Как включить сжатие данных в Greenplum, какие алгоритмы сжатия поддерживает эта MPP-СУБД и можно ли установить разные параметры сжатия для отдельных столбцов и разделов больших таблиц. Примеры SQL-запросов и рекомендацию по настройке. Как Greenplum сжимает данные: примеры настроек и SQL-запросов Эффективное сжатие данных позволяет Greenplum снижать потребление памяти и повышать...

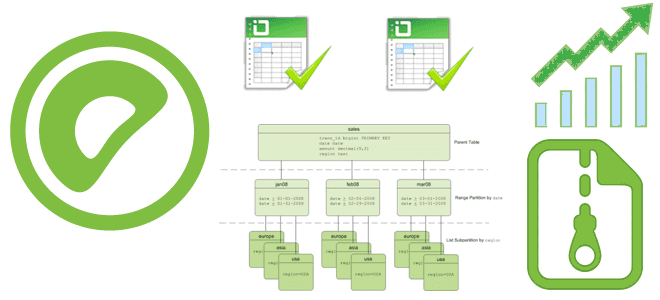
Почему в Greenplum 7 восстановление данных из резервной копии базы стало медленнее и как разработчики это исправили: причины замедления и способы их устранения. SQL-синтаксис и восстановление из бэкапа Напомним, 7-ой релиз Greenplum имеет много интересных и полезных функций, включая возможность определять партиционированную таблицу без определения дочерних разделов и изменять таблицы...

Сегодня рассмотрим, какие системные метрики Greenplum необходимо отслеживать администратору кластера и дата-инженеру для оценки работоспособности и эффективности этой СУБД, а также с помощью каких инструментов это сделать. Мониторинг средствами Greenplum Прежде всего, стоит отметить, что контролировать Greenplum можно с помощью различных инструментов, включенных в систему или доступных в качестве надстроек....
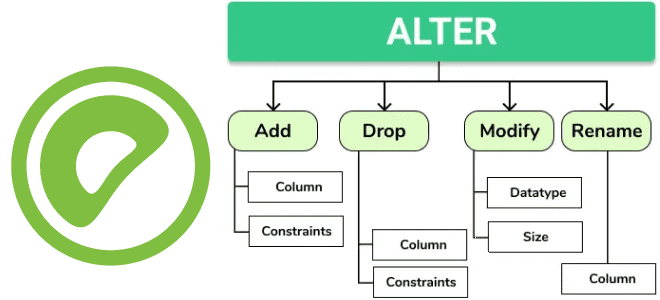
Какие команды изменения таблиц добавлены в 7-ю версию Greenplum и чем они полезны дата-инженеру. Разбираемся с новыми функциями: как добавить столбец, изменить его тип, кодировку хранения и перезаписать несколько таблиц одной командой. Добавление столбца О новых функциях работы с партиционированаными таблицами в Greenplum 7 мы уже писали. В частности, Greenplum...

