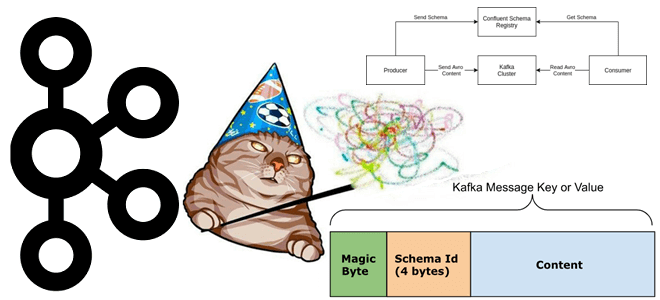
Что такое неизвестный магический байт, почему возникает эта ошибка и как предупредить такое исключение сериализации при работе с Kafka Streams, клиентами Apache Kafka и реестром схем. Что такое магический байт в сообщении Чтобы корректно обработать на стороне потребителя сообщение, считанное из Kafka, необходимо знать его формат, поскольку данные, публикуемые приложением-продюсером...
Что такое барьерный режим выполнения в Apache Spark, чем он отличается от вычислительной модели MapReduce, как связан с глубоким машинным обучением и где используется на практике. Что такое барьерный режим выполнения в Apache Spark Способ выполнения заданий Spark определяется режимом выполнения приложения, заданным на уровне фреймворка. На платформе. Именно от...
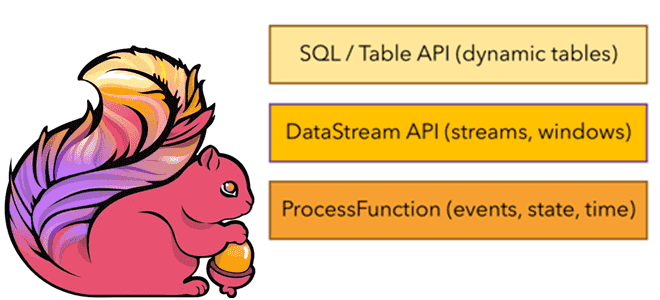
Какие возможности Apache Flink предоставляет разработчику и как их использовать: краткий обзор существующих API и потоковых примитивов. Потоковые примитивы и низкоуровневый API Будучи популярным фреймворком для stateful-вычислений над неограниченными и ограниченными потоками данных, Apache Flink предоставляет несколько API на разных уровнях абстракции и предлагает специальные библиотеки для различных сценариев. На...
Какие меры принять администратору кластера Apache Kafka, чтобы повысить надежность потоковой экосистемы, использующей эту распределенную платформу как средство интеграции различных приложений. Сбои в потоковой экосистеме и способы их устранения Хотя Apache Kafka считается высоконадежной системой благодаря множеству встроенных механизмов отказоустойчивости, таким как репликация и перевыборы лидера. Впрочем, это не исключает...
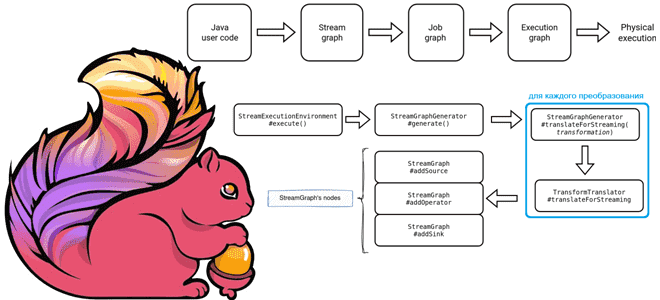
Как планируются и исполняются задания Apache Flink: от пользовательского Java-кода до физического исполнения, а также отслеживание статуса задания в JobManager. Подробности преобразований с примерами кода. 3 этапа преобразования задания Apache Flink Задание Apache Flink проходит несколько этапов перед своим физическим выполнением: сперва пользовательский код преобразуется в потоковый граф (Stream Graph);...
Когда и зачем Spark-приложение создает файл _SUCCESS, почему в нем нет данных, как его использовать, можно ли обойтись без него и как это сделать. Пример запуска PySpark-приложения в Google Colab. Когда и зачем Spark-приложение создает файл _SUCCESS В Apache Spark при выполнении операций записи с использованием таких методов, как saveAsTextFile(),...
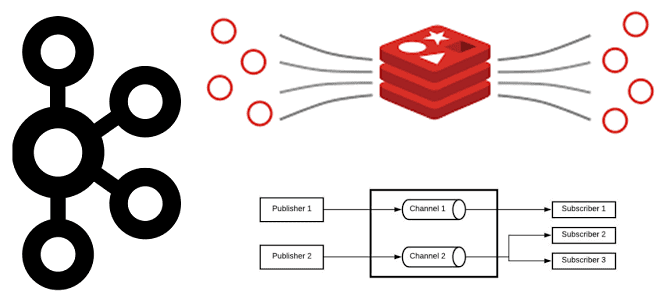
Как key-value СУБД Redis может работать с потоковыми данными и чем Pub/Sub и Streams отличаются от Apache Kafka. Сравнение и рекомендации по использованию. Потоковое сохранение данных Redis Будучи очень быстрым key-value хранилищем, NoSQL-СУБД Redis часто используется в качестве слоя кэширования для разгрузки основной базы данных. В отличие от многих других...

