
Мы уже разобрали, что общего между Apache Hive и Cloudera Impala. В этой статье рассмотрим работу этих систем с точки зрения программиста, а также поговорим про язык HiveQL. Читайте в сегодняшнем материале, как эти системы выполняют SQL-запросы для аналитики больших данных (Big Data), хранящихся в кластере Hadoop. Что такое HiveQL,...

В прошлой статье мы рассмотрели основные возможности и ключевые характеристики Apache Hive и Cloudera Impala. Сегодня подробнее поговорим про то, что между ними общего и чем отличаются друг от друга эти SQL-инструменты для обработки больших данных (Big Data), хранящихся в кластере Hadoop. Что общего между Apache Hive и Cloudera Impala:...

Сегодня мы рассмотрим Apache Hive и Cloudera Impala – аналитические SQL-средства для работы с данными, хранящимися в экосистеме Apache Hadoop и других Big Data хранилищах: HDFS, HBase, Amazon S3. Читайте в нашей статье, что такое Hive и Impala, где они используются и почему они не заменяют, а дополняют друг друга....
Продолжая разговор про Apache NiFi и другие ETL-инструменты больших данных, сегодня мы подробнее расскажем про пакетные средства загрузки и маршрутизации информации из различных источников: Sqoop, Chuckwa и Falcon. Читайте в нашей статье, чем они похожи и чем отличаются, а также как применяются в Big Data системах и интернете вещей (Internet...
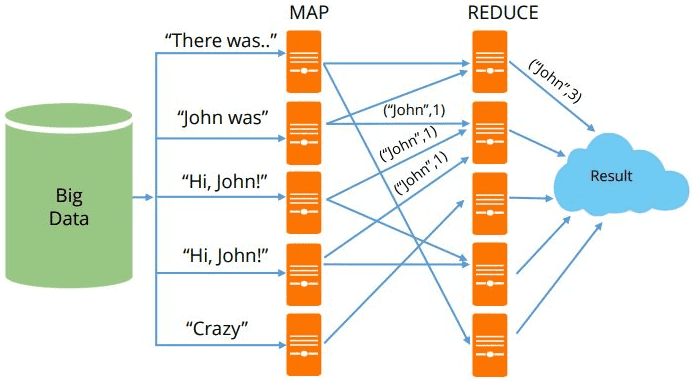
MapReduce можно назвать основой Big Data, т.к. именно данная технология позволяет обрабатывать огромные массивы информации параллельно в распределенных кластерах. Эту вычислительную модель поддерживают множество различных коммерческих и свободных продуктов: Apache Hadoop, Spark, Greenplum, Hive, MongoDB, Phoenix, DryadLINQ и прочие Big Data фреймворки и библиотеки, написанные на разных языках программирования [1]. Сегодня...

Apache Samza часто сравнивают с другими Big Data фреймворками распределенных потоковых вычислений в реальном времени (Real Time, RT): Kafka Streams, Spark Streaming, Flink и Storm. Apache Spark и Flink обладают практически одинаковым набором функциональных возможностей и компонентов, поэтому их можно сравнивать между собой более-менее объективно. Apache Samza является более простой...

Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм,...

Сегодня мы рассмотрим популярные Big Data инструменты обработки потоковых данных: Apache Kafka Streams и Spark Streaming: чем они похожи и чем отличаются. Стоит сказать, что Спарк Стриминг и Кафка Стримс – возможно, наиболее популярные, но не единственные средства обработки информационных потоков Big Data. Для этой цели существует еще множество альтернатив,...

Продолжая разговор про форматы Big Data файлов, сегодня мы рассмотрим разницу между линейными и колоночными типами, а также расскажем о том, как выбирать между AVRO, Sequence, Parquet, ORC и RCFile при работе с Apache Hadoop, Kafka, Spark, Flume, Hive, Drill, Druid и других средствах работы с большими данными. Итак, форматы...

Мы уже упоминали формат Parquet в статье про Apache Avro, одну из наиболее распространенных схем данных Big Data, часто используемую в Kafka, Spark и Hadoop. Сегодня рассмотрим более подробно, чем именно хорошо Apache Parquet и как он отличается от других форматов Big Data. Что такое Apache Parquet и как он...

Мы уже рассказывали о сериализации, схемах данных и их важности в Big Data на примере Schema Registry для Apache Kafka. В продолжение ряда статей про основы Кафка для начинающих, сегодня мы поговорим про Apache Avro – наиболее популярную схему и систему сериализации данных: ее особенностях и применении в технологиях Big...

Администратор – обязательная роль в Big Data проекте, даже если он построен по принципу микросервисной архитектуры, когда за создание и развертывание каждого модуля отвечает отдельный DevOps-инженер. Задачи постоянной оценки производительности и поддержки ИТ-инфраструктуры актуальны как для новоявленных стартапов, работающих по современным Agile-принципам, так и для крупного бизнеса (enterprise). В этой...

Чтобы сохранить большие данные от утечек, чиновники придумывают различные законы, а разработчики чинят уязвимости в Big Data системах. Продолжая разговор про информационную безопасность больших данных, сегодня мы подготовили для вас статью про технические средства защиты кластера Apache Hadoop. Возможные угрозы для кластера Big Data и средства их предотвращения В реальности...

Проанализировав предложения крупных PaaS/IaaS-провайдеров по развертыванию облачного кластера, сегодня мы сравним 4 наиболее популярных дистрибутива Hadoop от компаний Cloudera, HortonWorks, MapR и ArenaData, которые используются при развертывании локальной инфраструктуры для проектов Big Data. Как мы уже отмечали, эти дистрибутивы распространяются бесплатно, но поддерживаются на коммерческой основе. Некоторые отличия популярных дистрибутивов...

