
В этой статье поговорим про интеграцию информационных систем: обсудим SOA и ESB-подходы, рассмотрим стриминговую архитектуру и возможности Apache Kafka для организации быстрого и эффективного обмена данными между различными бизнес-приложениями. Также обсудим, что влияет на архитектуру интеграции корпоративных систем и распределенных Big Data приложений, что такое спагетти-структура и почему много сервисов...

В этой статье поговорим про интеграцию ELK-стека с экосистемой Apache Hadoop: зачем это нужно и с помощью каких средств можно организовать обмен данными между HDFS и Elasticsearch, а также при чем здесь Apache Spark, Hive и Storm. Еще рассмотрим несколько практических примеров, где реализована такая интеграция Big Data систем для...

Сегодня рассмотрим основные преимущества ClickHouse – аналитической СУБД от Яндекса для обработки запросов по структурированным большим данным в реальном времени. Читайте в нашей статье, чем еще хорош Кликхаус, кроме высокой скорости, и почему эту систему так любят аналитики, разработчики и администраторы Big Data. Чем хорош ClickHouse: главные преимущества Напомним, основным...

Интеграционный движок Kafka Engine для потоковой загрузки данных в ClickHouse из топиков Кафка – наиболее популярный инструмент для связи этих Big Data систем. Однако, он не единственное средство интеграции Кликхаус с Apache Kafka. Сегодня рассмотрим, как еще можно организовать потоковую передачу больших данных от самого популярного брокера сообщений в колоночную...
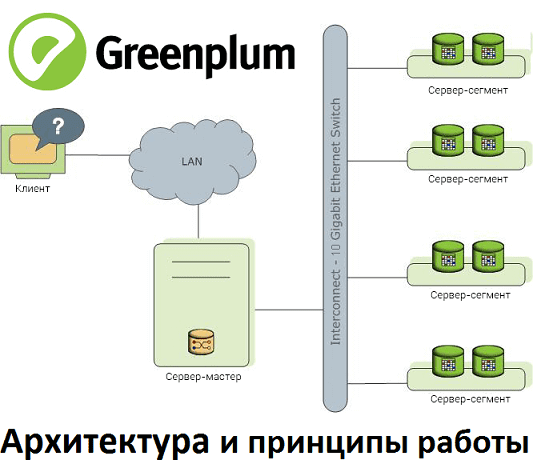
В этом материале рассмотрим реализацию массово-параллельной архитектуры для хранения и аналитической обработки больших данных на примере популярной Big Data СУБД Greenplum. Прочитав эту статью, вы поймете, почему MPP-базы потребляют много ресурсов и как связано число сегментов со скоростью работы кластера. MPP, Greenplum и PostgreSQL Напомним, СУБД Greenplum – это типичный представитель...

Сегодня поговорим про достоинства и недостатки массово-параллельной архитектуры для хранения и аналитической обработки больших данных, рассмотрев Greenplum и Arenadata DB. Читайте в нашей статье, что такое MPP-СУБД, где и как это применяется, чем полезны эти Big Data решения и с какими проблемами можно столкнуться при их практическом использовании. Что MPP-СУБД...

Вчера мы рассказывали про применение Arenadata DB в крупной отечественной сети розничного ритейла. Сегодня рассмотрим еще один Big Data продукт от российской компании Аренадата, который Х5 Retail Group использует для быстрой аналитики больших данных. Читайте в нашей статье, что такое Arenadata QuickMarts и при чем здесь ClickHouse от Яндекса. Что...

Продолжая разговор про успехи применения отечественных Big Data продуктов, сегодня мы рассмотрим пример использования Arenadata DB в одной из ведущих отечественных компаний розничного ритейла. Читайте в нашей статье про особенности внедрения распределенной отказоустойчивой MPP-СУБД для аналитики больших данных в Х5 Retail Group. Зачем ритейлеру еще одно Big Data решение: специфика...

