
Сегодня рассмотрим, с какими нетиповыми ошибками может столкнуться дата-инженер при работе с Apache Flink, а также как решить эти проблемы. Где и что править, когда сервер BLOB-объектов завис из-за слишком большого количества подключений, почему не хватает памяти при развертывании Flink-приложений в кластере Kubernetes и как ускорить инициализацию заданий. Особенности работы...

В этой статье для обучения дата-инженеров и архитекторов распределенных систем рассмотрим, что такое наблюдаемость, как ее измерить и при чем здесь стандарт OpenTelemetry. А в качестве примера разберем, как французский маркетплейс Cdiscount управляет почти 1000 микросервисов в кластере Kubernetes с Apache Kafka, Jaeger, Elasticsearch и OpenTelemetry. Наблюдаемость распределенной системы: стандарт...
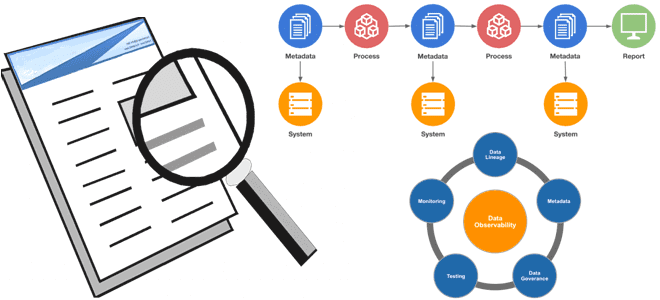
Сегодня рассмотрим, почему наблюдаемость данных так важная для проектов Big Data, какие компоненты обеспечивают ценную информацию о качестве и надежности данных, чем это похоже на DataOps, а также как эти идеи реализовать на практике с использованием популярных инструментов современной дата-инженерии. Почему важна наблюдаемость данных Цифровизация предполагает управление на основе качественных...
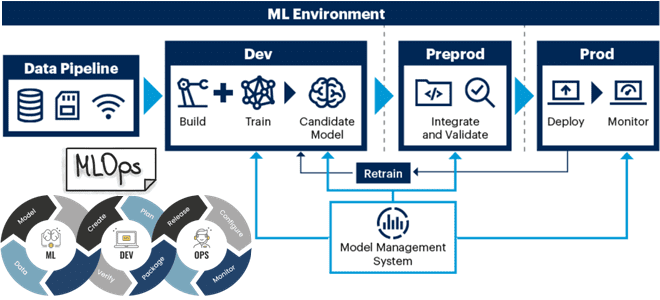
Что и насколько часто меняется в системах машинного обучения, почему необходимо отслеживать эти изменения и как MLOps помогает справиться с управлением ML-моделями, данными, кодом и инфраструктурой развертывания. Почему стек технологий MLOps такой разношерстный и какие инструменты выбирать для практического использования. MLOps для решения дрейфа данных и других проблем ML-систем Машинное...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...
Что не так с датасетами в системах машинного обучения, с какими трудностями сталкиваются аналитики, инженеры данных и специалисты по Data Science при внедрении MLOps, почему важна согласованность различных информационных хранилищ, зачем и как внедрять оперативный мониторинг за качеством данных. Разбираем трудности разработки и поддержки Machine Learning в production. 5 проблем...
Интеграция Apache Airflow с инструментами CI/CD является одной из лучших практик современной дата-инженерии, о чем мы недавно писали. Читайте далее, зачем нужно управлять кодом DAG с помощью популярных систем управления версиями и как это сделать на примере GitLab CI/CD. Сложности управления DAG в разных средах AirFlow Apache Airflow считается наиболее...
Зачем нужен мониторинг ML-систем в production, чем он отличается от простого отслеживания метрик ПО и при чем здесь MLOps. Как настроить телеметрию ML-приложений в New Relic: 5 простых шагов для специалистов по Machine Learning и дата-инженеров. Зачем нужен мониторинг ML-систем и при чем здесь MLOps В реальных системах машинного обучения...
Что такое непрерывное машинное обучение, как оно работает и при чем здесь MLOps. Почему сложно вести разработку ML-моделей в стиле CI/CD и как CML помогает обойти эти ограничения. Автоматизация процессов непрерывной интеграции и доставки с помощью open-source CLI-инструмента от Iterative.ai. Трудности CI/CD в Machine Learning и MLOps Поддерживаемые DevOps-концепцией идеи...

Недавно мы писали про сложности разработки и развертывания ML-систем и способы их решения с помощью концепции MLOps. Продолжая эту тему, важную для обучения специалистов по Data Science, аналитиков и инженеров данных, сегодня рассмотрим основные некоторые преимущества фреймворка MLFlow для создания надежных конвейеров CI/CD в системах машинного обучения. CI/CD в MLOps...