Мы уже рассказывали про общие достоинства и недостатки облачных Hadoop-кластеров для проектов Big Data и сравнивали локальные дистрибутивы. В продолжение этой темы, в сегодняшней статье мы подготовили для вас сравнительный обзор наиболее популярных PaaS/IaaS-решений от самых крупных иностранных (Amazon, Microsoft, Google, IBM) и отечественных (Яндекс и Mail.ru) провайдеров [1]. Сравнение...

Продолжая опровергать мифы о Hadoop, сегодня мы расскажем о том, как и где создать облачный кластер для Big Data и почему это выгодно. Концепция облачных вычислений стала популярна с 2006 года благодаря компании Amazon и постепенно распространилась на использование внешних платформ и инфраструктуры как сервисов (Platform as a Service, PaaS,...
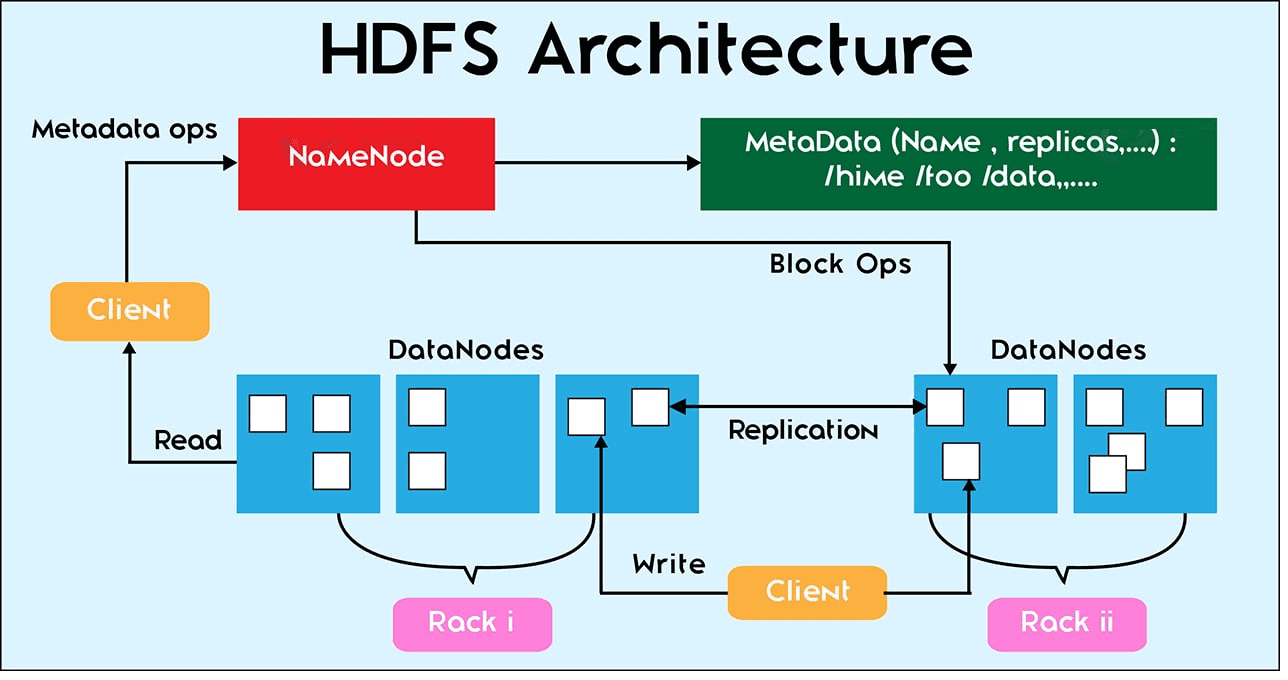
Мы уже рассказывали, как большие данные (Big Data) сохраняются на диск. Сегодня поговорим о других файловых операциях в HDFS: репликации, чтении и удалении данных. За все файловые операции в Hadoop Distributed File System отвечает центральная точка кластера – сервер имен NameNode. Сами операции с конкретными файлами выполняются на локальном узле...
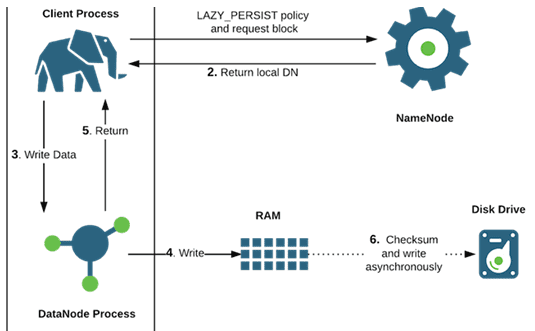
HDFS предназначена для больших данных (Big Data), поэтому размер файлов, которые хранится в ней, существенно выше чем в локальных файловых системах – более 10 GB [1]. Продолжая тему файловых операций и взаимодействия компонентов Hadoop Distributed File System, в этой статье мы расскажем, как осуществляется запись таких больших файлов с учетом блочного...

Благодаря архитектурным особенностям распределенной файловой системы Hadoop, допустимые файловые операции в ней отличаются от возможных действий с файлами на локальных системах. В этой статье мы рассмотрим файловые операции в HDFS и взаимодействие ее компонентов: узлов данных и сервера имен с клиентами - пользователями или приложениями. Файловые операции HDFS В отличие...

Сегодня мы поговорим о заблуждениях насчет базового инфраструктурного понятия хранения и обработки больших данных – экосистеме Hadoop и развеем 3 самых популярных мифа об этой технологии. А также рассмотрим применение Cloudera, Hortonworks, Arenadata, MapR и HDInsight для проектов Big Data и машинного обучения (Machine Learning). Миф №1: Hadoop – это...