Как расширить возможности MPP-СУБД Greenplum, используя фоновые рабочие процессы и почему это небезопасно. А также рассмотрим, что такое API Greenplum Partner Connector и как это использовать. Фоновые рабочие процессы Обычно фоновыми процессами в СУБД называются системные задания, которые запускаются при запуске базы данных и выполняют различные служебные задачи. К таким рутинным сервисным задачам...
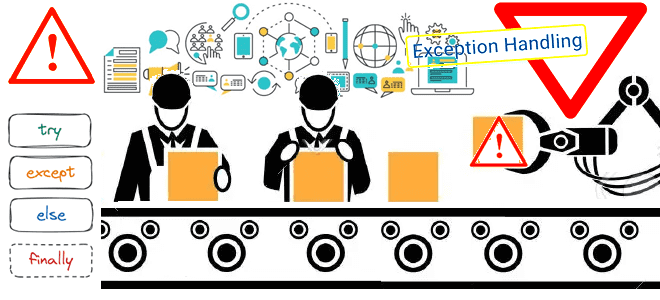
Сегодня поговорим о том, как обработка исключений позволяет спроектировать и реализовать надежную архитектуру конвейера обработки данных, включая ETL/ELT-процессы и их компоненты. Архитектура конвейеров обработки данных: ETL/ELT-процессы Наличие хорошо спроектированной инфраструктуры данных необходимо для получения максимальной отдачи от данных для data-driven управления. Поскольку данные постоянно увеличиваются в объеме, следует организовать управление...
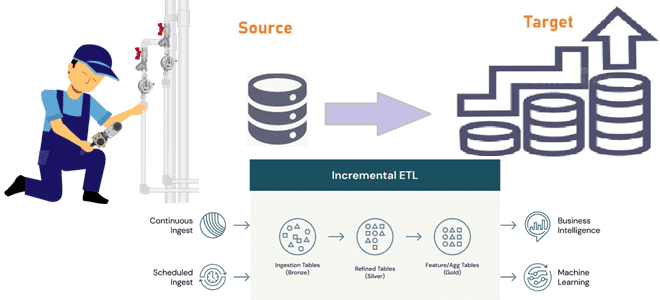
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
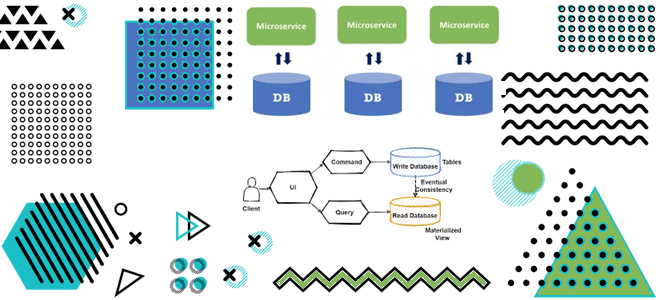
Как материализованные представления в потоковой базе данных с CDC-подходом и шаблоном CQRS позволяют реализовать масштабируемую и высокопроизводительную систему с микросервисной архитектурой для транзакций и аналитики данных в реальном времени. Разбираемся с паттернами проектирования микросервисов на примере интернет-магазина. Что не так с шаблоном композиция API и другие проблемы микросервисной архитектуры в...
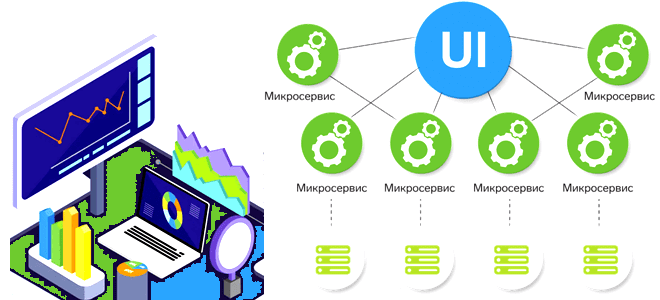
Сегодня разберем проблемы микросервисной архитектуры для платформ данных и способы их решения, а также вспомним 5 популярных шаблонов развертывания, которые могут смягчить риски от внедрения новых версий многокомпонентной системы. Проблемы микросервисной архитектуры для платформы данных и способы их решения При всех плюсах микросервисной архитектуры (автономность, гибкость, масштабируемость, простота развертывания, технологическая...
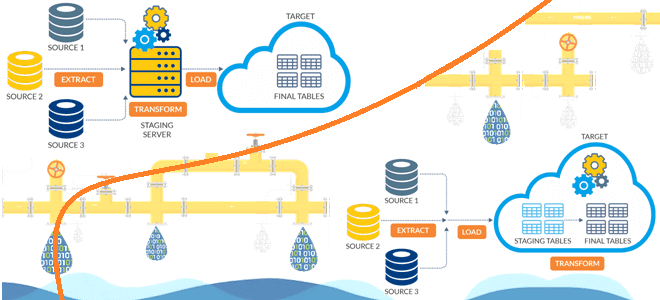
Чем динамичный ELT-подход лучше традиционного ETL, в чем разница между этими архитектурами конвейеров данных и зачем нужно профилирование данных при построении высокоэффективных дата-пайплайнов. Чем ETL отличается от ELT: ликбез для дата-инженера Аналитика больших данных невозможна без ETL/ELT-процессов, т.е. извлечения данных из разных источников (базы данных, файлы, API, прикладные системы), их...
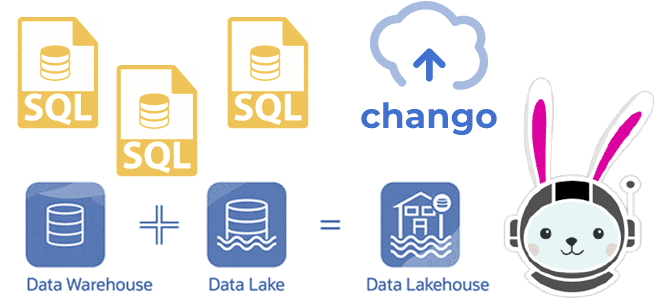
Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий. Что такое Trino: принципы работы распределенного SQL-движка О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь,...

Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...
В этой статье для обучения дата-инженеров рассмотрим, как организовать сбор измененных данных из реляционных СУБД, построив CDC-конвейер с помощью Apache NiFi. А также разберем, зачем процессоры этого потокового ETL-маршрутизатора используют технологию веб-хуков. ETL-конвейер для DWH и Data Lake В общем случае сбор данных из реляционных и нереляционных источников и построение...
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса. Витрины и хранилища данных Витрина данных (Data Mart) предоставляет информацию...

В этой статье для обучения ИТ-архитекторов и дата-инженеров сравним 2 подхода к аналитике больших данных, чтобы решить, когда потоковые вычисления, например, средствами ksqlDB в рамках Apache Kafka лучше аналитических баз данных реального времени, таких как Rockset, и наоборот. 2 способа выполнения аналитики больших данных в реальном времени Современный бизнес и...
Что не так с конвейерной моделью обработки данных и почему архитектура Data Mesh с потоковой передачей событий не решают всех проблем пакетной парадигмы. Зачем нужна новая архитектура данных под названием Мю, какие инструменты и принципы она использует для устранения технологической неоднородности отдельных технологий Big Data, а также при чем здесь...
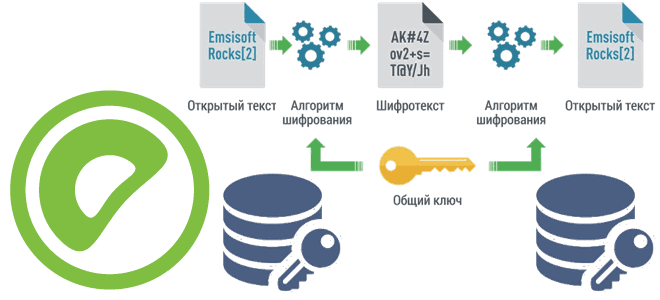
Чтобы сделать наши курсы по Greenplum еще более полезными для дата-инженеров и администраторов, сегодня познакомимся с pgcrypto – важным расширением этой MPP-СУБД, которое предоставляет криптографические функции, чтобы хранить некоторые столбцы данных в зашифрованном виде. Как установить расширение pgcrypto и использовать его для улучшения безопасности Greenplum. Шифрование данных в Greenplum База...

9 сентября 2022 года VMware Tanzu выпустили Greenplum 6.22. А спустя месяц, 7 октября вышел апгрейд этого релиза с исправлением ошибок. Разбираем, что нового в этих выпусках: полезные функции, улучшения и исправления ошибок, особенно важные для администратора кластера и дата-инженера. Greenplum 6.22.0 Сентябрьское обновление Greenplum 6.22.0 включает следующие функциональные возможности...

Недавно мы рассматривали тонкости проектирования схем данных в Greenplum. Продолжая разбирать важные для обучения дата-инженеров и архитекторов DWH темы, сегодня поговорим о том, как разделение и распределение данных влияют на скорость выполнения SQL-запросов в этой MPP-СУБД. Распределение данных Напомним, MPP-СУБД Greenplum широко используется в качестве OLAP-системы и корпоративного хранилища данных....