
В недавней статье про современные архитектуры данных мы упоминали Data Fabric и Data Mesh. Сегодня поговорим про эти стратегии Data Governance более подробно: разберем их главные достоинства и недостатки, основные сходства и принципиальные отличия, ключевые вызовы и технологии реализации, а также возможности совместного применения на практике. Что такое Data Fabric...

Сколько ядер ЦП выделить на каждый исполнитель и каково оптимальное количество памяти для Spark-приложения при статическом и динамическом выделении ресурсов. Важные вопросы эффективной утилизации кластера, с которыми сталкивается каждый дата-инженер и разработчик распределенных программ. Запуск распределенного приложения через spark-submit Повысить эффективность работы приложения Apache Spark можно не только через оптимизацию...

Мы уже писали о преимуществах развертывания Apache NiFi на Kubernetes, а также сложностях практической реализации этого процесса. Сегодня поговорим о контейнеризации реестра NiFi с использованием Helm-диаграмм, а также совмещения с Apache Ranger и Kerberos. 7 главных трудностей развертывания Apache NiFi на Kubernetes Apache NiFi активно используется дата-инженерами для организации потоковых...
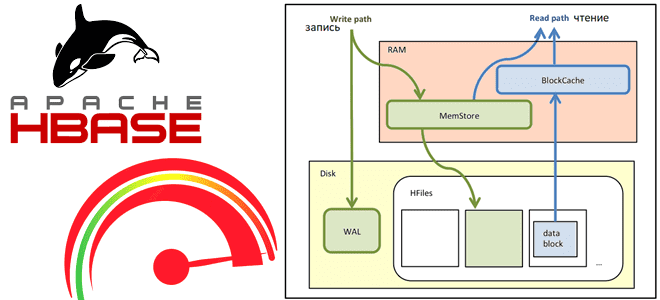
Сегодня рассмотрим, как выполняются операции чтения и записи в Apache HBase, а также с помощью каких приемов можно их ускорить. Как рассчитать оптимальное количество регионов в таблице, зачем отключать версионирование, почему размер ключа строки должен быть небольшим и еще 7 полезных лайфхаков для администратора HBase-кластера. Оптимизация записи данных в Apache...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим особенности обработки пакетных транзакций в популярной графовой СУБД Neo4j . Когда вместо простых запросов встроенного SQL-подобного языка Cypher лучше использовать процедуры библиотеки APOC, чтобы избежать проблем с памятью или остановки обновлений. OOM, большие графы и пакетные транзакции в Neo4j...

17 мая 2022 года вышел очередной релиз главной платформы потоковой передачи событий. Смотрим самые важные обновления свежей Apache Kafka 3.2.0 с точки зрения разработчика распределенных приложений, дата-инженера и администратора кластера. ТОП-5 новинок свежей версии Apache Kafka для администратора кластера Apache Kafka 3.2.0 включает 2 новые фичи, 36 улучшений и 65...

Как писать UDF-функции Greenplum на Python: краткий обзор расширения PL/Python для дата-инженера и разработчика распределенных приложений. Как его установить, настроить и использовать: сопоставления типов данных, SQL-запросы, модули и функции. Поддержка Python в MPP-СУБД Поскольку освоить Python намного проще других языков программирования, например, Java или C#, неудивительно, что он сегодня очень...

Что такое архитектура данных, какие модели чаще всего используются в современных Big Data системах, почему традиционные BI-системы не справляются со всем разнообразием текущих бизнес-сценариев, чем Лямбда отличается от Каппа, а Data Fabric от Data Mesh и зачем внедрять MLOps-инструменты в аналитическую платформу. Немного истории: почему архитектуры данных до сих пор...

Что такое Tungsten, зачем он нужен в Apache Spark и как этот проект устраняет узкие места вычислительного движка, чтобы повысить его производительность и эффективность утилизации ресурсов за счет приближения JVM к bare metal. Рассматриваем самые важные для разработчика распределенных приложений особенности и разбираемся, при чем здесь вольфрам и почему с...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...
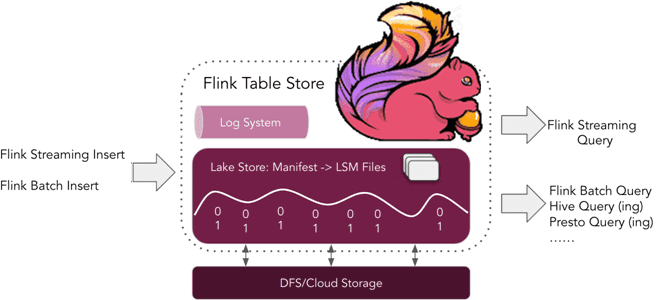
Что такое табличное хранилище Apache Flink, зачем это нужно и почему оно пока не рекомендуется для применения в реальных проектах. Краткий обзор Apache Flink Table Store 0.1.0 для дата-инженеров и разработчиков распределенных приложений. Что такое Flink Table Store и зачем это нужно Уже более полугода, с релиза 1.14, выпущенного в...