Насколько быстро ClickHouse выполняет SQL-запросы: тестирование СУБД в открытой онлайн-песочнице. Примеры запросов и время их выполнения. Работа с онлайн-песочницей Clickhouse: выполнение SQL-запросов Будучи реляционной аналитической СУБД, ClickHouse позволяет обрабатывать гигабайты данных в реальном времени. Архитектурные особенности, благодаря которым реализуется такая скорость, мы недавно разбирали здесь. Чтобы оценить это на практике,...

Сходства и различия популярных реляционных аналитических СУБД с открытым исходным кодом: что общего у Greenplum с ClickHouse, чем они отличаются, что и когда выбирать. Greenplum и Clickhouse: обзор возможностей для аналитики больших данных Обе СУБД являются реляционными и относятся к классу OLAP-систем, т.е. ориентированы на аналитические варианты использования, т.е. чтение...
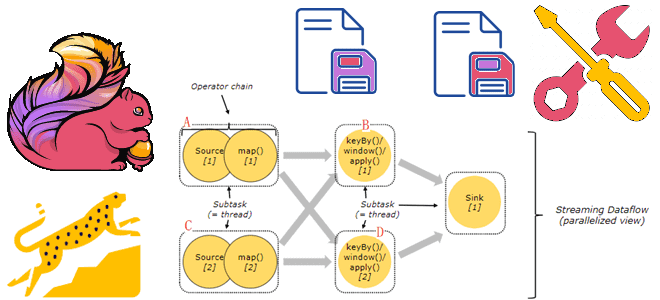
Почему хранить состояния Flink-приложений лучше на локальных SSD-диски, а не на твердотельных накопителях с удаленной файловой системой NFS или HDFS, зачем отключать блочный кэш RocksDB и как настроить параллелизм заданий. Проблемы сохранения состояния в RocksDB и способы их решения Как мы уже упоминали здесь, key-value хранилище RocksDB является самым популярным...
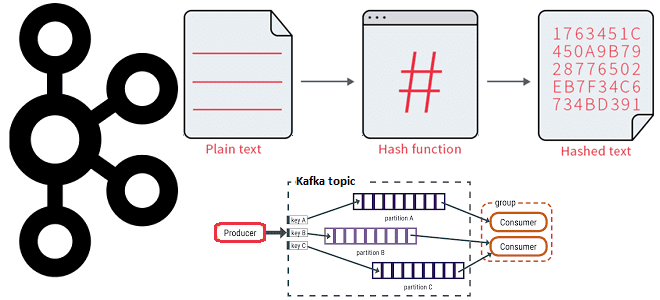
Как работает распределение сообщений по разделам топика Kafka с явно заданным ключом партиционирования и на что влияет язык разработки приложения-продюсера при использовании этой стратегии. 3 стратегии распределения сообщений по разделам в Apache Kafka В Apache Kafka единицей параллелизма выступает раздел топика. Используя несколько разделов, можно распределять нагрузку на брокеров в...
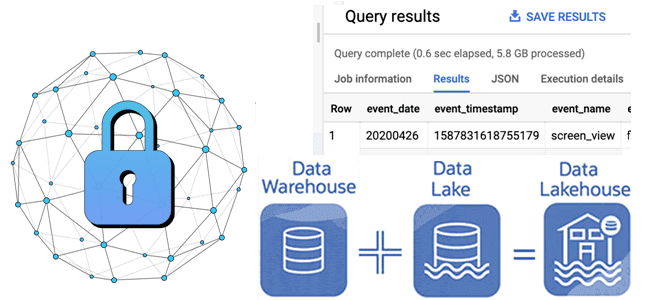
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...

Как управлять средой PySpark-приложения в распределенной вычислительной среде: проблемы зависимостей Python в кластере и способы их решения с помощью сеансов Spark Connect в версии 3.5.0. Управление зависимостями в Python и PySpark Каждый Python-разработчик хотя бы раз сталкивался с проблемой несовместимости пакетов. Эта ситуация называется ад зависимостей (dependency hell), когда вновь...

