Для чего разработчику Flink-приложения инструменты профилирования, и почему надо избегать сериализации Kryo и динамической загрузки классов. Используйте инструменты профилирования Разработка и отладка высоконагруженных приложений требует специальных средств, позволяющих понять причины их медленной работы и повысить производительность. Такой анализ работы приложение называется профилированием и выполняется с помощью специальных средств – инструментов...

Продолжая тему недавней статьи про настройки Greenplum 7, сегодня рассмотрим еще несколько конфигураций, которые позволят сделать эту MPP-СУБД еще быстрее и надежнее. Глобальные конфигурации Greenplum для настройки рабочих файлов Параметры глобальной конфигурации пользователя (GUC, Global User Configuration) Greenplum могут быть как глобальными, так и локальными по отношению к экземплярам сегмента. Глобальные...
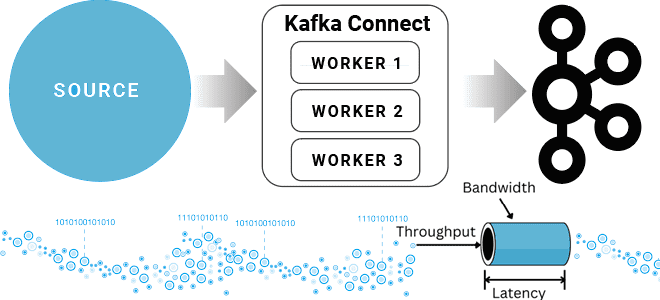
Компоненты платформы Kafka Connect и их настройки для повышения скорости и объема данных, считываемых из внешних источников и публикуемых в топике Kafka. Разбираем на примере JDBC-коннектора для реляционной базы данных. Проблемы и возможности коннекторов Kafka Connect Kafka Connect — это инструмент интеграции данных с открытым исходным кодом, который упрощает процесс...
Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей. Что такое Databricks SQL Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ...
Зачем настраивать конфигурацию конвейера Flink-приложений в зависимости от рабочей нагрузки и как это сделать: примеры и рекомендации. 3 вида рабочей нагрузки в потоковых конвейерах Конвейер потоковой передачи событий может реализовывать различные сценарии: обратная засыпка (backfilling), когда конвейер потребляет все исторические данные, считывая все сообщения, доступные во входных источниках, пока не...

Что настроить в Greenplum 7, чтобы сделать эту MPP-СУБД еще эффективнее. Обзор наиболее популярных параметров конфигурации и рекомендации по установке их значений. Ограничения подключений и выполнения SQL-запросов: 6 параметров с перезагрузкой системы Будучи зрелой системой со множеством настроек, Greenplum предоставляет администратору и дата-инженеру широкие возможности по адаптации этой СУБД к...

С версии 3.5.0Apache Spark поддерживает Datasketches – программную библиотеку стохастических потоковых алгоритмов. Разбираемся, что это такое, и при чем здесь алгоритм HyperLogLog. Что такое Apache Datasketches и зачем это нужно В аналитике больших данных часто возникают проблемные запросы, которые не масштабируются, поскольку требуют огромных вычислительных ресурсов и времени для получения...
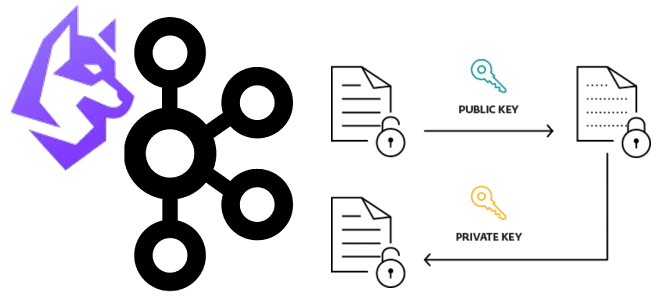
Недавно мы рассматривали пример шифрования полезной нагрузки с чувствительными данными на стороне продюсера и их расшифровку на потребителе Apache Kafka. Такой примитивный способ подходит для интеграции нескольких приложений, но в больших масштабах становится очень неудобным. Читайте, как Conduktor Gateway для Apache Kafka поможет выйти из этой ситуации, обеспечив защиту конфиденциальных...

