
Можно ли применять Apache Spark Structured Streaming для пакетных заданий и в каких случаях это целесообразно. Разбираемся, как устроена потоковая передача событий в Spark Structured Streaming, с какой частотой разные режимы триггеров микропакетной обработки данных запускают потоковые вычисления и что выбрать дата-инженеру. Потоковая передача событий и пакетные задания: versus или...

Сегодня разберем распространенные трудности корпоративных платформ обработки и хранения Big Data, а также как избежать этих проблем, используя современные методы и средства проектирования дата-архитектур и инструменты инженерии данных. 7 главных проблем с платформами данных Обычно каждая data-driven компания органично развивает свои платформы данных, усложняя их архитектуры. Но этот процесс эволюционного...

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...

Сегодня мы продолжим говорить про Apache Spark Structured Streaming и его применение для обновления данных в таблицах Delta Lake. А также на практических примерах разберем, как выполняются основные операции работы с данными средствами Spark Structured Streaming API. Таблицы в Delta Lake Delta Lake – это уровня хранилища данных с открытым...

Продолжая недавний разговор про Apache Spark Structured Streaming, сегодня рассмотрим, как этот движок потоковой обработки данных помогает дата-инженеру реализовать идемпотентную запись в таблицы Delta Lake, а также выполнить операции слияния и обновления/вставки в помощью метода foreachBatch(). Идемпотентность потоковых приложений Apache Spark Идемпотентность – важное свойство распределенных систем, которое гарантирует, что...

Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...

Сегодня разберем, как автоматизировать наполнение озера данных на HDFS через загрузку таблиц из реляционной базы MySQL в Hive с помощью Apache NiFi. Какие процессоры NiFi следует использовать и зачем предварительно разделять таблицу Apache Hive. Пример ETL-конвейера на процессорах Apache NiFi Apache NiFi часто используется дата-инженерами в качестве средства автоматизации и...
Рассмотрим, как дата-инженеры Airbnb делятся своим опытом перевода корпоративного Data Lake на Apache HDFS в облачное объектное хранилище AWS S3. Почему пришлось переводить аналитические нагрузки с Apache Hive на Iceberg и Spark, и какие результаты это принесло. Предыстория: Data Lake на HDFS и Apache Hive Будучи крупнейшей онлайн-площадкой для размещения...

Data Mesh воплощает децентрализованный подход к построению распределенной архитектуры данных. При всех достоинствах этой модели, которая совмещает потоковую и пакетную парадигмы обработки данных, она еще довольно незрелая и имеет ряд недостатков. Одним из них является проблема с информационной безопасностью, что мы и рассмотрим далее для обучения ИТ-архитекторов и дата-инженеров. Безопасность...

Недавно мы рассматривали производительность ETL-конвейеров на Apache Spark с озером данных на MinIO. Сегодня разберем, чем это легковесное объектное хранилище отличается от распределенной файловой системы Apache Hadoop и как перейти на него с HDFS. Зачем переходить на MinIO Хотя HDFS до сих пор активно используется во многих Big Data проектах...
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения. Архитектурный дизайн Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности...
При том, что большинство современных озер данных представляют собой облачные объектные хранилища типа AWS S3, многие предприятия хранят данные в собственном кластере HDFS или даже MinIO. Поэтому сегодня специально для обучения дата-инженеров и ИТ-архитекторов рассмотрим, что представляет собой это хранилище и насколько хорошо с ним взаимодействует Apache Spark. Что такое...

В отличие от каменных зданий, архитектуры данных постоянно меняются. Сегодня рассмотрим новую архитектурную модель под названием BigLake, выпущенную Google весной 2022 года. Что это такое, как устроено, чем похоже на Lakehouse, озеро данных и Data Mesh, а также чем от них отличается и какую пользу несет для конвейеров аналитики Big...

Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза. Как работает LakeSoul: краткий обзор Напомним, LakeSoul от команды DMetaSoul представляет собой...

Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и...
Специально для обучения дата-инженеров и архитекторов DWH сегодня разберем, как построить LakeHouse на Greenplum и объектном хранилище Cloudian HyperStore, совместимом с AWS S3. Что такое Cloudian HyperStore Object Storage, как оно совмещается с Greenplum и при чем здесь Apache Cassandra с интеграционным фреймворком PXF. Что такое объектное хранилище Cloudian HyperStore...
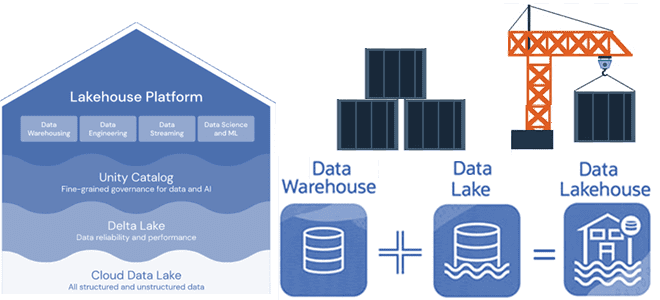
Недавно мы писали про новую гибридную архитектуру Lakehouse, которая объединяет лучше из мира озер и хранилищ данных. Сегодня разберем принципы работы и особенности построения этой архитектуры данных, включая технологии ее реализации с точки зрения дата-инженера и уделим внимание организации конвейеров аналитики больших данных. Архитектурная парадигма Lakehouse Напомним, Lakehouse — это...
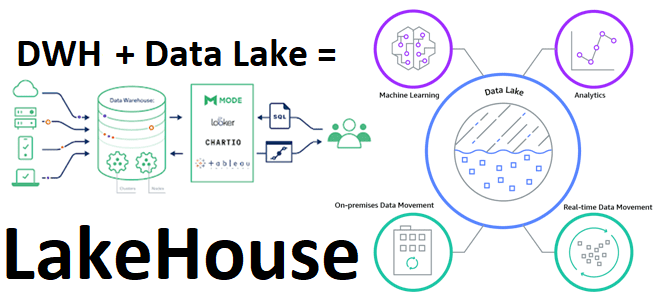
В рамках обучения дата-инженеров и архитекторов корпоративных платформ и приложений аналитики больших данных, сегодня рассмотрим, что такое LakeHouse. Как эта новая гибридная архитектура управления данными объединяет 2 разнонаправленные парадигмы хранения информации, а также чего от нее ожидают бизнес-пользователи, дата-инженеры, аналитики и ML- специалисты. Историческая справка: от DWH к Data Lake...

Продолжая рассматривать примеры для обучения дата-инженеров по построению ETL-конвейеров, сегодня разберем, как перенести данные из облачного объектного хранилища AWS S3 в озеро данных на Hadoop HDFS с помощью готовых процессоров Apache NiFi. Такой кейс актуален для многих предприятий, которым необходимо мигрировать с сервисов Amazon в другие хранилища больших данных. Перенос...

Сегодня рассмотрим кейс международной ИТ-компании AppsFlyer, которая создает SaaS-решения для маркетинговой аналитики в режиме онлайн. В этой статье команда разработки аналитического продукта Data Locker делится опытом оптимизации ETL-приложений Apache Spark для снижения стоимости обработки данных и ускорения вычислений. Предыстория: слишком много файлов в ETL-решении на Spark и AWS S3 в...