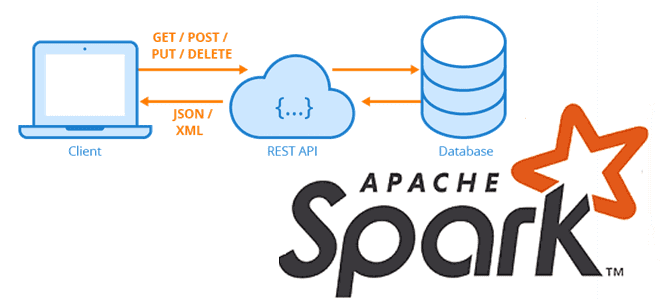
Сегодня рассмотрим, как загружать большие объемы данных из REST API-сервисов с Apache Spark, написав на PySpark собственную UDF-функцию с преобразованием withColumn(), чтобы воспользоваться всеми преимуществами распределенных вычислений этого фреймворка. Локальное исполнение на драйвере и распараллеливание REST-API вызовов в Apache Spark Мы уже рассказывали, что конвертация Python-скрипта в распределенный код Apache...

В октябре прошлого года вышел крупный релиз Apache AirFlow 2.2.0. Разбираем его главные фичи, которые больше всего интересны с точки зрения инженерии данных: пользовательские расписания и декораторы, отложенные задачи, а также валидация параметров DAG по JSON-схеме. Краткий обзор обновлений AirFlow 2.2.0 Хотя последней версией популярного batch-планировщика задач Apache Airflow на...

В этой статье для дата-инженеров и аналитиков рассмотрим пример мониторинга состояния электрогенераторов с помощью анализа данных временных рядов и ранжирования в pandas для предупреждения выхода оборудования из строя. А также разберем основы анализа временных рядов на больших данных с открытой библиотекой Flint для Apache Spark. Постановка задачи: температура и производительность...
Сегодня заглянем под капот особых операторов Apache AirFlow, разберемся с режимами работы датчиков, а также рассмотрим, как создать собственный сенсор. Краткий ликбез по разработке своего sensor’а с лучшими практиками настройки и использования в DAG’ах AirFlow. Что такое сенсор: краткий ликбез по AirFlow Сенсоры или датчики AirFlow — это особый тип...

Развивая наши курсы по Apache Spark и AirFlow для дата-инженеров и администраторов кластеров, сегодня рассмотрим кейс крупного маркетплейса Joom по переходу от 2-ой версии фреймворка на облачной платформе EMR к развертыванию сотен распределенных заданий на 3-ей версии в Amazon Elastic Kubernetes Service. Про сокращение расходов, повышение производительности и апдейт вычислительных движков. Постановка...
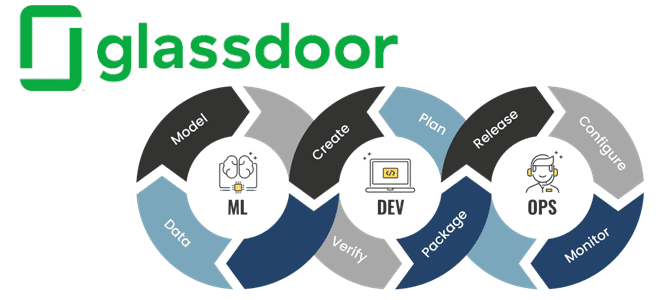
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...

Чтобы сделать наши курсы по Apache Spark еще более полезными, сегодня разберем 2 варианта решения типовой задачи инженерии данных. Как быстро и эффективно считать данные из множества CSV-файлов с одинаковой схемой за несколько строк кода на PySpark. Постановка задачи: рутинная работа с CSV-файлами Наряду с JSON-файлами, про которые мы писали...

Дополняя наши курсы по аналитике больших данных в бизнес-приложениях новыми полезными примерами, сегодня рассмотрим, как Apache Arrow помогает повысить производительность извлечения данных из Neo4j с помощью их колоночного представления и обработки в памяти, а не на диске. Чем neo4j-arrow лучше драйверов Java и Python, а также собственной Neo4j библиотеки Graph...

В этой статье для разработчиков Data Flow, инженеров данных и администраторов Apache AirFlow рассмотрим, как организовать мониторинг этого batch-оркестратора через популярный корпоративный мессенджер Slack. Хотя по умолчанию Airflow имеет встроенную возможность отправлять оповещения по электронной почте, это не самый оперативный способ сообщить о критичной проблеме, к примеру, когда DAG с...