Как использовать Greenplum в проектах машинного обучения: знакомимся с расширением PostgresML и модулем pgvector. Возможности и ограничения плагинов, превращающих MPP-СУБД в полноценный MLOps-инструмент. Как превратить Greenplum в векторную базу данных с расширением pgvector Будучи вариацией PostgreSQL с механизмами массово-параллельной загрузки, Greenplum отлично справляется с огромным объемом данных. Однако, к хранилищам...
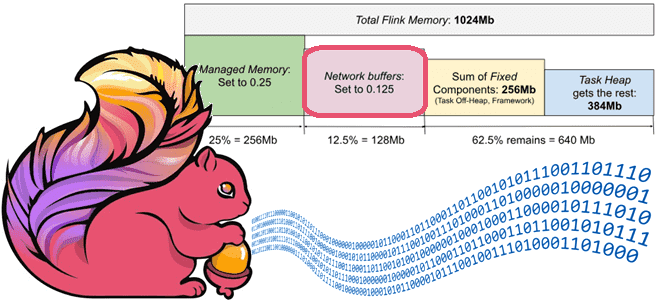
Как Apache Flink обеспечивает стабильно высокую пропускную способность потоковой обработки данных с помощью сетевых буферов и контрольных точек, каковы возможности и ограничения этих механизмов и какие конфигурации надо настроить для их эффективного использования. Зачем Apache Flink нужны сетевые буферы Каждая запись в Flink отправляется следующей подзадаче вместе с другими записями...
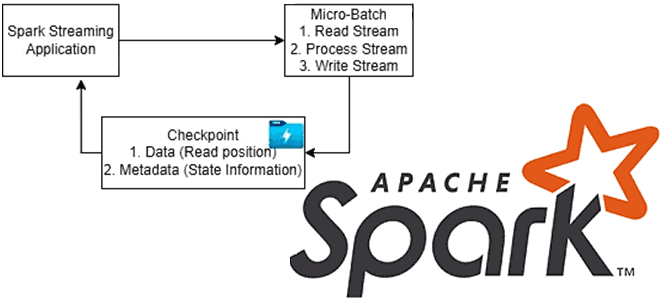
Чтобы обеспечить отказоустойчивость потоковых приложений, Apache Spark использует механизм контрольных точек. Какие они бывают, когда их включать и как настроить для эффективной работы. Что такое checkpoint в Apache Spark и зачем он нужен Чтобы приложение потоковой передачи было устойчиво к сбоям по внешним причинам, например, отказ JVM, Spark Streaming сохраняет...
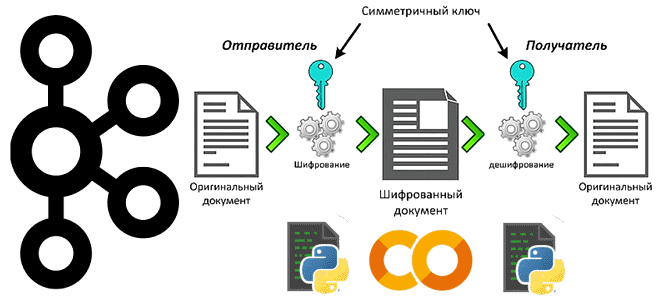
Простой пример шифрования полезной нагрузки с чувствительными данными на стороне продюсера и их расшифровка на потребителе Apache Kafka: пишем и запускаем Python-код в Google Colab. Публикация данных в Kafka: шифрование на стороне продюсера Apache Kafka часто используется для обмена данными между несколькими системами внутри предприятия. Однако, даже при работе во...

Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks. Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake В озере данных физическое расположение данных может оказать...

