
29 сентября 2021 года вышла новая версия популярного Big Data фреймворка Apache Flink. Мы сделали краткий обзор главных улучшений свежего релиза 1.14 общедоступного дистрибутива, а также его коммерциализации в Ververica Platform 2.6. Узнайте, как потоковая обработка и аналитики больших данных с Apache Flink станет еще проще и эффективнее. Исправление ошибок...

Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google....

Постоянно обновляя наши курсы по Apache Kafka, сегодня рассмотрим еще один полезный инструмент для администраторов, дата-инженеров и разработчиков, который повышает эффективность взаимодействия с этой распределенной платформой потоковой обработки событий. Что такое Saamsa, какие проблемы Kafka она решает и как ее использовать на практике. 5 вопросов разработчика и дата-инженера к Apache...
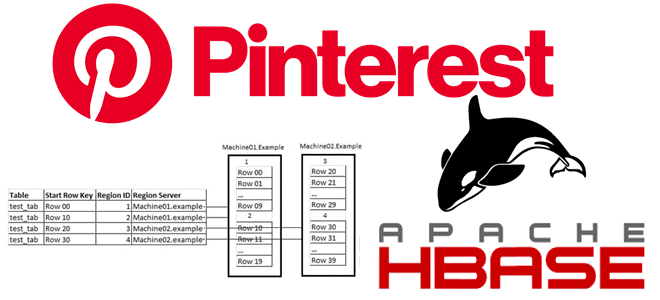
Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с...

Недавно мы писали про платформы потоковой обработки событий, альтернативные Apache Kafka и Flink/Spark Streaming. В продолжение этой темы сегодня рассмотрим еще пару вариантов для разработки и самообслуживаемого использования потоковых конвейеров аналитики больших данных: DataCater и Flow. Читайте далее, что это за системы, как они связаны с Apache Kafka и какова...

Сегодня разберем типичный для современной дата-инженерии кейс построения конвейера обработки измененных данных на Apache NiFi с учетом безопасности и масштабируемости API-вызовов. Также рассмотрим, зачем использовать Apache NiFi при межсистемной интеграции через API-вызовы и как реализовать CDC-подход к изменениям в СУБД MySQL с помощью процессоров этого популярного ETL-фреймворка. CDC и интеграция...

Продолжая недавний разговор про потоковую передачу событий и соответствующие Big Data инструменты, сегодня рассмотрим не отдельные фреймворки обработки данных в режиме реального времени, а комплексные платформы, которые объединяют сразу несколько технологий для интерактивной аналитики больших данных. Вас ждет краткий обзор Cloudera Streaming Analytics, Materialize и Rockset: что это такое, как...
Хотя Apache Kafka стала стандартом де-факто для потоковой передачи событий, на этой платформе можно реализовать и пакетный режим вычислений. В рамках обучения дата-инженеров, сегодня рассмотрим, как совместить пакетную парадигму обработки Big Data с потоковой, развернув конвейер аналитики больших данных на Apache Kafka. Пакеты и потоки: versus или вместе Пакетную и потоковую...

В продолжение недавней статьи для дата-инженеров про альтернативные платформы потоковой передачи событий вместо Apache Kafka, сегодня рассмотрим пример аналитики больших данных средствами Flink SQL, записи результатов в Elasticsearch и их визуализации в Kibana. Читайте далее, чем Redpanda отличается от Kafka, а Flink – от Apache Spark с точки зрения потоковой...

При том, что Apache Kafka является фреймворком №1 в потоковой обработке Big Data, эта распределенная платформа передачи событий имеет специфические недостатки и ограничения, которые затрудняют ее использование в некоторых сценариях. Сегодня рассмотрим, что именно в Apache Kafka усложняет жизнь администраторам, разработчикам и дата-инженерам, а также как Redpanda решает эти проблемы....

В этой статье для разработчиков Apache Kafka рассмотрим пример масштабирования потоковой обработки событий с Akka Streams. Читайте далее, что не так с параллелизмом при одновременном выполнении событий на запись, как Akka Streams решает эту проблему и при чем здесь Apache Kafka. Проблемы масштабирования потоковой обработки в Kafka Streams Масштабная потоковая...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...
Сегодня рассмотрим пример построения интеллектуальными конвейера потоковой обработки видео с Apache Kafka и алгоритмами машинного обучения. Читайте далее, зачем для этого нужен протокол RTSP, что такое библиотека Sarama и как интегрировать алгоритмы машинного/глубокого обучения в систему видеоаналитики реального времени. Потоковая видеоаналитика: прием мультимедиа в реальном времени Видеоаналитика – одно из...

Сегодня рассмотрим пару кейсов по использованию Apache Flink в качестве основного фреймворка пакетной и потоковой аналитики больших данных. Читайте далее, как фото-хостинг Pinterest построил вокруг Flink собственную инфраструктуру работы с изображениями в реальном времени, а китайский ритейл-гигант Alibaba Group успешно обрабатывал 7 ТБ в секунду во время глобального дня шопинга....

Недавно мы рассказывали про KafkaJS – клиент Apache Kafka для Node.js, который отличается небольшим размером и простым развертыванием с удобным API. Сегодня рассмотрим еще пару полезных инструментов визуализации данных о Kafka-кластере на базе KafkaJS и Prometheus. Читайте далее, что такое FlowKat и Monokl, а также зачем они нужны дата-инженеру, разработчику...
Сегодня рассмотрим, что такое KafkaJS, как это связано с Apache Kafka и JavaScript, в чем преимущества этой технологии и как разработчику распределенных приложений потоковой аналитики больших данных использовать ее на практике. Также вас ждет краткий ликбез по Node.js и примеры разработки KafkaJS-приложения. Краткий ликбез по Node.js Важными достоинствами архитектуры потоковой передачи...

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...
В поддержку курсов по администрированию Apache Kafka, сегодня рассмотрим особенности масштабирования кластера и связанное с этим переназначение разделов. Читайте далее, чем горизонтальное масштабирование лучше вертикального, как переназначить разделы между брокерами Kafka с целью перебалансировки нагрузки и зачем ограничивать полосу пропускания для перемещения реплик между узлами кластера. Проблемы масштабирования кластера Apache...

Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне. Постановка задачи: бизнес-контекст и используемые технологии В...
Завершая серию статей по IoT-платформе компании Tesla на базе Apache Kafka, сегодня рассмотрим проблемы пиковой загрузки системы и особенности обработки высокоприоритетных событий. Читайте далее, как оптимально определить ключ раздела, чтобы снизить затраты на передачу данных, избежать перегрузки в пиковые моменты и отделить пользователей данных от разработчиков и дата-инженеров. Тонкости обработки...