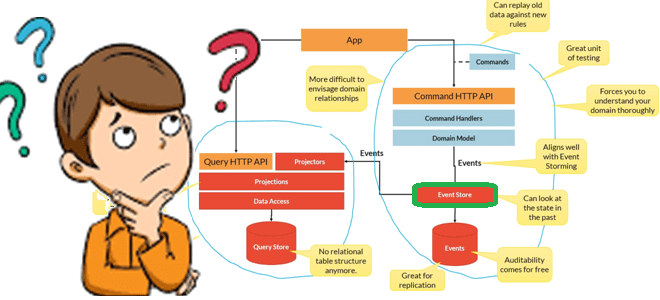
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...

Недавно мы писали про группы общего доступа в Apache Kafka, которые планируется реализовать в KIP-932. Сегодня рассмотрим, как именно это предполагается сделать. Принципы работы группы общего доступа Предложение по улучшению Kafka (KIP, Kafka Improvement Proposal) предполагает внесение значительных изменений. Все начинается с публикации предложения, которое рассматривается сообществом, комментируется и пересматривается до...
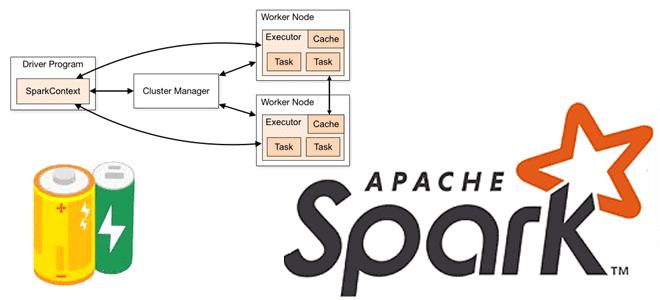
Что такое аккумуляторы в Apache Spark, чем они отличаются от широковещательных переменных и какова польза от этих концепций при разработке распределенных приложений и их использовании в кластере. Широковещательные переменные vs аккумуляторы В любой распределенной среде возникает задача сведения локальных результатов вместе. На практике, ее решение не всегда является простым. Например,...
Сегодня поговорим о том, как обработка исключений позволяет спроектировать и реализовать надежную архитектуру конвейера обработки данных, включая ETL/ELT-процессы и их компоненты. Архитектура конвейеров обработки данных: ETL/ELT-процессы Наличие хорошо спроектированной инфраструктуры данных необходимо для получения максимальной отдачи от данных для data-driven управления. Поскольку данные постоянно увеличиваются в объеме, следует организовать управление...
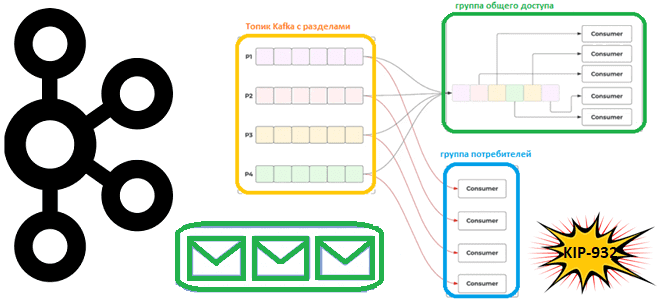
Что такое группы общего доступа для потребителей, чем это отличается от существующей концепции группы потребителей, почему в Apache Kafka появляются очереди и чем это улучшит потоковую обработку событий. Что такое KIP-932: группы общего доступа потребления данных из Apache Kafka Напомним, группы потребителей в Kafka предназначены для повышения надежности упорядоченной доставки...
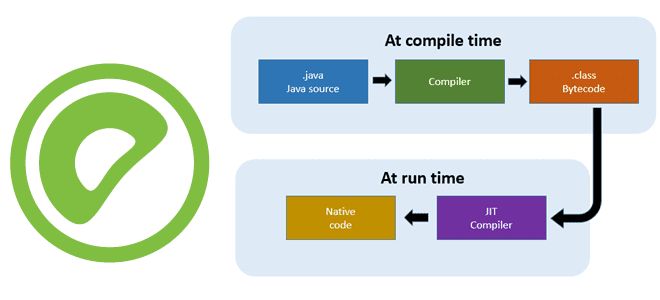
Чтобы SQL-запросы выполнялись быстрее, в Greenplum, как и в PostgreSQL, поддерживается JIT-компиляция. Читайте далее, что это такое и всегда ли эта динамическая генерация машинного кода на лету дает выигрыш в скорости для аналитики больших данных. Что такое JIT-компиляция Технология JIT-компиляции (Just-In-Time) позволяет генерировать машинный код во время выполнения программы. В...