Как выбирать политики распределения и разделения данных в Greenplum, в чем польза динамического сканирования индексов, зачем регулярно использовать операции VACUUM и ANALYZE, из-за чего тормозят SQL-запросы и как это исправить. Эффективное распределение и разделение Будучи основанной на PostgreSQL, Greenplum расширяет возможности этой замечательной СУБД, добавляя операции с массово-параллельной обработкой. Для...

Насколько быстро работает Apache Kafka в облачной платформе Upstash: пишем простой пример для пары продюсер-потребитель на Python и измеряем задержку. Миллисекундное отставание при публикации и минутная задержка обработки данных на потребителе. Задержка публикации сообщений в Kafka Чтобы измерить задержку асинхронного обмена данными в системе с EDA-архитектурой из продюсера и потребителя...

Каждому специалисту по Data Science и инженеру данных знакома Python-библиотека pandas. Однако, для работы с большими данными она не очень подходит из-за высокого потребления памяти. Тем не менее, отказаться от старых привычек сложно. Поэтому разбираемся, зачем использовать API Pandas в Apache Spark и как это сделать наиболее эффективно. Чем отличается...

Зачем делать моментальные снимки состояния распределенной файловой системы Apache Hadoop, почему не стоит создавать снапшоты HDFS в корневом каталоге и как найти оптимальную частоту сохранения состояния больших данных. Как устроен механизм снапшотов в HDFS Чтобы повысить надежность системы, ее состояние необходимо периодически сохранять. Для баз данных и файловых систем эта...
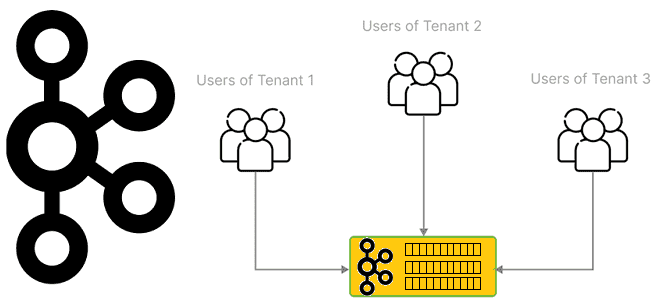
Что такое мультитенантность и как администратору Apache Kafka настроить изоляцию арендаторов в мультиарендном кластере: конфигурации, квоты и лайфхаки. Что такое мультиарендность и как реализовать эту модель для кластера Kafka Мультитенантность (мультитенантность, multitenancy) переводится с английского как множественная аренда и в контексте архитектуры ПО означает разделение одного экземпляра приложения между несколькими...

Зачем Apache Flink очередной API для создания распределенных приложений с отслеживанием состояния, чем он полезен и при чем здесь Kubernetes: ликбез по Stateful Functions. Apache Flink Stateful Functions Stateful Functions в Apache Flink – это API, который упрощает создание распределенных приложений с отслеживанием состояния с помощью среды выполнения, созданной для...
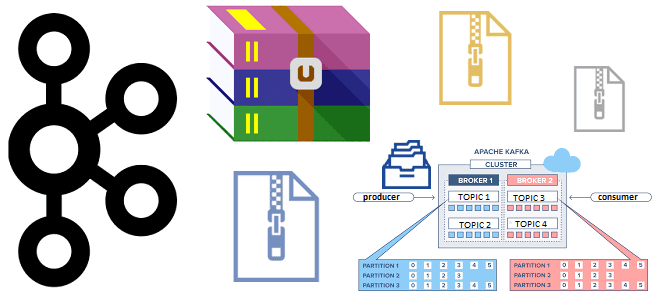
Зачем сжимать сообщения при их публикации в Apache Kafka, как устроен механизм сжатия и какие конфигурации задавать для его эффективного использования. Сжатие сообщений в Kafka: причины использования и принципы работы Единицей параллелизма в Apache Kafka является раздел топика, куда приложение-продюсер отправляет сообщение, чтобы его мог считать потребитель, назначенный на этот...