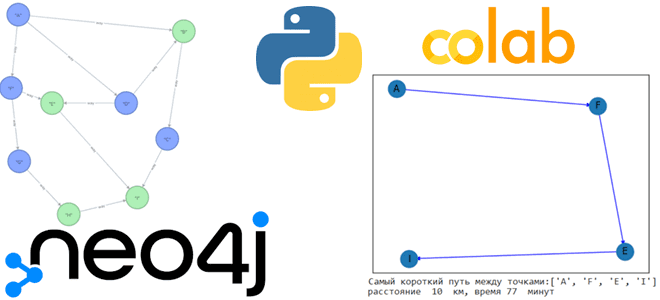
Сегодня решим логистическую задачу поиска кратчайшего пути, создав граф знаний в Neo4j, развернутой в облачной платформе Aura DB и визуализируем найденный путь с помощью Python-библиотеки Networkx. Работа с Neo4j в AuraDB В прошлой статье мы упоминали, что для работы с популярной графовой СУБД Neo4j совсем необязательно устанавливать ее локально. Можно...

Как сделать Apache NiFi еще эффективнее, избежав трех самых популярных ошибок дата-инженера. Разбираемся с автоматизацией операций развертывания, скриптовыми процессорами, а также шаблонами и реестром NiFi для развертывания потоков данных. Ошибка №1: ручное развертывание Хотя Apache NiFi имеет мощный пользовательский интерфейс для проектирования конвейеров потоковой обработки данных, его не стоит рассматривать...
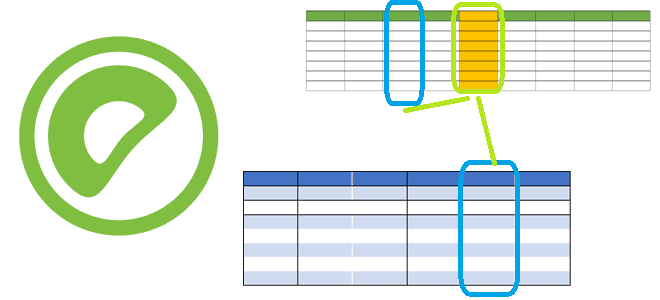
Зачем в Greenplum 7 добавлены вычисляемые (генерируемые) столбцы, как их использовать, и чем они опасны: достоинства, недостатки и ограничения этой возможности. Что такое генерируемые столбцы Поскольку Greenplum основана на PostgreSQL, эта MPP-СУБД имеет множество похожих функций. В частности, в 7-ю версию Greenplum добавлена возможность сохранения вычисляемых (генерируемых) столбцов, которые вычисляются...
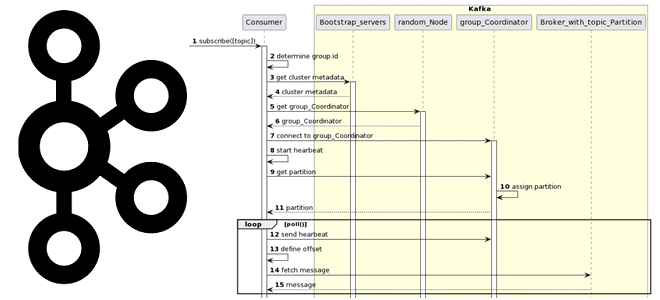
Вчера мы разбирали работу приложения-продюсера и строили UML-диаграмму последовательности. Сегодня рассмотрим, какие системные вызовы происходят при потреблении сообщений из Apache Kafka, при чем здесь группы потребителей и фиксация смещений. Как работает потребитель Kafka Аналогично разработке приложения-продюсера, при написании кода потребителя, который считывает данные из топика Apache Kafka, используются методы специальных...
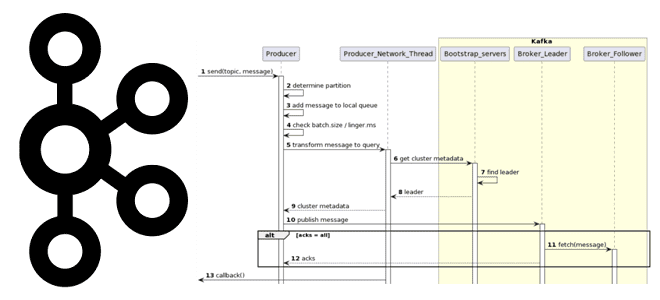
Как на самом деле работает приложение-продюсер Apache Kafka: разбираемся с конфигурациями и составляем UML-диаграмму последовательности системных вызовов при публикации сообщений в топик. Как работает продюсер Kafka Когда разработчик пишет приложение-продюсер, которое публикует сообщение в топик Apache Kafka, он использует методы специальных библиотек, таких как kafka-python и пр. Достаточно только создать...

Как использовать DataStream API в Apache Flink: пишем потребителя из Kafka и запускаем скрипт в Google Colab. StreamExecutionEnvironment и методы коллекций потока данных в PyFlink. DataStream API в Apache Flink: PyFlink в Google Colab для работы с Kafka Apache Flink предоставляет множество возможностей разработчикам на Scala и Java, а также...

Недавно мы разбирали, как дата-инженеру написать собственный оператор Apache AirFlow и использовать его в DAG. Сегодня посмотрим, каким образом с этой задачей справляется модный ИИ под названием ChatGPT. GPT-генерация пользовательского оператора AirFlow Хотя Apache AirFow предоставляет множество операторов для выполнения самых разных задач, иногда дата-инженеру приходится писать свои собственные Python-классы,...