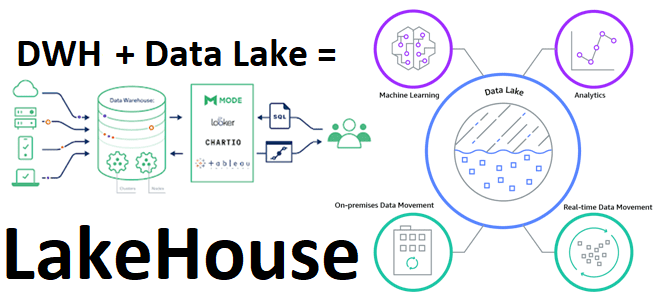
В рамках обучения дата-инженеров и архитекторов корпоративных платформ и приложений аналитики больших данных, сегодня рассмотрим, что такое LakeHouse. Как эта новая гибридная архитектура управления данными объединяет 2 разнонаправленные парадигмы хранения информации, а также чего от нее ожидают бизнес-пользователи, дата-инженеры, аналитики и ML- специалисты. Историческая справка: от DWH к Data Lake...

В этой статье для обучения дата-инженеров рассмотрим, почему в потоковых конвейерах обработки данных на базе Apache NiFi случаются ошибки, и какие популярные стратегии и инструменты помогут идентифицировать эти проблемы, а также решить их. Проблемы конвейеров обработки данных на Apache NiFi Конвейеры данных помогают консолидировать информацию из разных источников, чтобы получить...
Мы уже рассматривали важность мониторинга приложений Apache Flink и говорили про метрики отслеживания задержки обработки данных в потоковых заданиях. Сегодня заглянем под капот этого фреймворка и разберем, какие показатели работы JVM, а также RocksDB особенно важны для дата-инженера и разработчика распределенных приложений. Метрики JVM во Flink-приложениях Напомним, основным языком разработки...
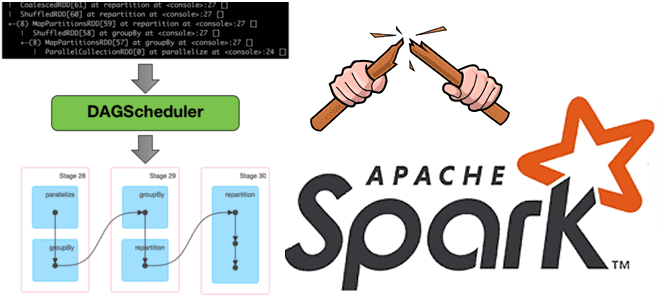
Недавно мы говорили про трудности наблюдаемости данных вообще и возможности мониторинга их происхождения в Apache Spark. Сегодня рассмотрим, зачем дата-инженеру прерывать DAG lineage в Spark-приложениях и как это сделать. Что такое DAG lineage и зачем его прерывать? Напомним, Apache Spark использует концепция DAG для выполнения распределенных вычислений. Направленный ациклический граф...

Сегодня рассмотрим пример программы лояльности турецкого интернет-магазина Trendyol, где Apache Kafka и документо-ориентированная NoSQL-СУБД Couchbase используются для генерации купонов на скидки. Почему при большом объеме данных случаются проблемы тайм-аутов в Couchbase, как их решить и при чем здесь коннекторы к Apache Kafka. Архитектура системы управления купонами Trendyol – это популярный...

