Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...

Чтобы сделать наши курсы по Apache Kafka для разработчиков Big Data систем еще более интересными, а обучение – запоминающимся, сегодня мы рассмотрим еще несколько примеров реализации микросервисной архитектуры на этой стриминговой платформе. А также поговорим про проблемы удаления данных в этой архитектурной модели, разобрав кейс компании Twitter по построению корпоративного...
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...
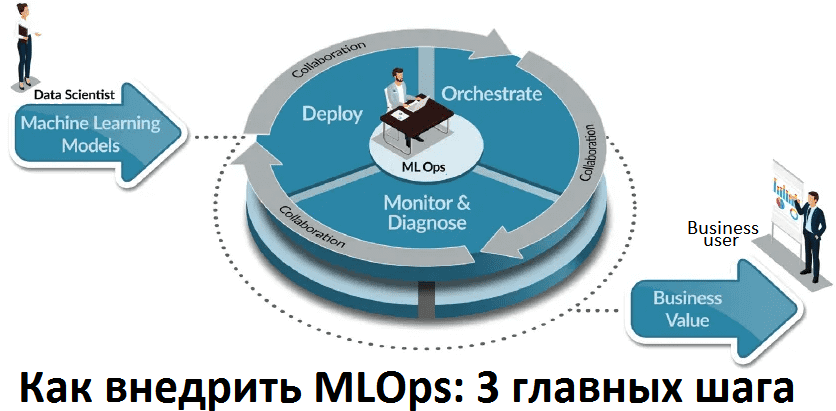
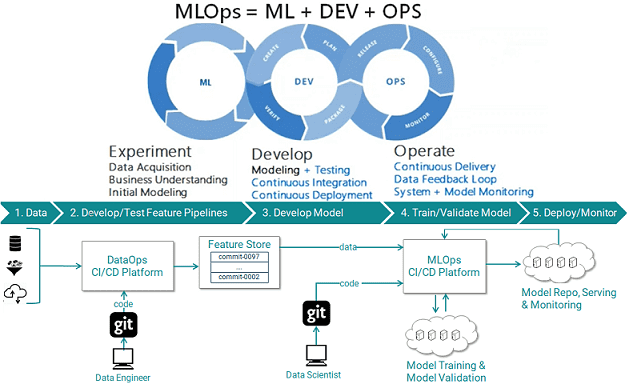
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production). 2 направления для...
Недавно мы рассказывали про модель зрелости MLOps от Google. Сегодня рассмотрим альтернативную методику оценки зрелости операций разработки и эксплуатации машинного обучения, которая больше похоже на наиболее популярную в области управленческого консалтинга модель CMMI, часто используемую в проектах цифровизации. Читайте далее, по каким критериям измеряется Machine Learning Operations Maturity Model и...
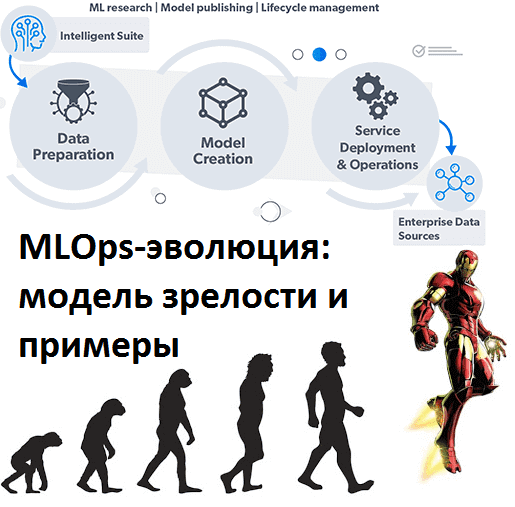
Цифровизация и запуск проектов Big Data предполагают некоторый уровень управленческой зрелости бизнеса, который обычно оценивается по модели CMMI. MLOps также требует предварительной готовности предприятия к базовым ценностям этой концепции. Читайте в нашей статье, что такое Machine Learning Operations Maturity Model – модель зрелости операций разработки и эксплуатации машинного обучения, из...
Пока цифровизация воплощает в жизнь концепцию DataOps, мир Big Data вводит новую парадигму – MLOps. Читайте в нашей статье, что такое MLOps, зачем это нужно бизнесу и какие специалисты потребуются при внедрении практик и инструментов сопровождения всех операций жизненного цикла моделей машинного обучения (Machine Learning Operations). Что такое MLOps, почему...

Продолжая разговор про обучение Spark на реальных примерах, сегодня мы рассмотрим, как работает этот Big Data фреймворк на Kubernetes, популярной DevOps-платформе автоматизированного управления контейнеризированными приложениями. Читайте в нашей статье, как запустить приложение Apache Spark в кластере Kubernetes (K8s) с помощью submit-скрипта и оператора, а также при чем здесь Docker-образ. Запуск...

Вчера мы рассказывали об основных сценариях запуска Apache Spark на Kubernetes и преимуществах этого варианта развертывания популярного Big Data фреймворка на DevOps-платформе автоматизированного управления контейнеризированными приложениями. Сегодня поговорим про обратную сторону всех этих преимуществ: читайте в нашей статье, каковы основные ограничения и главные недостатки запуска Apache Spark на Kubernetes (K8s)....
Чтобы сделать курсы по Spark еще более интересными и полезными, сегодня мы расскажем, зачем этот Big Data фреймворк разворачивают на Kubernetes (K8s) – платформе автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Читайте в нашей статье про основные варианты использования и достоинства этого подхода к администрированию и эксплуатации Apache Spark. Зачем...