24 октября 2023 года вышел очередной релиз Apache Flink. Знакомимся с главными новинками популярного Big Data фреймворка для разработки потоковых stateful-приложений: JDBC-драйвер для SQL-шлюза, хранимые процедуры для коннекторов, расширенная поддержка SQL, динамическое масштабирование с REST API и RocksDB, улучшение пакетных операций, а также другие полезные фичи Apache Flink 1.18. Улучшения...
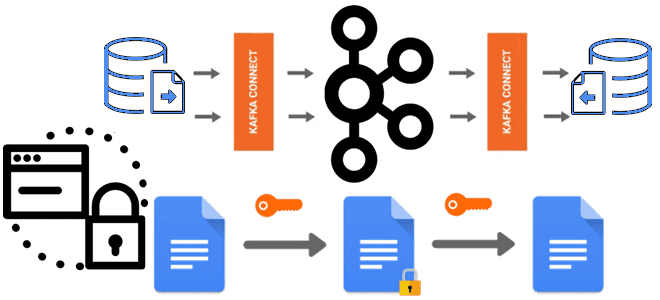
О важности шифрования чувствительных данных, публикуемых в Apache Kafka, мы недавно писали здесь и здесь. В продолжение этой темы сегодня познакомимся с Kryptonite – open-source библиотекой для сквозного шифрования на уровне полей для Apache Kafka Connect. Шифрование данных вне брокеров Apache Kafka: зачем это нужно Apache Kafka поддерживает несколько функций...
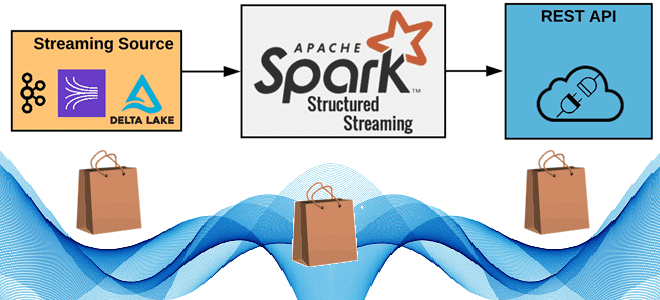
Как реализовать потоковую публикацию данных из приложения Apache Spark Structured Streaming во внешний REST API, используя метод foreachBatch(), зачем перераспределять датафрейм перед его упаковкой в полезную нагрузку HTTP-запроса, от чего зависит число вызовов, и какие приемы помогут избежать сбоев из-за ошибок. 6 шагов потоковой публикации данных в REST API с...

Продолжая недавний разговор про настройку конвейеров из Flink-приложений, сегодня рассмотрим, почему важна локальность данных, как избежать узких мест в приемниках потоковых данных и чем хорош HybridSource для объединения гетерогенных источников. Обеспечьте локальность данных Хотя распределенные системы обладают большим потенциалом по сравнению с локальными, позволяя обрабатывать больше данных, вычисления не происходят...

10 октября 2023 года вышел очередной релиз самой популярной распределенной платформы потоковой передачи событий. Знакомимся с главными новинками Apache Kafka 3.6.0: промышленная поддержка KRaft вместо ZooKeeper, оптимизация транзакций, повышение производительности памяти и другие фичи свежего релиза для разработчика, дата-инженера и администратора. ТОП-10 новинок выпуска 3.6 Apache Kafka 3.6.0 включает 6...
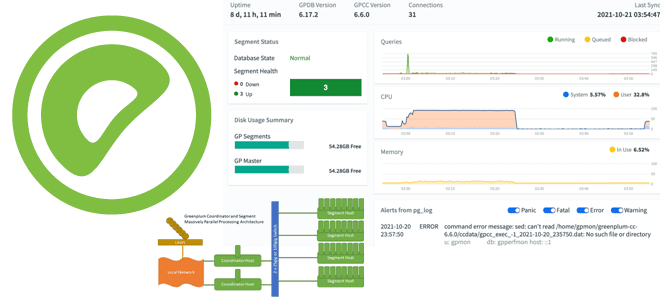
Что такое VMware Greenplum Command Center, как использовать этот инструмент для эффективного управления MPP-СУБД и чем он отличается от Arenadata Command Center для Arenadata DB. Что такое центр управления Greenplum от VMware VMware Greenplum Command Center — это инструмент управления, который отслеживает показатели производительности системы, анализирует состояние кластера и позволяет...
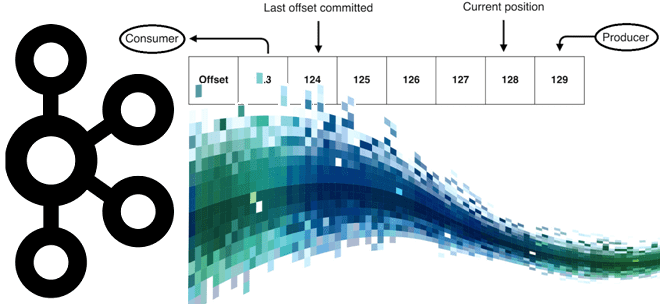
Чем политика сброса смещения earliest отличается от latest в конфигурации auto.offset.reset, зачем устанавливать свойству enable.auto.commit значение false и чем потребитель Java отличается от клиентов на основе librdkafka (C/C++, Python, Go и C#). Конфигурации Apache Kafka для управления смещением Потребитель Apache Kafka — это клиентское приложение, которое подписывается на весь топик...