16 июня 2022 года вышла новая версия Apache Spark – 3.3.0. Разбираем главные фичи этого минорного релиза, особенно важные для дата-инженера и разработчика распределенных приложений: от расширения поддержки ANSI SQL до профилирования UDF на Python. Главные изменения Apache Spark 3.3.0 Apache Spark 3.3.0 — это четвертый релиз линейки 3.x, в...
Недавно мы говорили про непрерывный мониторинг Flink-приложений и подробно рассмотрели метрики состояния и пропускной способности. В продолжение этой важной для разработчиков и дата-инженеров темы, сегодня рассмотрим, как идентифицировать временную задержку обработки данных. Пользовательские метрики задержки в потоковых приложениях Для потоковых приложений, которые обрабатывают события в режиме, близком к реальному времени,...
Вчера мы рассказывали, почему важна наблюдаемость данных какие платформы помогают комплексно обеспечить все ее аспекты. В продолжение этой темы сегодня заглянем под капот происхождения данных в Apache Spark с помощью агента Spline и других способов. Трудности data lineage в Apache Spark Когда конвейер данных выходит из строя, дата-инженеру нужно скорее...
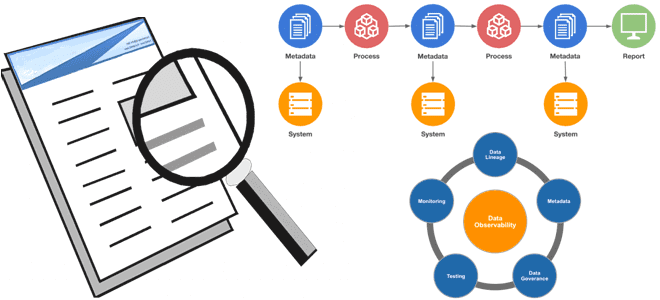
Сегодня рассмотрим, почему наблюдаемость данных так важная для проектов Big Data, какие компоненты обеспечивают ценную информацию о качестве и надежности данных, чем это похоже на DataOps, а также как эти идеи реализовать на практике с использованием популярных инструментов современной дата-инженерии. Почему важна наблюдаемость данных Цифровизация предполагает управление на основе качественных...
Специально для обучения разработчиков распределенных приложений и дата-инженеров масштабных платформ аналитики больших данных на Apache Flink, рассмотрим наиболее важные системные показатели, а также инструменты мониторинга этих метрик. Мониторинг Flink-приложений: особенности и метрики В общем случае мониторинг приложений гарантирует, что ПО обрабатывает данные и выполняет запрошенные действия ожидаемым образом. Непрерывное отслеживание...

Для обучения дата-инженеров и аналитиков данных, сегодня рассмотрим приемы оптимизации SQL-запросов в Apache Hive, выполняемых движком Tez. Каким образом Tez рассчитывает оптимальное количество редукторов, зачем включать индексацию фильтров, как статистика таблицы помогает улучшить план выполнения запросов и что за конфигурации нужно менять. 3 движка выполнения запросов в Apache Hive Напомним,...

10 июня 2022 года вышел свежий релиз популярной MPP-СУБД. Разбираемся с улучшениями функциональных возможностей и решенными проблемами в Greenplum версии 6.21.0. Самое важное для администратора кластера и дата-инженера. 4 новых модуля свежего релиза В Greenplum 6.21.0 теперь поддерживается команда SET TRANSACTION SNAPSHOT, которая устанавливает характеристики текущей транзакции, не влияя на...
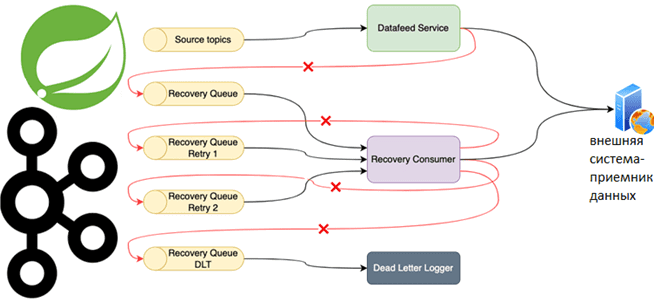
Специально для обучения разработчиков распределенных приложений и дата-инженеров, рассмотрим практический пример использования возможностей фреймворка Spring для управления повторными попытками отправки сообщений потребителям из топика Apache Kafka. Повторные попытки отправки сообщений и Spring для Apache Kafka Довольно часто Kafka-приложения требуют высокой надежности обработки сообщений. Например, в финтех- или медтех-проектах, а также...