2022 год только начался, а John Snow Labs уже радует разработчиков ML-приложений новым релизом библиотеки Spark NLP. Ключевые фичи 3.4.0 для версии Apache Spark 3.2.x на Scala 2.12: новые GPT-2 трансформеры, аннотаторы для ALBERT, XLNet, RoBERTa, XLM-RoBERTa и Longformer, расширенный хаб готовых Machine Learning моделей и конвейеров, а также исправление...

Сегодня рассмотрим, что такое Great Expectations, чем этот инструмент полезен для специалистов по Data Science и дата-инженеров, а также как связать его с Apache Airflow, какую пользу это принесет в задачах обеспечении качества данных. Также разберем кейс совместного использования Apache Airflow и Great Expectations в компании Vimeo и заглянем под...

В этой статье по обучению дата-инженеров разберем, что такое Apache Beam, чем этот фреймворк отличается от AirFlow и что между ними общего. На первый взгляд Apache Airflow и Beam являются конкурентами: они предназначены для организации процессов обработки данных в определенном порядке. Оба инструмента являются open-source проектами, широко используются и поддерживаются...
Дополняя наши курсы для дата-инженеров по Apache AirFlow полезными примерами, сегодня поговорим про сложности управления зависимыми конвейерами данных в этом batch-оркестраторе. Как решить проблемы связанных DAG’ов в AirFlow и в альтернативном фреймворке Prefect. Все сложно: управление зависимыми DAG в Apache Airflow Apache AirFlow считается одним из самых популярных инструментов современной...
Сегодня разберемся с serverless-технологиями и рассмотрим, как самостоятельно создать и интегрировать бессерверный парсер Selenium с Apache Nifi. Краткий ликбез по OpenFaaS, Selenium и Chromium, а также преимущества serverless-технологий и пример вызова функции сбора данных с веб-страницы на Python. Введение: serverless, OpenFaaS и Selenium с Chromium Serverless-стратегия организации платформенных облачных услуг,...
В рамках наших курсов для дата-инженеров и специалистов в области Data Science, сегодня рассмотрим, как реализовать один из важнейших этапов машинного обучения – Feature Engineering. Читайте далее, как генерировать признаки для ML-модели с помощью SQL, напрямую обращаясь к источникам данных и хранилищам фич, а также что такое Apache Hivemall и...

Развивая наши курсы для дата-инженеров по Apache AirFlow, сегодня рассмотрим, как автоматизировать развертывание сложных DAG’ов с помощью Docker и Kubernetes на примере управления конвейерами обработки данных. Лучшие практики и советы от инженеров данных DataOps-компании Databand. 4 вопроса дата-инженера к production-развертыванию конвейеров Apache Airflow Apache AirFlow считается одним из самых популярных...
Добавляя в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как Airbnb развивает Apache AirFlow и на практике используют эту платформу для создания, планирования и мониторинга конвейеров данных. Что такое Smart Sensor и как умные датчики экономят ресурсы на выполнение долгосрочных легковесных задач. Легкие, долгие и ресурсоемкие: проблемы...
В этой статье для дата-аналитиков и разработчиков распределенных приложений рассмотрим несколько распространенных ошибок, которые можно сделать в PySpark-коде. Когда PySpark-код на DataFrame DSL лучше запросов Spark SQL, как изящно решить проблему длинных строк, почему пользоваться функцией cache() надо осторожно, а также откуда появляются NULL-значения при внешних соединениях потоковых таблиц. Spark...
Чтобы сделать наши курсы для дата-инженеров еще более полезными, сегодня рассмотрим, как объединить Apache NiFi и Airflow в рамках одного ETL-конвейера обработки данных. Читайте далее, зачем совмещать эти технологии и как сделать это наиболее эффективно, обращаясь к конечным точкам REST API процессоров NiFi из задач DAG-графа AirFlow. Apache Airflow +...

MLOps и построение конвейеров машинного обучения – одни из самых актуальных задач современной Data Science. Сегодня рассмотрим, чем совместное использование Apache Airflow и Ray полезно для дата-инженера и ML-разработчика. Читайте далее про кластерное развертывание Python-кода ML-моделей и упрощение ETL-процессов с Apache Airflow и Ray. Apache AirFlow для ML: возможности и...