Аутентификация – далеко не единственная возможность обеспечения информационной безопасности в Apache Kafka. Сегодня мы продолжим разговор про Big Data cybersecurity и рассмотрим особенности авторизации в Apache Kafka в формате самообслуживания (self-service), как это было сделано в travel-компании Booking.com. В качестве примера продолжим разбирать доклад Александра Миронова, который был представлен 23...

Сегодня мы разберем доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech [1]. Читайте в нашей статье, как одна из ведущих travel-компаний использует Apache Kafka, с какими проблемами столкнулись администраторы ее Big Data инфраструктуры и DevOps-инженеры, а также почему были выбраны именно такие...

Продолжая разговор про интеграцию информационных систем с помощью стриминговой платформы, сегодня мы рассмотрим преимущества event streaming архитектуры на примере Apache Kafka. Также читайте в нашей статье про 5 ключевых сценариев использования Кафка в потоковой обработке событий: от IoT/IIoT до микросервисного разделения в системах аналитики больших данных (Big Data) и машинного...

В этой статье поговорим про интеграцию информационных систем: обсудим SOA и ESB-подходы, рассмотрим стриминговую архитектуру и возможности Apache Kafka для организации быстрого и эффективного обмена данными между различными бизнес-приложениями. Также обсудим, что влияет на архитектуру интеграции корпоративных систем и распределенных Big Data приложений, что такое спагетти-структура и почему много сервисов...

В продолжение темы про проявление Agile-принципов в Big Data системах, сегодня мы рассмотрим, как DevOps-подход отражается в использовании Apache Kafka. Читайте в нашей статье про кластерную архитектуру коннекторов Кафка и KSQL – SQL-движка на основе API клиентской библиотеки Kafka Streams для аналитики больших данных, о которой мы рассказывали здесь. Из...

Ранее мы рассказывали, что общего между бережливым производством и DevOps. Сегодня рассмотрим, как 7 принципов Lean отражены в разработке программного обеспечения. Также читайте в нашей статье об актуальности методологии ITIL для проектов цифровизации и внедрения технологий больших данных (Big Data). 7 принципов Lean в ИТ Мы уже упоминали, что впервые...
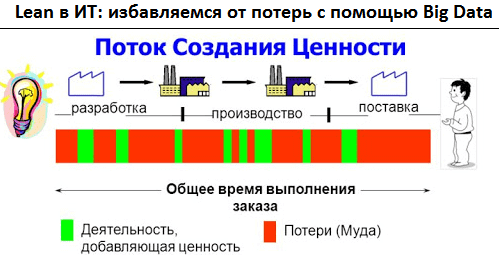
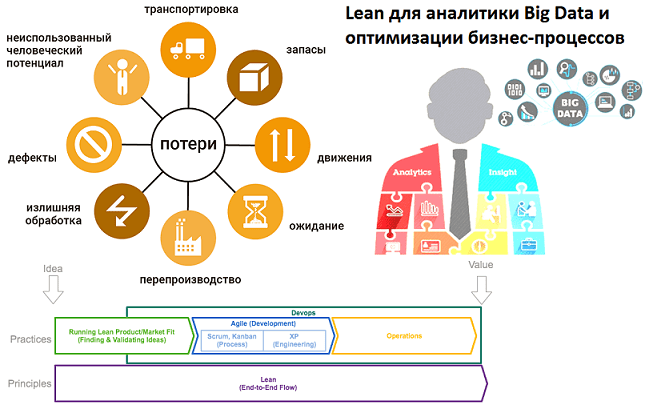
Продолжая разговор про бережливое производство в ИТ, сегодня мы рассмотрим виды потерь и источники их возникновения, а также поговорим, как принципы Lean помогают бизнесу избавиться от муда, мури и мура средствами больших данных (Big Data). 8 видов потерь в Lean с примерами из ИТ Прежде всего, поясним значение понятий муда,...
Не претендуя на лавры Мэри и Тома Поппендиков, которые впервые освятили применение Lean в разработке ПО, сегодня мы расскажем, как идеи бережливого производства реализуются в области Big Data. Читайте в нашей статье про принцип вытягивания в Apache Kafka, концепцию «точно вовремя» в Apache Spark, SMED в Kubernetes и облачных кластерах...
Чтобы сделать курс Аналитика больших данных для руководителей еще более интересным, мы продолжаем включать в него темы про методы производственной оптимизации. Сегодня рассмотрим, что такое бережливое производство (Lean) и почему Agile вообще и DevOps в частности активно используют принципы этой концепции. Также читайте в нашей статье, чем Lean отличается от системы...
Вчера мы рассмотрели, что такое функционально-стоимостный анализ (ФСА) и как этот метод позволяет оценить бизнес-процессы в денежном выражении. Однако, результаты ФСА, в первую очередь, ориентированы на оптимизацию с точки зрения финансов, а не организации и технологий. Исправить ситуацию помогут принципы бережливого производства (Lean). Сегодня мы расскажем об одном из них...