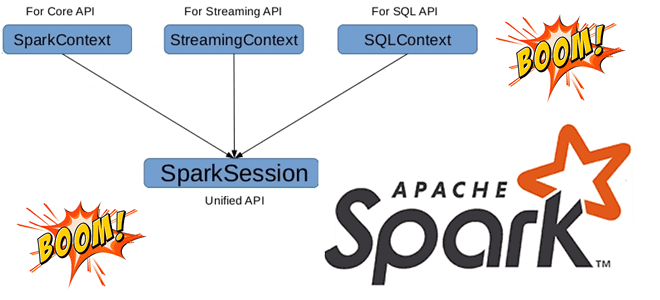
Может ли быть несколько сеансов в одном Spark-приложении с разной конфигурацией, зачем нужен метод foreachBatch() в структурированной потоковой передаче и чем он отличается от foreach(), почему возникает ошибка Table or view not found: microBatch и как ее обойти. В рамках обучения разработчиков Apache Spark и дата-инженеров заглядываем под капот этого...

Как изменять правила фильтрации данных без перезапуска потокового Flink-приложения: практический пример для разработчиков и дата-инженеров. Чем подход с ключами состояний отличается от широковещательных соединений, каковы достоинства и недостатки этих альтернатив. Фильтрация данных в статике и динамике Практически каждая платформа потоковой передачи событий позволяет использовать фильтрацию операторов для отбора данных согласно...

Недавно мы писали про рекомендательную систему американской медиа-компании Meredith Corporation на основе графовой СУБД Neo4j и алгоритма непересекающихся множеств (Union-Find). Продолжая эту тему в рамках нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, как построить простой рекомендательный движок с помощью выражений и операторов языка запросов Cypher...
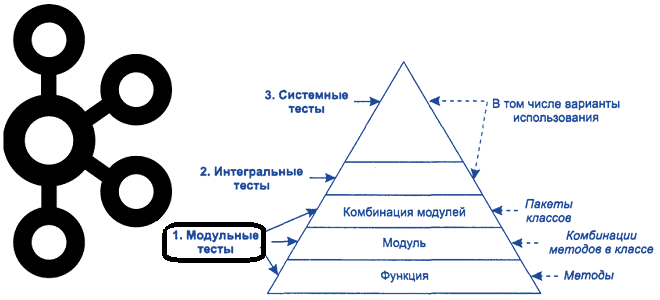
Чтобы сделать наши курсы по Apache Kafka еще полезнее, сегодня разберем, как тестировать распределенные приложения на базе этой платформы потоковой обработки событий. Краткий ликбез для разработчика Kafka Streams и дата-инженера: классы, методы и приемы модульных тестов с примерами. Ликбез по модульному тестированию: что такое mock-объекты Про виды тестирования мы уже...

В этой статье для дата-инженеров и администраторов кластера рассмотрим, как считать данные из распределенной файловой системы Apache Hadoop в MPP-СУБД Greenplum. Архитектура и принцип работы PXF-коннектора к HDFS с примерами команд. Интеграция Greenplum и Hadoop через PXF-коннекторы Мы уже писали, что представляет собой интеграционный фреймворк PXF (Platform Extension Framework), который...

Сегодня заглянем под капот Apache Spark и разберем, для чего этому популярному вычислительному движку база метаданных, как ее назначить и что не так с хранилищем данных по умолчанию. Зачем уходить от Apache Derby к Hive и как это сделать: краткий ликбез с примерами для обучения дата-инженеров и разработчиков распределенных приложений....

Недавно в Google Dataproc появился бессерверный Apache Spark. Разбираемся, что это такое и зачем нужно дата-инженерам. Как работает serverless Spark в облачной платформе Google и почему выбирать между Dataflow и Dataproc стало еще сложнее. Блеск и нищета Google Dataproc Напомним, Google Dataproc – это облачный Hadoop, который работает аналогично другим...
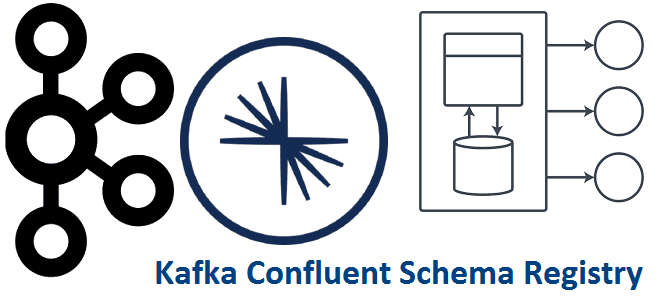
Мы уже рассказывали, что такое реестр схема Apache Kafka и зачем он нужен. Чтобы глубже разобраться с этой темой, важной для обучения разработчиков распределенных приложений и дата-инженеров, сегодня заглянем под капот Schema Registry и разберем работу этого компонента платформы Confluent Apache Kafka с продюсерами и потребителями. Еще раз про реестр...

