
Чтобы сделать наши курсы по Apache Flink еще более полезными для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных, сегодня разберем, как работают источники данных потоковой обработки на примере топиков Kafka. Источники данных в Apache Flink Наряду с Apache Spark, Flink также является популярным фреймворком пакетной и потоковой обработки...
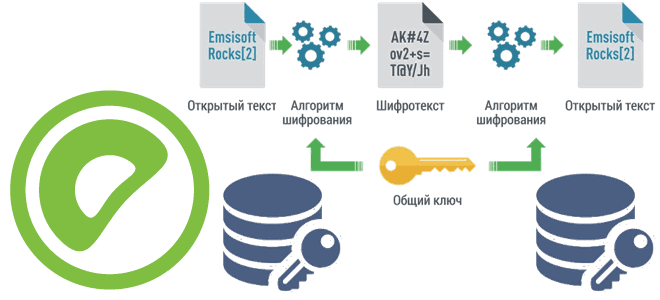
Чтобы сделать наши курсы по Greenplum еще более полезными для дата-инженеров и администраторов, сегодня познакомимся с pgcrypto – важным расширением этой MPP-СУБД, которое предоставляет криптографические функции, чтобы хранить некоторые столбцы данных в зашифрованном виде. Как установить расширение pgcrypto и использовать его для улучшения безопасности Greenplum. Шифрование данных в Greenplum База...

Сегодня разберем распространенные трудности корпоративных платформ обработки и хранения Big Data, а также как избежать этих проблем, используя современные методы и средства проектирования дата-архитектур и инструменты инженерии данных. 7 главных проблем с платформами данных Обычно каждая data-driven компания органично развивает свои платформы данных, усложняя их архитектуры. Но этот процесс эволюционного...
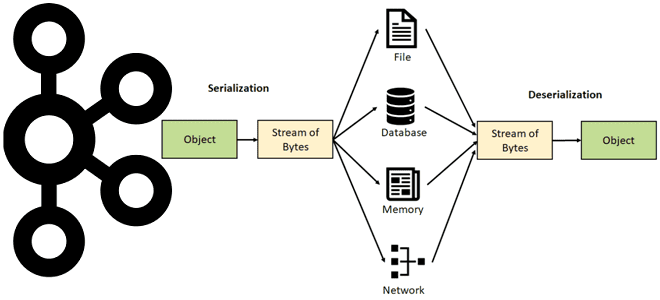
Недавно мы писали про сериализацию и десериализацию данных в Apache Kafka. Продолжая эту важную для обучения дата-инженеров и разработчиков распределенных приложений тему, рассмотрим особенности преобразования и валидации сообщений в JSON-формате, а также поговорим про автоматическую идентификацию формата сообщения. Сериализация и десериализация данных в Apache Kafka Выполняя роль интеграционной платформы, Apache...
В июле 2022 года на конференции Data and AI Summit компания Databricks представила новый проект для экосистемы Apache Spark под названием Spark Connect. Что это такое и как оно пригодится разработчикам распределенных приложений и дата-инженерам, читайте далее. Что не так с Apache Spark и зачем нужен новый проект Databricks Появившись...
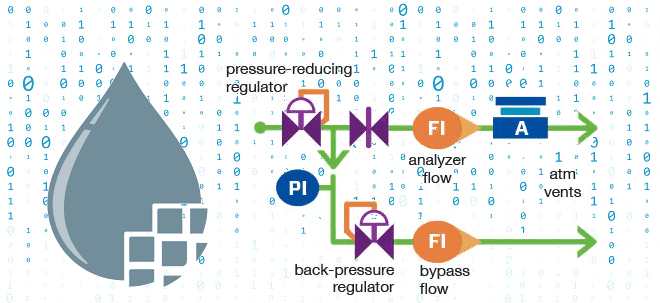
Чтобы сделать наши курсы для дата-инженеров по Apache NiFi еще более полезными, сегодня мы рассмотрим, что такое обратное давление и как этот механизм используется при потоковой обработке данных. Также поговорим про визуализацию back pressure в GUI, математические модели прогнозирования пороговых значения и настройку конфигураций. Что такое обратное давление в потоковой...

9 сентября 2022 года VMware Tanzu выпустили Greenplum 6.22. А спустя месяц, 7 октября вышел апгрейд этого релиза с исправлением ошибок. Разбираем, что нового в этих выпусках: полезные функции, улучшения и исправления ошибок, особенно важные для администратора кластера и дата-инженера. Greenplum 6.22.0 Сентябрьское обновление Greenplum 6.22.0 включает следующие функциональные возможности...

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...

В этой статье для обучения дата-инженеров и разработчиков приложений потоковой аналитики больших данных рассмотрим, на что следует обратить внимание при развертывании Apache Flink в реальных проектах. Обработка опоздавших данных, тонкости сериализации, проблемы неравномерного распределения и большие состояния заданий. Обработка опоздавших данных в Apache Flink В потоковой обработке данных, которую поддерживает...
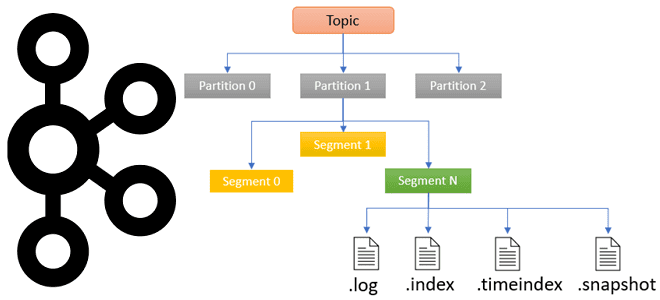
Чтобы сделать наши практические курсы по Apache Kafka еще более полезными, сегодня рассмотрим, в каких файлах хранятся сообщения, смещения и состояния продюсера, а также функции работы с ними для потоковой передачи событий. Средства обработки и хранения данных в Apache Kafka Прежде, чем погружаться в тонкости хранения данных в Apache Kafka,...