В этой статье для обучения дата-инженеров и администраторов кластера Apache HBase разберем, почему региональные сервера могут работать некорректно при высокой нагрузке и при чем здесь SCR-конфигурация файловой системы Hadoop. Что такое Short-Circuit Read в HDFS и почему оно может снижать скорость потокового чтения в приложениях Spark Streaming. Постановка задачи: проблема...
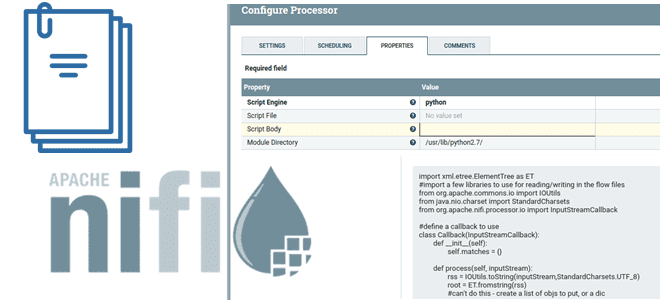
В этой статье для дата-инженеров разберемся, что такое NiFi Scripted Components и как они заполняют пробел между скриптами и пользовательскими компонентами: процессорами, контроллерами, сообщениями и средствами их чтения/записи. Рассмотрим примеры скиптовых процессоров и сервисов, а также определим реальные достоинства и недостатки этих компонентов. Почему просто скриптовых процессоров Apache NiFi недостаточно?...

Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger. Зачем нужна интеграция Apache Hive с Kafka Необходимость связать Apache Hive с Kafka...

Весна богата на новые релизы: в начале мая 2022 года вышел Apache Flink 1.15. Рассказываем, что нового в свежем выпуске: краткий обзор самых полезных фич для разработчика распределенных приложений, а также интересные изменения, исправления ошибок и улучшения для дата-инженера. Scala под капотом и спецификация REST API по стандарту OpenAPI Apache...
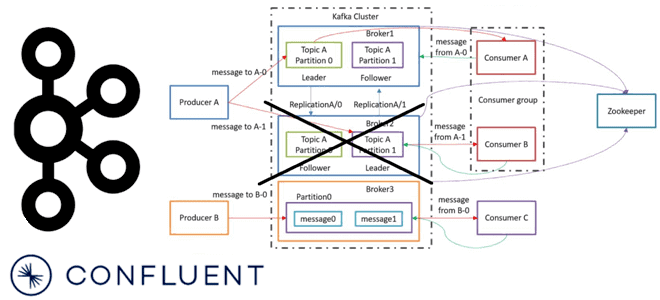
Сегодня рассмотрим важную для обучения администраторов кластера Apache Kafka тему про удаление брокеров. Что происходит, когда администратор удаляет брокер Kafka из кластера, какие сложности при этом могут возникнуть и как с ними справляется решение на базе платформы Confluent. Как вручную удалить брокер Kafka из кластера: краткий guide администратора На первый...

Специально для обучения начинающих аналитиков данных и дата-инженеров сегодня рассмотрим примеры выполнения простых SQL-запросов и оконных функций в Apache Spark на Google Colab. Как быстро проанализировать датафрейм из CSV-файлов с помощью нескольких строк на PySpark. Запуск и использование PySpark в Google Colab Предположим, необходимо определить потенциальный доход от проведения обучающих...

Сегодня в рамках продвижения нашего курса по графовой аналитике больших данных в бизнес-приложениях, рассмотрим новый инструмент популярной графовой СУБД Neo4j для загрузки данных - Data Importer. Что это такое, как работает, чем полезно специалисту по Data Science и зачем обновлять его до последней версии. Что такое Neo4j Data Importer Графовая...

В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi. Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт)....
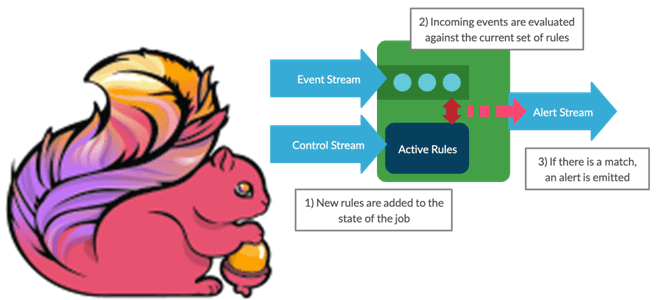
Мы уже писали про динамическое изменение правил фильтрации без перезапуска Flink-приложений. В продолжение этой темы в рамках продвижения нашего нового курса по потоковой обработке данных помощью Apache Flink, сегодня рассмотрим, как избежать неравномерного распределения данных во время выполнения программы. Больше 3-х не собираться: бизнес-правила и динамика разделения данных Перекос или...