Сегодня рассмотрим 2 основные категории технологий обработки данных: пакетную и потоковую. Что общего между batch и stream processing, где они применяются, какими технологиями поддерживаются, можно ли их использовать вместе и как это сделать: ликбез по архитектуре больших данных. Потоковая и пакетная обработка: краткий обзор с примерами Обработки данных в режиме...

15 июня 2022 года вышел новый выпуск Apache NiFi. Разбираем, что нового и полезного в релизе 1.16.3: исправленные ошибки, а также улучшения, важные для дата-инженера и администратора кластера Apache NiFi. 7 исправленных ошибок в релизе 1.16.3 Apache NiFi – один из самых популярных и востребованных инструментов современного дата-инженера. Эта платформа...

Что такое SparkListener, какие встроенные слушатели бывают в Apache Spark, как написать собственный перехватчик событий и зачем это нужно разработчику распределенного приложения. Также рассмотрим, как реализовать свой слушатель для приложения на PySpark и зачем включать уровень логирования INFO для SparkContext. Что такое слушатель Spark Apache Spark позволяет быстро обрабатывать большие...
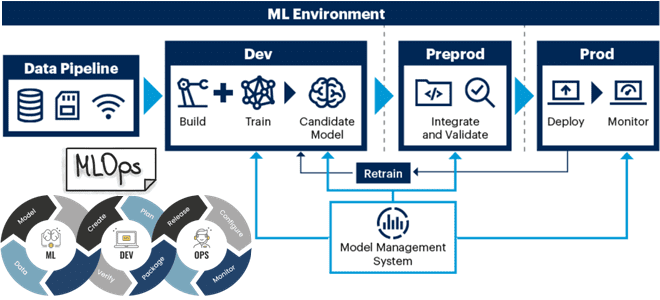
Что и насколько часто меняется в системах машинного обучения, почему необходимо отслеживать эти изменения и как MLOps помогает справиться с управлением ML-моделями, данными, кодом и инфраструктурой развертывания. Почему стек технологий MLOps такой разношерстный и какие инструменты выбирать для практического использования. MLOps для решения дрейфа данных и других проблем ML-систем Машинное...

В свежем релизе Apache Kafka 3.2.0, который вышел 17 мая 2022 года, о чем мы писали здесь, есть много интересных улучшений для повышения устойчивости потоковых приложений. Почему важна новая фича назначения резервных задач с учетом стоек и как разработчик с дата-инженером могут использовать в помощь администратору кластера: разбор rack awareness...
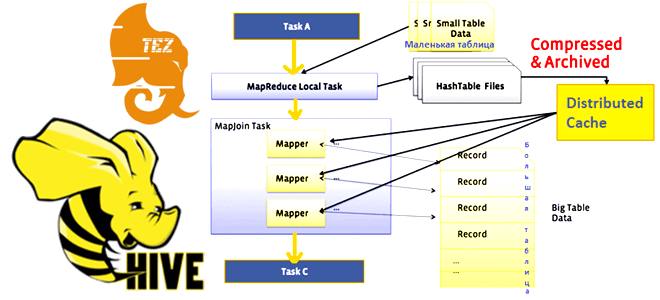
В этой статье для обучения дата-инженеров, аналитиков данных и разработчиков распределенных приложений рассмотрим один из методов оптимизации SQL-запросов в Apache Hive. Что такое оператор MapJoin, в каких условиях и как он работает, чем выгоден для HiveQL-запросов и почему при его выполнении с движком Tez может возникнуть нехватка памяти. Что такое...

Недавно мы писали про главные новинки свежего релиза Apache Flink 1.15, особенно важные с точки зрения обучения разработчиков распределенных приложений и дата-инженеров. Сегодня рассмотрим подробнее, зачем в этом выпуске введены дополнительные режимы восстановления потоковых stateful-заданий из моментальных снимков, когда и какой режим использовать, а также как выбрать формат точки сохранения...