Продолжая разговор про оптимизацию приложений Apache Spark в Kubernetes, сегодня разберем, как сократить расходы на облачный кластер с помощью спотовых узлов. А в качестве практического примера рассмотрим кейс компании Weather2020, дата-инженеры которой смогли всего за 3 недели развернуть террабайтные ETL-конвейеры в AWS с AirFlow и Spark на Kubernetes без глубокой...

Недавно мы рассказывали об особенностях запуска приложений Apache Spark в кластере Kubernetes с учетом новшеств релиза 3.1.1, где с этого варианта развертывания снят экспериментальный режим. В дополнение к ранее рассмотренным способам оптимизации Спарк-приложений, сегодня разберем, как инженеру Big Data ускорить их при запуске на платформе K8s. Как ускорить Spark-приложения на...

Вчера мы упоминали, что с марта 2021 года в версии Apache Spark 3.1.1 с развертывания на Kubernetes снят экспериментальный режим, внесено множество улучшений для стабильной работы контейниризованных приложений и добавлены другие полезные обновления. Читайте далее, почему развертывание Spark на Kubernetes стало еще проще, как реализуется плавное завершение работы узла без...

С учетом тренда на контейнеризацию при разработке и развертывании любых технологий, в т.ч. Big Data, сегодня рассмотрим плюсы и минусы совместного использования Apache Spark с Kubernetes. Читайте далее, как отправить Спарк-задание в кластер Кубернетес и почему это сэкономит затраты на вашу инфраструктуру аналитики больших данных, не повысив производительность отдельных приложений,...
В этой статье поговорим про KSQL на примере кейса компании американской компании Pluralsight, которая предлагает различные обучающие видео-курсы для разработчиков ПО, ИТ-администраторов и творческих профессионалов. Читайте далее, как использовать Apache Kafka с Kubernetes для построения надежных систем потоковой аналитики больших данных, а также чем ksqlDB отличается от KSQL. Apache Kafka...

Вчера мы говорили про сложности развертывания множества stateful-приложений Apache Kafka Streams в кластере Kubernetes и роль контроллера StatefulSet, который поддерживает состояние реплицированных задач за пределами жизненного цикла отдельных подов. В продолжение этой темы, сегодня рассмотрим механизм проб, которые позволяют определить состояние распределенного приложения, развернутого на платформе контейнерной виртуализации. В качестве...
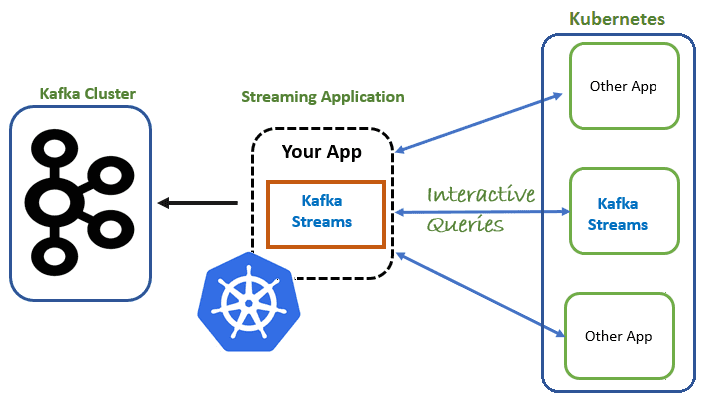
Сегодня рассмотрим особенности запуска приложений Apache Kafka Streams для потоковой обработки больших данных с отслеживанием состояния в кластере Kubernetes. Читайте далее, в чем проблема управления stateful-приложениями Kafka Streams в Kubernetes и как ее решает контроллер StatefulSet. Что обеспечивает хранение состояний в Apache Kafka Streams Напомним, Kafka Streams – это легковесная...

В этой статье разберем ключевые характеристики идеального конвейера обработки больших данных. Читайте далее, чем отличается Big Data Pipeline, а также какие приемы и технологии помогут инженеру данных спроектировать и реализовать его наиболее эффективным образом. В качестве практического примера рассмотрим кейс британской компании кибербезопасности Panaseer, которой удалось в 10 раз сократить...

Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka,...

Развивая наш новый курс по Apache Kafka для разработчиков, сегодня мы рассмотрим 3 способа о взаимодействии с этой популярной Big Data платформой потоковой обработки событий с помощью языка Python, который считается самым распространенным инструментом в Data Science. Читайте далее, что такое librdkafka, чем PyKafka отличается от Kafka-Python и почему решение...