
Мы уже разбирали некоторые советы оптимизации Flink-приложений, связанные с неравномерным распределением данных по вычислительным узлам. Сегодня рассмотрим, как при этом пригодится паттерн MapReduce Combiner, который часто используется в экосистеме Apache Hadoop и вместо него лучше применить Bundle оператор, доступный с версии Flink 1.15. Проблема неравномерного распределения в Big Data вообще...
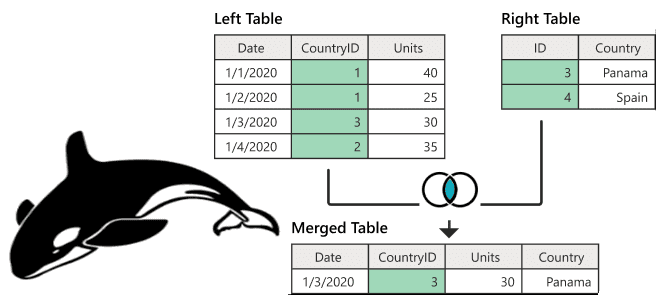
Поиск данных по нескольким таблицам в реляционных базах данных реализуется через SQL-запрос с оператором JOIN. В NoSQL-хранилищах такая возможность может отсутствовать. Разбираем, как соединить таблицы в Apache HBase и причем здесь MapReduce. Варианты реализации JOIN в Apache HBase Будучи популярной NoSQL-базой, которая реализует возможности Google BigTable для Apache Hadoop, HBase...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...

Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...

Каждый разработчик и дата-аналитик с закрытыми глазами напишет SQL-запрос с регулярными выражениями для поиска данных по шаблону в реляционной базе. А вот в NoSQL-СУБД такая простая задача реализуется довольно сложно. Как написать регулярное выражение в Apache HBase и запустить его на исполнение в CLI-интерфейсе shell-оболочки этого хранилища данных. Что такое...

Сегодня разберем, как автоматизировать наполнение озера данных на HDFS через загрузку таблиц из реляционной базы MySQL в Hive с помощью Apache NiFi. Какие процессоры NiFi следует использовать и зачем предварительно разделять таблицу Apache Hive. Пример ETL-конвейера на процессорах Apache NiFi Apache NiFi часто используется дата-инженерами в качестве средства автоматизации и...
Рассмотрим, как дата-инженеры Airbnb делятся своим опытом перевода корпоративного Data Lake на Apache HDFS в облачное объектное хранилище AWS S3. Почему пришлось переводить аналитические нагрузки с Apache Hive на Iceberg и Spark, и какие результаты это принесло. Предыстория: Data Lake на HDFS и Apache Hive Будучи крупнейшей онлайн-площадкой для размещения...

8 августа 2022 года вышел очередной релиз главной технологии стека Big Data – Apache Hadoop 3.3.4. Разбираемся с ключевыми фичами этого выпуска и исправлениями ошибок, которые особенно важны для администратора кластера и дата-инженера. ТОП-10 обновлений Apache Hadoop 3.3.4 Apache Hadoop 3.3.4 включает в себя ряд значительных улучшений по сравнению с...

Для практического обучения дата-инженеров и архитекторов Big Data систем сегодня рассмотрим трудности изоляции и распределения в кластере Apache HBase и способы их обхода. С какими проблемами изоляции и сбалансированного распространения данных столкнулись инженеры индийской e-commerce компании Flipkart при организации мультиарендного кластера Apache HBase и как их решили. Изоляция данных и...

В этой статье для обучения дата-инженеров и администраторов SQL-on-Hadoop рассмотрим способы обеспечения информационной безопасности и защиты данных от несанкционированного доступа в Apache Hive. Классический security-набор: аутентификация, авторизация и шифрование. Авторизация и аутентификация в Apache Hive Будучи популярным инструментом стека SQL-on-Hadoop, Apache Hive поддерживает все механизмы обеспечения информационной безопасности, поддерживаемый базовой...

Недавно мы рассматривали производительность ETL-конвейеров на Apache Spark с озером данных на MinIO. Сегодня разберем, чем это легковесное объектное хранилище отличается от распределенной файловой системы Apache Hadoop и как перейти на него с HDFS. Зачем переходить на MinIO Хотя HDFS до сих пор активно используется во многих Big Data проектах...
При том, что большинство современных озер данных представляют собой облачные объектные хранилища типа AWS S3, многие предприятия хранят данные в собственном кластере HDFS или даже MinIO. Поэтому сегодня специально для обучения дата-инженеров и ИТ-архитекторов рассмотрим, что представляет собой это хранилище и насколько хорошо с ним взаимодействует Apache Spark. Что такое...
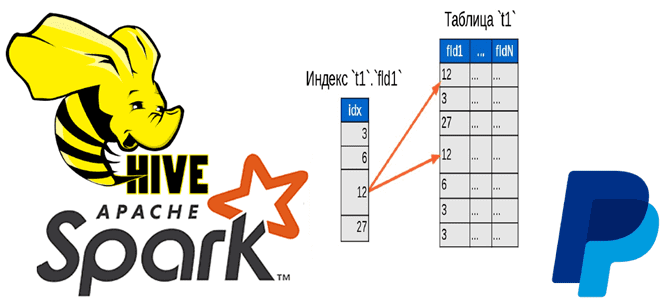
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...

Хотя Apache HBase обладает массой достоинств, такими как строгая согласованность на уровне строк при больших объемах запросов, гибкая схема, доступ к данным с малой задержкой и интеграция с Hadoop, эта NoSQL-СУБД имеет ряд недостатков: чрезмерная сложность и дороговизна эксплуатации, отсутствие вторичных индексов и ACID-транзакций. Поэтому инженеры фотохостинга Pinterest приняли решение...

Мы уже писали, что технологии Big Data ориентированы на работу с большими данными, а не множеством маленьких. Сегодня рассмотрим подробнее, почему Apache Hadoop, Spark и основанные на HDFS NoSQL-СУБД Hive и HBase плохо работают с большим количеством маленьких файлов, а также как это исправить. Почему HDFS плохо работает со множеством...

В рамках обучения аналитиков данных, дата-инженеров и разработчиков распределенных приложений, сегодня поговорим про материализованные представления в Apache Hive. Что это такое, зачем нужно и как реализуется в самом популярном NoSQL-хранилище стека SQL-on-Hadoop. Что такое материализованное представление и зачем это надо в аналитике больших данных: краткий ликбез Аналитика данных включает в...

Специально для обучения администраторов кластера Apache Hadoop сегодня рассмотрим, как улучшить производительность распределенной файловой системы. Зачем перемещать файлы на последний узел в кластере, как оптимизировать управление дисками, а также чем полезно централизованное кэширование в HDFS. Оптимизация операций ввода-вывода на жестком диске Преимущества HDFS – распределенной файловой системы Apache Hadoop по...

Сегодня рассмотрим компоненты и механизмы обеспечения отказоустойчивости Apache HBase. Что делать, когда региональный сервер выходит из строя и как процедура ServerCrashProcedure перераспределяет регионы данных на другие рабочие сервера в кластере Apache HBase. А также разберем, какие параметры конфигурации следует настроить администратору кластера для наиболее эффективного выполнения процессов записи и восстановления...

Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и...