
Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google....
Чтобы добавить в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как построить конвейер преобразования CSV-файлов и загрузить данные в масштабируемую NoSQL-СУБД GridDB с помощью Apache NiFi. Краткий ликбез по GridDB и Apache NiFi в кейсе построения ML-системы для анализа данных временных рядов. Анализ данных временных рядов c...
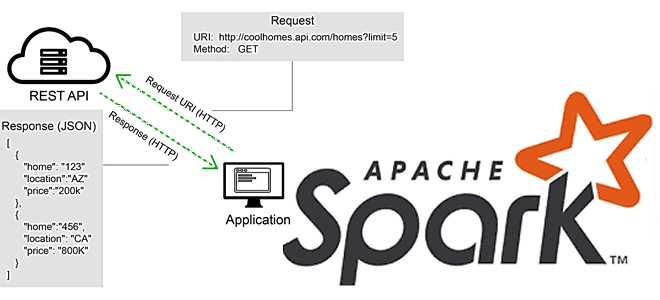
В этой статье для разработчиков Apache Spark разберем, что не так с вызовами REST API в этом фреймворке, и как решить эту проблему с помощью готовых библиотек или создания собственных UDF-функций на PySpark и не только. Для наглядности рассмотрим практический пример вызова REST API на PySpark с библиотекой Rest Data...

Постоянно обновляя наши курсы по Apache Kafka, сегодня рассмотрим еще один полезный инструмент для администраторов, дата-инженеров и разработчиков, который повышает эффективность взаимодействия с этой распределенной платформой потоковой обработки событий. Что такое Saamsa, какие проблемы Kafka она решает и как ее использовать на практике. 5 вопросов разработчика и дата-инженера к Apache...
Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с...

Рассмотрим пока еще фантастический пример из ближайшего будущего, где вся информация структурирована в виде графа знаний, доступ к сегментам которого определяется принадлежностью человека или машины к конкретной партии или корпорации. Как построить справочник организаций с помощью ИИ и графовой аналитики больших данных. Постановка задачи: построение справочника организаций Систематизация и упорядочивание...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим работу Data Science исследователей из Пизанского университета и сотрудников крупного ритейлера H&M по анализу данных торгового ассортимента компании с помощью ML-моделей на графах. Читайте далее, как машинное обучение на графовых нейросетях автоматизирует подбор сочетаемых предметов одежды и...

Сегодня разберем типовые ошибки, которые часто возникают в системах аналитики больших данных на базе Apache Hadoop YARN, Spark и RESTful-интерфейсу Livy, а также каким образом их избежать. В качестве практического примера используем ранее рассмотренный кейс интерактивной аналитики о пользовательском поведении в фотохостинге Pinterest. Интерактивная аналитика больших данных в Pinterest Недавно...

Недавно мы писали про платформы потоковой обработки событий, альтернативные Apache Kafka и Flink/Spark Streaming. В продолжение этой темы сегодня рассмотрим еще пару вариантов для разработки и самообслуживаемого использования потоковых конвейеров аналитики больших данных: DataCater и Flow. Читайте далее, что это за системы, как они связаны с Apache Kafka и какова...

В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL. Еще...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое DataStax Enterprise Graph. Читайте далее, как немецкая ИТ-компания Traversals с помощью этой распределенной графовой СУБД построила масштабное аналитическое решение для кибербезопасности, обнаружения мошенничества, анализа конкурентов и оповещения клиентов в реальном времени. Также разберем, при...

Продолжая недавний разговор про потоковую передачу событий и соответствующие Big Data инструменты, сегодня рассмотрим не отдельные фреймворки обработки данных в режиме реального времени, а комплексные платформы, которые объединяют сразу несколько технологий для интерактивной аналитики больших данных. Вас ждет краткий обзор Cloudera Streaming Analytics, Materialize и Rockset: что это такое, как...

Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим, что представляет собой облачная платформа VMware Tanzu Greenplum, где ее можно развернуть и каковы преимущества cloud-решения по сравнению с локальной версией этой MPP-СУБД. Что такое VMware Tanzu Greenplum и чем это отличается от open-source версии Напомним, в 2020 году корпорация...

Сегодня в качестве полезного примера для обучения дата-инженеров и разработчиков Spark-приложений, разберем кейс компании Pinterest по интерактивной аналитике больших данных средствами SQL-модуля этого популярного фреймворка. Читайте далее, почему дата-инженеры решили заменить HiveServer2 на Spark Thrift JDBC/ODBC, зачем понадобилось писать собственный клиент поверх Apache Livy и как это было сделано. Зачем...
Хотя Apache Kafka стала стандартом де-факто для потоковой передачи событий, на этой платформе можно реализовать и пакетный режим вычислений. В рамках обучения дата-инженеров, сегодня рассмотрим, как совместить пакетную парадигму обработки Big Data с потоковой, развернув конвейер аналитики больших данных на Apache Kafka. Пакеты и потоки: versus или вместе Пакетную и потоковую...
В недавней статье про преимущества хранилища метаданных Apache Hive и другие плюсы этого популярного инструмента SQL-on-Hadoop, мы упоминали формат открытых таблиц Iceberg как альтернативу для хранения огромных наборов аналитических данных. Он добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы Spark, Trino, Presto, Flink и Hive. Сегодня рассмотрим подробнее, что такое Apache Iceberg и...
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим ключевые отличия графовых СУБД от реляционных, а также познакомимся с основами Neo4j и ее языком запросов - Cypher. Также вас ждет практический пример построения несложного графа средствами Cypher. Когда графовые СУБД лучше реляционных и почему Несмотря на...

Сегодня рассмотрим, как методы графовой аналитики больших данных помогают бороться с эпидемией финансовых мошенничеств: выявлять номера злоумышленников, идентифицировать фрод-транзакции, выявлять и предотвращать схемы отмывания денег. Читайте далее, что под капотом AML-систем и как инструменты Data Science предотвращают злоупотребление методами социальной инженерии. Немного истории: что такое социальная инженерия и чем это...

В продолжение недавней статьи для дата-инженеров про альтернативные платформы потоковой передачи событий вместо Apache Kafka, сегодня рассмотрим пример аналитики больших данных средствами Flink SQL, записи результатов в Elasticsearch и их визуализации в Kibana. Читайте далее, чем Redpanda отличается от Kafka, а Flink – от Apache Spark с точки зрения потоковой...

В рамках обучения разработчиков Spark-приложений, аналитиков данных и дата-инженеров, сегодня рассмотрим, как улучшить и визуализировать понимание обработки данных в этом Big Data фреймворке. Читайте далее про API встроенных механизмов наблюдения за качеством данных в Apache Spark и открытые библиотеки профилирования на примере Deequ. 2 уровня абстракции мониторинга Spark-приложений для дата-инженера...