
Как Apache Spark организует параллельные вычисления, зачем нужны аккумуляторы и каким образом они помогают организовать мониторинг качества данных в аналитических конвейерах их обработки. Смотрим с точки зрения дата-инженера и разработчика распределенных приложений. Как Apache Spark распараллеливает обработку данных Параллельная обработка — это метод вычислений, при котором работает более одного ЦП...
Сегодня рассмотрим, чем отличаются подходы к представлению данных в глубоком машинном обучении и реляционной логике, как это связано с декларативной парадигмой логического программирования и при чем здесь графы. А в качестве примера реализации этих идей рассмотрим комбинацию принципов Deep Learning с реляционной логикой и GNN-нейросетями в Python-библиотеке PyNeuraLogic. Машинное обучение...

Продолжая разбираться с новинками Greenplum версии 7, выпущенной в середине декабря 2022 года, сегодня рассмотрим, как теперь работает SQL-команда с DML-запросов изменения таблиц ALTER TABLE. Как динамически менять структуру и характеристики таблицы даже тех, что предназначены только для добавления с новыми методами доступа. Модели таблиц в Greenplum: Append Only и...

Хотя Apache Pig сегодня не самый актуальный инструмент для аналитики больших данных в экосистеме Hadoop, дата-инженеру полезно знать его основные принципы работы и ключевые отличия от Hive. Также рассмотрим, чем Hive отличается от Pig в качестве средства SQL-on-Hadoop. Что такое Apache Pig Apache Pig – это высокоуровневый процедурный язык для...
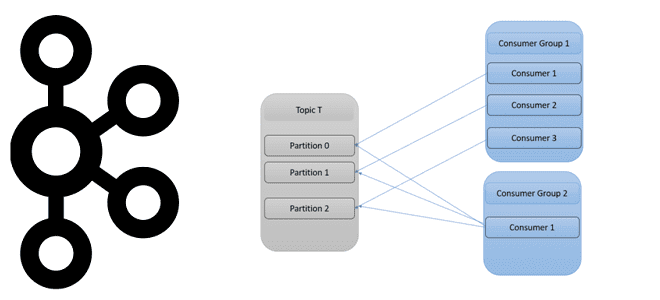
Как количество разделов топика Apache Kafka влияет на потребителей и продюсеров, зачем нужны группы потребителей и как этот механизм реализует идею микросервисной архитектуры Big Data систем. Как работают группы потребителей в Apache Kafka Будучи распределенной платформой потоковой передачи событий, Apache Kafka выполняет роль средства обмена сообщениями между приложениями-продюсерами и приложениями-потребителями...

Как оптимизатор Calcite в Apache Flink переводит SQL-команды в задания потоковой и пакетной обработки и какие приемы могут ускорить их выполнение. Разбираемся, чем полезны интерфейсы пользовательских коннекторов источника и подсказки запросов. Flink SQL в пакетной и потоковой обработке данных Apache Flink позволяет разрабатывать распределенные приложения потоковой обработки больших данных, предоставляя...

В рамках продвижения нашего нового курса по графовой аналитики больших данных, сегодня рассмотрим, как создать граф социальных связей в веб-консоли Neo4j и сделать запросы к нему на Cypher - внутреннем SQL-подобном языке этой NoSQL-СУБД. Как построить граф социальных связей в Neo4j Возьмем в качестве примера набор деловых и личных взаимоотношений...

Apache AirFlow не зря считается у дата-инженеров самым популярным ETL-оркестровщиком. Сегодня посмотрим, чем этот фреймворк полезен в MLOps и как его использовать для оркестровки конвейеров машинного обучения. MLOps в конвейерах машинного обучения Конвейеры машинного обучения в производственной среде обслуживают ML-модели в реальных проектах. Чтобы эффективно управлять такими конвейерами связанных заданий,...
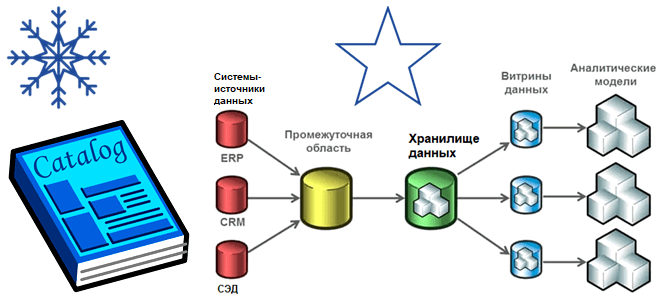
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса. Витрины и хранилища данных Витрина данных (Data Mart) предоставляет информацию...

В этой статье для обучения дата-инженеров и разработчиков распределенных приложений, сегодня разберем опыт ИТ-компании Similarweb, где Apache Spark на платформе Databricks вместо AWS Athena ускорил пакетную обработку данных в 50 раз. Также рассмотрим приемы повышения производительности ODBC-драйвера Databricks для улучшенного взаимодействия с озерами данных. Постановка задачи и ограничения POC для...