Сегодня мы продолжим говорить про Apache Spark Structured Streaming и его применение для обновления данных в таблицах Delta Lake. А также на практических примерах разберем, как выполняются основные операции работы с данными средствами Spark Structured Streaming API. Таблицы в Delta Lake Delta Lake – это уровня хранилища данных с открытым...
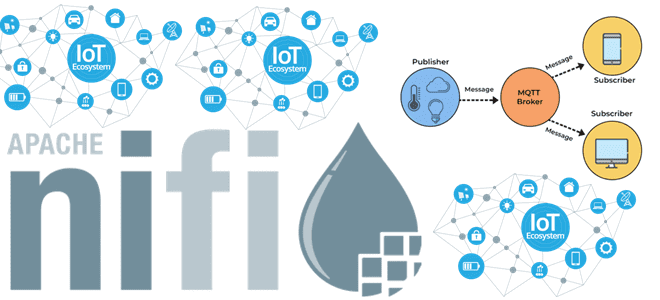
В прошлой статье про обновление Apache NiFi мы писали, что в новой версии 1.18.0 улучшено взаимодействие с протоколом MQTT, который активно используется в системах интернета вещей. Сегодня разберем более подробно, как наладить сбор и публикацию данных в MQTT-топики с помощью процессоров Apache NiFi, а также разберем, что такое брокер HiveMQ....

Продолжая недавний разговор про Apache Spark Structured Streaming, сегодня рассмотрим, как этот движок потоковой обработки данных помогает дата-инженеру реализовать идемпотентную запись в таблицы Delta Lake, а также выполнить операции слияния и обновления/вставки в помощью метода foreachBatch(). Идемпотентность потоковых приложений Apache Spark Идемпотентность – важное свойство распределенных систем, которое гарантирует, что...

Недавно мы рассматривали тонкости проектирования схем данных в Greenplum. Продолжая разбирать важные для обучения дата-инженеров и архитекторов DWH темы, сегодня поговорим о том, как разделение и распределение данных влияют на скорость выполнения SQL-запросов в этой MPP-СУБД. Распределение данных Напомним, MPP-СУБД Greenplum широко используется в качестве OLAP-системы и корпоративного хранилища данных....

Сегодня рассмотрим, как дата-инженеры маркетплейса Whatnot масштабировали потоковую обработку данных с помощью Apache Kafka, изменив свои ETL-процессы и реализовав на этой распределенной платформе шину событий для анализа пользовательского поведения c ksqlDB и Rockset. Постановка задачи: события пользовательского поведения в Whatnot Whatnot – это маркетплейс, пользователи которого могут покупать и продавать...
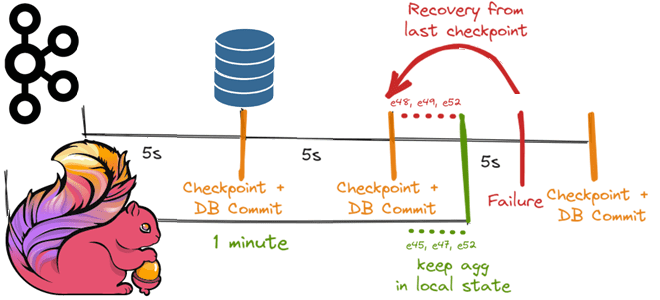
Как Apache Flink реализует строго однократную доставку событий в потовой обработке данных с помощью контрольных точек для записи данных в реляционную базу, используя функцию TwoPhasedCommitSink(), основанную на механизме согласованных snapshot’ов 35-летней давности и Kafka Transaction API. Трудности строго однократной доставки в потоковой обработке данных Распределенная обработка потоков с отслеживанием состояния...

Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...

Разработка высоконагруженных систем потоковой аналитики больших данных включает не только написание кода, но и его оптимизацию. Поэтому разработчикам приложений Apache Spark Structured Streaming и дата-инженерам полезно знать, как можно повысить эффективность своих Big Data систем. В этой статье мы рассмотрим конфигурации и приемы, которые могут ускорить пакетные и потоковые вычисления....

10 октября 2022 года вышел очередной релиз Apache NiFi. Разбираемся с его ключевыми новинками: провайдеры параметров, подключаемый реестр клиентов, новые процессоры и улучшения протокола MQTT. Самые главные фичи свежего выпуска для дата-инженера и администратора кластера Apache NiFi. ТОП-7 новых фич свежего релиза Будучи популярным инструментов современной дата-инженерии, Apache NiFi активно...

Как турецкая e-commerce компания Trendyol повысила эффективность пакетных вычислений, используя распределенную платформу потоковой обработки событий Apache Kafka вместе с серверной утилитой сбора и фильтрации данных из разных источников Logstash. Пакетная обработка данных и конвейер на Logstash Хотя сегодня все больше организаций переходят на потоковую обработку событий в реальном времени, пакетная...