В этой статье продолжим говорить про лучшие практики работы с Greenplum и рассмотрим тонкости проектирования схем данных в этой MPP-СУБД, которая часто применяется для хранения и аналитики больших данных. Почему надо задавать одинаковые типы данных для столбцов, используемых в SQL-запросах c оператором JOIN, чем хранилище кучи отличается от Append Only,...
В этой статье для обучения дата-инженеров рассмотрим, как крупнейший медиа-банк Storyblocks добился обновления данных в корпоративном хранилище без простоев с помощью DevOps-идеи сине-зеленого развертывания и механизма TaskGroup в Apache Airflow. Проблемы ETL при массовой загрузке данных в Data Lake и DWH Storyblocks – это крупнейший в мире банк данных, включающий...
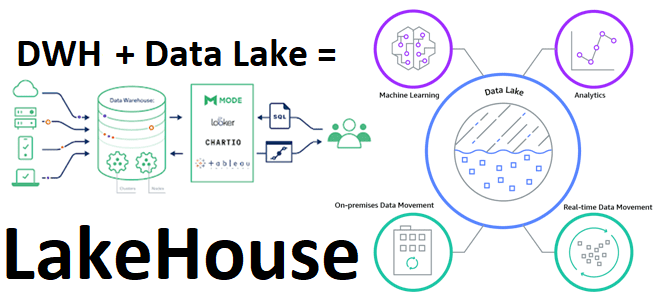
В рамках обучения дата-инженеров и архитекторов корпоративных платформ и приложений аналитики больших данных, сегодня рассмотрим, что такое LakeHouse. Как эта новая гибридная архитектура управления данными объединяет 2 разнонаправленные парадигмы хранения информации, а также чего от нее ожидают бизнес-пользователи, дата-инженеры, аналитики и ML- специалисты. Историческая справка: от DWH к Data Lake...
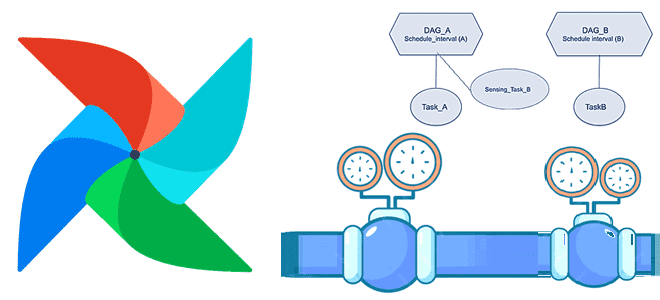
Мы уже писали про датчики или сенсоры - особый тип операторов Apache AirFlow, предназначенных для ожидания какого-то события. Сегодня рассмотрим практический пример обучения дата-инженеров и разработчиков по использованию внешнего сенсора в рамках типовой задачи дата-инженерии по организации ETL/ELT-процессов при поэтапной загрузке данных в DWH для OLAP-систем. Постановка задачи: поэтапная загрузка...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...

Развивая наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим, почему в этой MPP-СУБД возникают проблемы нехватки памяти, каковы типовые способы их решения и чем очереди ресурсов отличаются от ресурсных групп. Читайте далее про схемы управления ресурсами в Greenplum и особенности параметра конфигурации statement_mem. Очереди vs Группы: 2 схемы управления...
В этой статье поговорим про Viewflow: что такое, как устроено, чем полезно аналитикам данных и Data Scientist’ам. Встречайте новый фреймворк на базе Apache AirFlow от DataCamp – американского edu-стартапа в области ИИ, который упрощает создание и управление материализованными представлениями на SQL, R и Python в концепции low code, т.е. практически...

Сегодня разберем еще одну интересную тему из нашего нового курса «Greenplum для инженеров данных» по построению конвейеров приема данных для этой MPP-СУБД в рамках веб-интерфейса платформы автоматизированного управления потоками работ Apache NiFi. Читайте далее, как устроен коннектор VMware Tanzu Greenplum для Apache NiFi и какие возможности он предоставляет дата-инженеру. Что...