Как Spark-приложение может прочитать данные из топиков Kafka: обзор вариантов и способов их использования. А также рассмотрим, почему Spark Structured Streaming заменила прямой поток и подход на основе приемника. Прямой поток и подход на основе приемника Будучи мощным фреймворком разработки распределенных приложений, Apache Spark позволяет считывать данные в потоковом режиме...

Недавно мы писали про источники данных Apache Flink. Сегодня рассмотрим, как создать и протестировать собственный источник данных для их обработки в распределенном приложении. Создание своего источника данных в Apache Flink Напомним, источник данных в Apache Flink состоит из трех основных компонентов: Split, SplitEnumerator и SourceReader. Splits — это часть данных,...
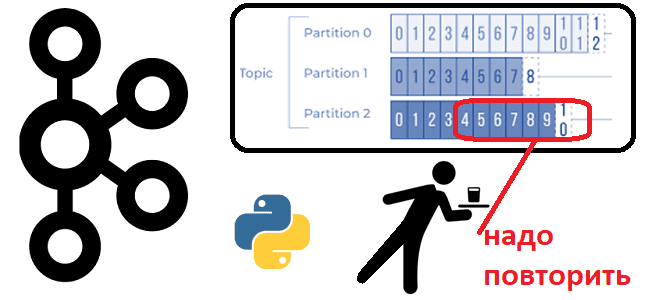
Иногда возникает потребность в повторном чтении данных из Apache Kafka с определенного момента времени. Сегодня рассмотрим, как это сделать, написав простенький Python-скрипт потребления из раздела топика. Публикация данных в Kafka В качестве примера возьмем ранее рассмотренный в этой статье кейс приема потока обращений в интернет-магазин. Обращения могут представлять собой заявки...

Сегодня посмотрим, как запустить Spark-приложение в Google Colab и увидеть сведения о его выполнении в веб-интерфейсе на удаленной машине, тунеллированной с помощью утилиты ngrok. Проброска туннеля в Google Colab с ngrok для Spark-приложения Хотя назвать Google Colab удобной средой для разработки приложений или исследования данных, нельзя, им часто пользуются аналитики...

Мы уже писали про механизмы обеспечения высокой доступности в кластере Greenplum. Сегодня рассмотрим, какие инструменты и приемы помогут выявить сбои координатора и сегментов, а также как администратору кластера этой MPP-СУБД восстановить ее работоспособность. Что такое зеркалирование сегментов Greenplum Напомним, кластер Greenplum представляет собой несколько экземпляров популярной объектно-реляционной базы данных (БД)...