Продолжая разговор про импортозамещение, сегодня рассмотрим новый продукт от «Аренадата Софтвер» - разработчика широкой линейки российских решений для хранения и аналитики больших данных. Компания адаптирует открытые дистрибутивы Big Data фреймворков к специфике корпоративного использования и предоставляет русскоязычную поддержку 24/7. Что такое Arenadata Postgres, кому и зачем нужен этот продукт, и...
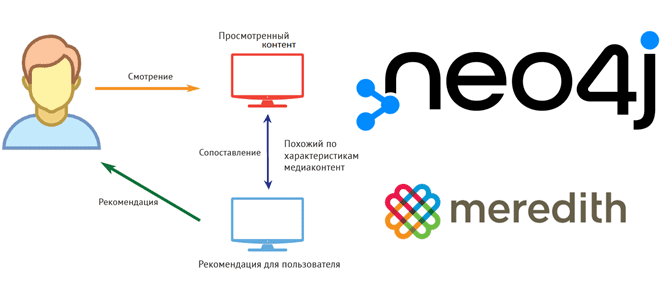
Развивая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим американского медиаконгломерат Meredith Corporation по персонализации пользовательских профилей с помощью графовой СУБД Neo4j и алгоритма непересекающихся множеств (Union-Find). Постановка задачи: сложности идентификации анонимных клиентов Различными контент-продуктами конгломерата Meredith Corporation ежемесячно пользуется более 180 миллионов человек через приложения,...
Недавно мы писали про Yandex Managed Service for Apache Kafka. Продолжая тему импортозамещения, сегодня рассмотрим, как этот и другие полностью управляемые сервисы Яндекса помогли отечественному маркетплейсу KazanExpress построить эффективное BI-решение. Что такое Yandex DataLens и как он способен заменить зарубежные системы бизнес-аналитики типа Tableau с Power BI, а также открытый Apache...
В этой статье для дата-инженеров и аналитиков данных, рассмотрим, что такое широковещательные соединение в Apache Spark SQL, чем оно полезно и как работает на практических примерах. BROADCAST JOIN в SELECT-запросах Spark SQL, а также краткий ликбез по подсказкам или хинтам. Что такое широковещательное соединение в Apache Spark SQL Распределенная природа...

В свете импортозамещения сегодня рассмотрим российские альтернативы облачных управляемых сервисов для развертывания Apache Kafka. Сравнение отечественных Yandex Managed Service for Apache Kafka и VK Cloud Solutions Big Data с зарубежным Confluent Cloud. Облачная Apache Kafka от Confluent и не только Пожалуй, самым популярным облачным сервисом Apache Kafka во всем мире...

В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, как повысить эффективность выполнения Python-кода с помощью кросс-языковой платформы Apache Arrow. Что такое PyArrow и как это улучшает производительность PySpark-программ. Почему Spark Java быстрее PySpark и как это исправить с Apache Arrow Будучи популярным вычислительным движком в области Big Data, Apache...

15 марта 2022 года вышло очередное обновление MPP-СУБД VMware Tanzu Greenplum, в основе которой лежит одноименный open-source проект. Читайте далее, какие новые фичи добавлены в выпуск 6.20 и что за проблемы устранены в этом минорном релизе. Самое главное: краткий обзор новых фич Greenplum 6.20 Greenplum 6.20.0 включает следующие новые и...
Зачем проверять подключение к Neo4j, какую URI-схему выбрать, чем плохи транзакции с автофиксацией и как передавать переменные в Cypher-запросы: рекомендации по использованию драйверов графовой СУБД в реальных приложениях аналитики больших данных. Драйверы и особенности подключения к базе данных Напомним, драйвер – это сущность, которая реализует определённые API-интерфейсы для взаимодействия с...

Мы уже рассказывали о победителях российского ИТ-конкурса «Проект Года 2020» от профессионального сообщества GlobalCIO в номинации «Аналитика и Big Data», где «Газпром нефть» и банк ВТБ делятся опытом применения российских продуктов Arenadata. Сегодня рассмотрим кейс призера 2021 года - проект «Фабрика данных» в АО «Народный банк Казахстана», в результате которого...

В этой статье для инженеров данных и разработчиков Hadoop-приложений рассмотрим опыт индийской компании Wynk по применению Apache Flink в качестве средства потоковой аналитики больших данных пользовательского поведения в мобильных приложениях прослушивания музыки. Особое внимание уделим вопросу формирования и обработки пользовательских сессий. Постановка задачи и выбор решения Wynk Music является одним...
Сегодня рассмотрим, можно ли построить на Apache Kafka быстрый и надежный блокчейн для криптовалюты, NFT или других проектов, где нужны технологии распределенного реестра. Что общего у топика Apache Kafka с blockchain-цепочкой, чем они отличаются, возможно ли совместить их и для каких случаях. А в качестве примеров перечислим несколько реальных проектов....
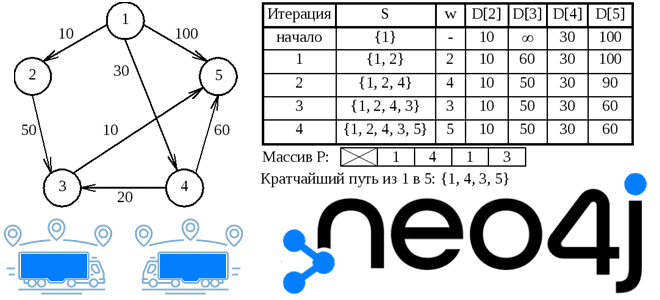
Вопрос перестройки логистических цепочек сегодня стал очень остро перед множеством предприятий, от малого до очень крупного бизнеса. Рассмотрим, как методы Data Science и аналитики больших данных помогают бизнесу справиться с современными вызовами на примере реализации алгоритма Дейкстры в библиотеке Graph Data Science графовой СУБД Neo4j. Постановка задачи: поиск кратчайшего пути...