Партиционирование таблиц – надежный способ повышения производительности Greenplum, который тесно связан с особенностями распределения данных по сегментам кластера. Читайте далее, чем опасно неравномерное распределение данных и вычислений по узлам, а также как найти дата-инженеру и устранить эти перекосы в MPP-СУБД, чтобы повысить скорость выполнения SQL-запросов и решить проблемы с нехваткой...
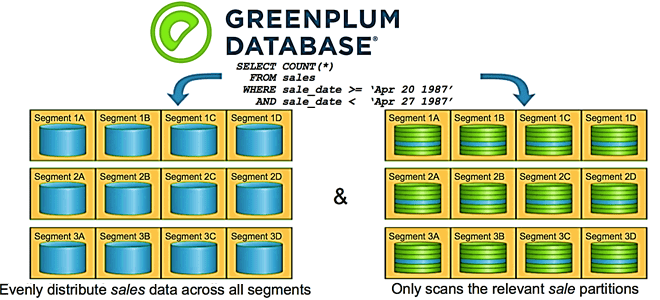
Мы уже рассказывали про основы хранения и аналитики больших данных в Greenplum, а также рассматривали особенности индексации и сжатия данных в этой MPP-СУБД. Продолжая разговор о нашем новом курсе «Greenplum для инженеров данных», сегодня разберем лучшие практики разбиения данных на разделы и пример их распределения по сегментам кластера. Кратко о...

В продолжение вчерашней статьи по нашему новому курсу «Greenplum для инженеров данных», сегодня рассмотрим особенности индексации и сжатия данных в этой MPP-СУБД. Читайте далее, почему в Greenplum можно обойтись без индексов, когда выбирать RLE-сжатие вместо zlib, зачем сжимать рабочие файлы при выполнении SQL-запросов и что такое селективность индекса. ТОП-10 советов по...

Продвигая наш новый курс «Greenplum для инженеров данных», сегодня мы рассмотрим особенности организации таблиц в этой MPP-СУБД, типы данных и оптимальное расположение столбцов. Читайте далее, чем heap storage отличается от append-optimized, когда выбирать колоночную, а когда – строковую модель хранения данных для таблицы, почему BIGINT с TIMESTAMP следует размещать перед...

Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера разберем кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS...

В этой статье рассмотрим, как сделать SQL-запросы к колоночному хранилищу больших данных с поддержкой ACID-транзакций Delta Lake еще быстрее с помощью Apache Presto. Читайте далее про синергию совместного использования Apache Spark и Presto в Delta Lake для ускорения OLAP-процессов при работе с Big Data. Еще раз об OLAP: схема звезды...

Интерактивная аналитика больших данных - одно из самых востребованных и коммерциализированных приложений для технологий Big Data. В этой статье мы рассмотрим, как крупный британский ритейлер запустил цифровую трансформацию своей ИТ-архитектуры, уходя от традиционного DWH с пакетной обработкой к событийно-стриминговой облачной платформе на базе Apache Kafka и Snowflake. Зачем модному ритейлеру...

Чтобы добавить в наши курсы для дата-инженеров еще больше реальных примеров и лучших DataOps-практик, сегодня мы расскажем, как специалисты крупной норвежской компании DNB обеспечивают надежный доступ к чистым и точным массивам Big Data, применяя передовые методы проектирования данных и реализации конвейеров их обработки. В этой статье мы собрали для вас...

Аналитика больших данных напрямую связана с их качеством, которое необходимо отслеживать на каждом этапе непрерывного конвейера их обработки (Pipeline). Сегодня рассмотрим методы и средства обеспечения Data Quality на примере корпорации Airbnb. Читайте далее про лучшие практики повышения качества больших данных от компании-разработчика самого популярного DataOps-инструмента в мире Big Data, Apache...

В этой статье мы поговорим про возможность нехарактерного использования Apache Kafka: не как распределенной стримминговой платформы или брокера сообщений, а в виде базы данных. Читайте далее, как Apache Kafka дополняет другие СУБД, не заменяя их полностью, почему такой вариант использования возможен в Big Data и когда он не совсем корректен....

В этой статье разберем кейс построения экосистемы управления Big Data с озером данных на примере федеральной фармацевтической сети - российской Ассоциации независимых аптек (АСНА). Читайте в этом материале, зачем фармацевтическому ритейлеру большие данные, с какими трудностями столкнулся этот проект цифровизации и как открытые технологии (Arenadata Hadoop, Apache Spark, NiFi и...

Мы уже затрагивали тему корпоративных хранилищ данных (КХД), управления мастер-данными и нормативно-справочной информаций (НСИ) в контексте технологий Big Data. В продолжение этого, сегодня рассмотрим, что такое профилирование данных, зачем это нужно, при чем тут озера данных (Data Lake) и ETL-процессы, а также прочие аспекты инженерии и аналитики больших данных. Что...