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...
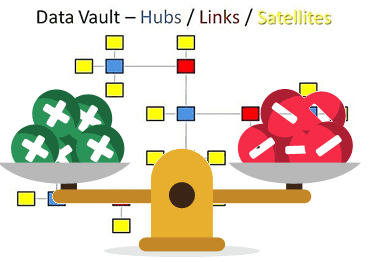
В этой статье мы рассмотрим основные плюсы и минусы Data Vault – популярного подхода к моделированию сущностей при проектировании корпоративных хранилищ данных (КХД). Читайте сегодня, почему промежуточные базы перед витринами данных упрощают ETL-процессы, за счет чего обеспечивается отсутствие избыточности и как много таблиц могут усложнить жизнь архитектора Big Data. Чем...
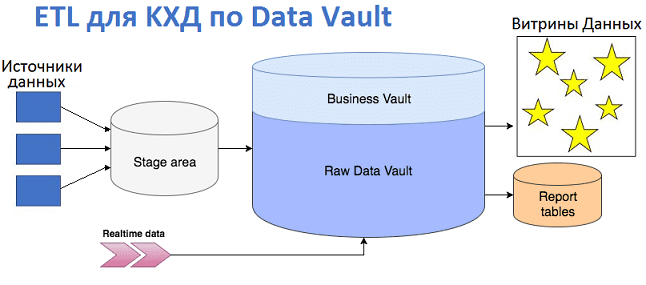
Продолжая разговор про проектирование корпоративных хранилищ данных с использованием подхода Data Vault, сегодня мы рассмотрим, как эта модель влияет на дизайн ETL-процессов и их реализацию. Читайте в нашей статье про загрузку данных в КХД по модели Data Vault и проблемы, которые могут при этом возникнуть, а также способы их решения...
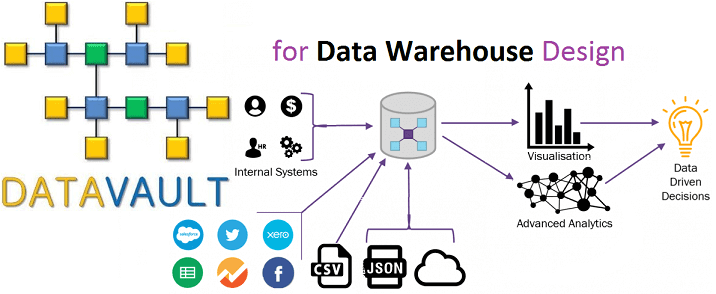
Вчера мы рассмотрели, что такое Data Vault, почему возникла эта модель и чем она полезна при проектировании архитектуры корпоративных хранилищ данных (КХД) и озер данных (Data Lake). Сегодня разберем ключевые понятия Data Vault и поговорим про возможности Data Vault 2.0 для области больших данных (Big Data). Ключевые понятия Data Vault...
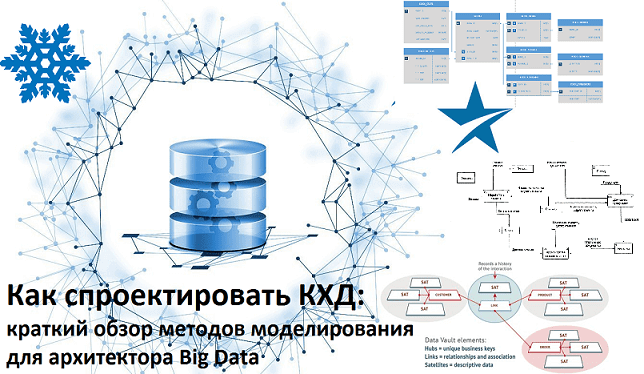
Сегодня мы поговорим о проектировании архитектуры корпоративных хранилищ данных (КХД) и рассмотрим, какие методы и инструменты используются для моделирования структуры DWH и динамики ETL-процессов. В этой статье про основы Data Modelling разберем, что такое OLAP и OLTP, почему 3-я нормальная форма стала стандартом в SQL-СУБД, чем схемы звезды отличается от...

В продолжение темы про корпоративные хранилища данных, сегодня мы рассмотрим облачные варианты Data Warehouse с учетом тренда на расширенную аналитику Big Data на базе машинного обучения. Читайте в нашей статье про синергию классической LSA-архитектуры локального КХД с Лямбда-подходом, MPP-СУБД, а также Apache Hadoop, Spark, Hive и другими технологиями больших данных....

В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data). Где хранить...