Сегодня рассмотрим, что такое воронки, шаблоны, порты и группы процессоров в Apache NiFi и как эти элементы помогают дата-инженеру эффективно проектировать потоковые конвейеры обработки данных. Из чего состоит конвейер обработки данных в Apache NiFi: обзор элементов Благодаря веб-GUI Apache NiFi позволяет дата-инженеру быстро создавать конвейеры потоковой обработки данных, просто располагая...
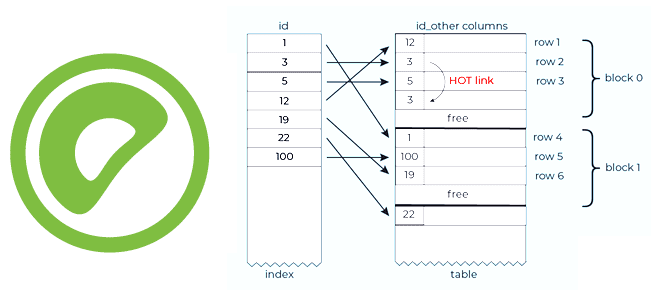
Чтобы сделать наши курсы по Greenplum еще более полезными, сегодня разберем особенности индексов и накладываемых ими ограничений на SQL-запросы к таблицам этой MPP-СУБД. Что такое уникальные индексы и как они поддерживаются в таблицах, оптимизированных для добавления, в Greenplum версии 7, выпущенной в середине декабря 2022 года. Еще раз о пользе...

Сегодня поговорим про Python-библиотеку River, которая позволяет быстро и дешево обновлять модели машинного обучения в производственной среде в режиме реального времени. Чем потоковые ML-конвейеры отличаются от пакетных и с какими сложностями при их реализации может столкнуться Data Scientist. Что такое потоковое машинное обучение Data Scientist’ы обычно используют пакетное обучение для...

Не прошло и пары месяцев с выпуска Apache AirFlow 2.4, о чем мы писали здесь, как вышел новый релиз. Разбираемся с главными новинками версии 2.5 самого популярного ETL-оркестратора: ключевые исправления и значимые для дата-инженера фичи. 30 новинок Apache AirFlow 2.5 2 декабря 2022 года вышел Apache AirFlow 2.5, который включает...
Как использовать мощь Apache Kafka в ИТ-архитектуре корпоративных приложений и интеграции информационных систем: краткий ликбез по ключевым принципам работы этой платформы потоковой передачи событий и важность дата-контрактов для инженера данных, разработчика и архитектора. 9 лучших практик использования Apache Kafka в архитектуре приложений Чтобы успешно применять Apache Kafka в качестве основной...
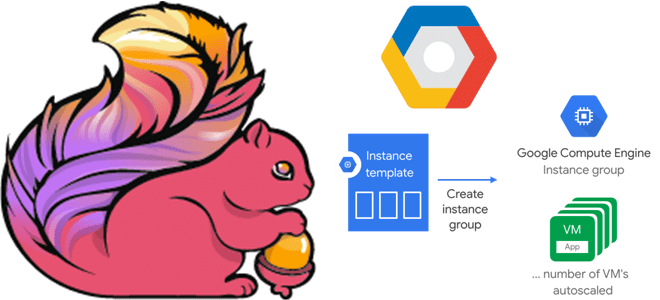
В этой статье для дата-инженеров и разработчиков Flink-приложений рассмотрим, как связаны диспетчеры задач и заданий, зачем настраивать автоматическое масштабирование кластера и как это сделать с помощью Google Auto Scaler в облачной инфраструктуре этого провайдера. Роль диспетчера заданий в Apache Flink и механизмы отказоустойчивости Apache Flink — отличный фреймворк создания приложений...

Учитывая рост интереса к DevOps-инструментам, сегодня рассмотрим, зачем переводить кластер Apache Spark, управляемый YARN, в Kubernetes, и как это сделать наиболее эффективно. А также разберем, какие системные метрики контейнерных Spark-приложений надо отслеживать и с помощью каких средств. Зачем переводить кластер Apache Spark от YARN на Kubernetes Apache Spark не зря...
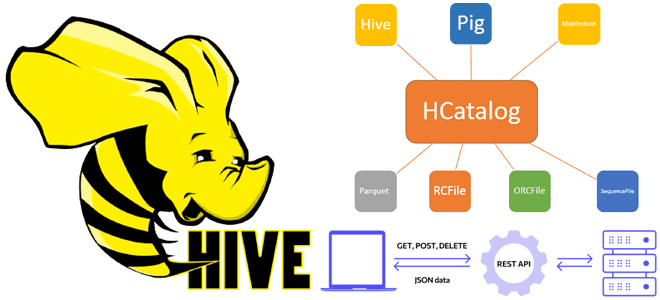
Сегодня рассмотрим, что такое WebHCat в Apache Hive и как этот REST API позволяет взаимодействовать с HCatalog, используя стандартные HTTP-методы. Еще разберем, какие DDL-команды Hive и HiveQL не поддерживает HCatalog, а также что полезного может быть в лог-файлах Templeton. Принципы работы компонента WebHCat как REST-сервиса Apache Hive Будучи NoSQL-хранилищем класса...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня рассмотрим, какие интерфейсы и протоколы для связи клиента с брокером использует эта платформа потоковой передачи событий. А также рассмотрим, что обеспечивает двунаправленную совместимость API. Протоколы и интерфейсы Apache Kafka для общения клиентов с брокерами Apache Kafka использует бинарный протокол...

В марте 2022 года в Github появился исходный код TorchMultimodal – PyTorch-библиотеки для обучения масштабных мультимодальных многозадачных ML-моделей. А 17 ноября вышел бета-релиз этой библиотеки, который содержит множество полезных примеров и лучших архитектур глубокого обучения. Разбираемся с этой новой библиотекой. Что такое мультимодальные ML-модели и при чем здесь TorchMultimodal Человек...