Сегодня рассмотрим, как написать и запустить в Google Colab свое Python-приложение считывания данных из топика Kafka с помощью коннектора FlinkKafkaConsumer из библиотеки pyflink.datastream.connectors и почему заставить его работать оказалось не так просто. Использование FlinkKafkaConsumer для доступа к Kafka из Flink приложения Недавно я показывала, как написать PyFlink-скрипт считывания данных из...
Что такое «проблема разделенного мозга» в распределенных системах, почему она возникает, при чем здесь зомби-продюсеры и как с этим бороться. Разбираем на примере Apache Kafka. Проблема разделенного мозга или зомби-процессы в распределенных системах Термин зомби-процесс пришел из области операционных систем, однако, в распределенных системах его интерпретация абсолютно противоположна исходному значению....
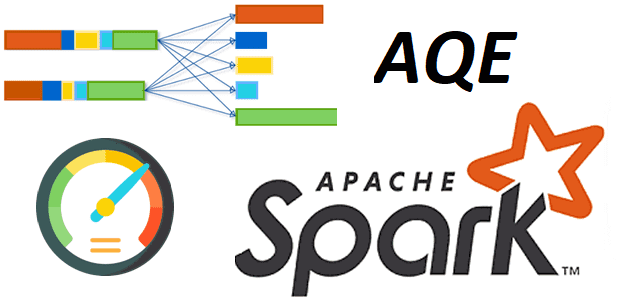
Недавно мы рассматривали практический пример разделения большого датафрейма Apache Spark на несколько разделов. Сегодня поговорим о том, как их объединить с помощью механизм AQE и динамической настройки конфигурации spark.sql.shuffle.partitions. Разделы и оптимизация распределенных вычислений в Spark-приложениях Распределение данных по разделам сильно влияет на скорость работы Spark-приложений. Распределенное приложение выполняется наиболее...
Чем инженерия данных отличается от разработки ПО, как организовать оркестрацию конвейеров обработки данных и внедрить лучшие практики CI/CD. Почему дата-инженерия отличается от разработки ПО При том, что между инженерией данных и разработкой программного обеспечения (ПО) очень много общего, эти ИТ-дисциплины довольно сильно отличаются. Хотя в обоих направлениях используется облачная инфраструктура,...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, какие механизмы обеспечения информационной безопасности поддерживает Apache Spark и как организовать безопасное взаимодействие Spark-приложения с хранилищами данных в экосистеме Hadoop. Безопасная работа Spark-приложений с сервисами Hadoop Многие технологии Big Data изначально оптимизированы для хранения и аналитики больших объемов данных с...
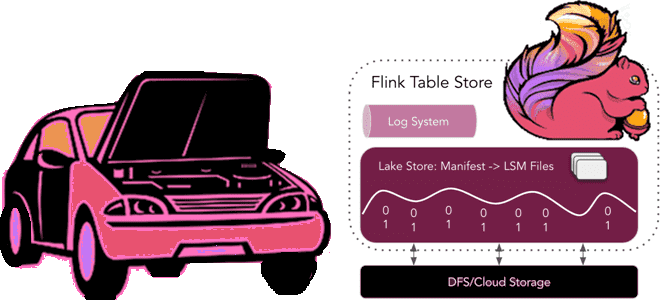
Год назад мы уже писали, как в Apache Flink появились табличные хранилища и зачем они нужны. Сегодня заглянем под капот Flink Table Store, познакомившись со структурой файлов и каталогов. Архитектура и принципы работы Flink Table Store Поскольку Apache Flink объединяет пакетную обработку данных с потоковой, для работы этого универсального stateful-механизма...
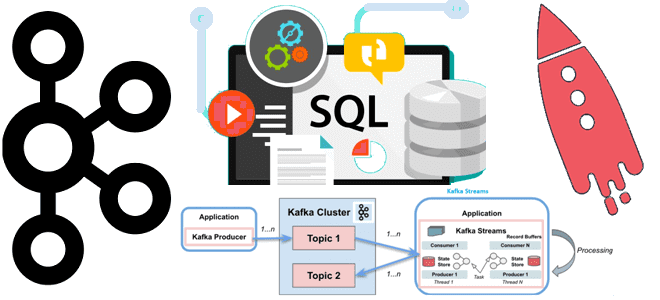
Недавно мы писали, чем Kafka Streams отличается от Consumer API. Сегодня рассмотрим, в чем разница между Kafka Streams и ksqlDB, а также разберем, почему использовать этот компонент экосистемы Apache Kafka не так просто. Как работает ksqlDB: практический пример Apache Kafka является полноценной экосистемой потоковой передачи, вокруг которой существует множество полезных...
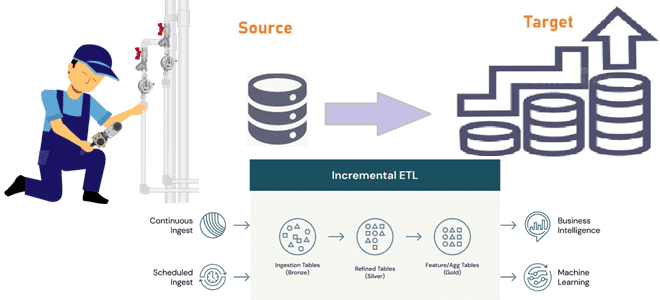
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
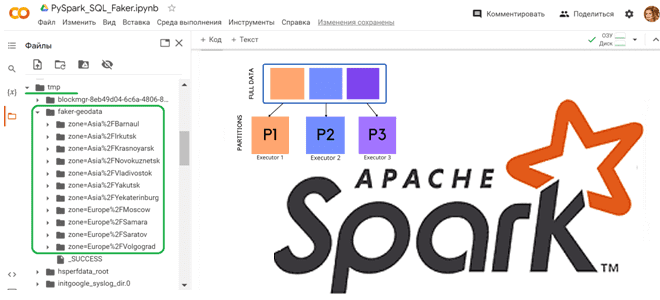
Как сгенерировать набор тестовых данных с Python-библиотекой Faker и разделить данные по разделам, используя функцию partitionBy() в PySpark. Работаем с Apache Spark в Google Colab. Как работает partitionBy() в Apache Spark Чтобы записать на диск один большой датафрейм, разделив его на несколько более мелких файлов, в Python API фреймворка Apache...