
Apache Hive – востребованный инструмент класса SQL-on-Hadoop, который также активно используется в работе с фреймворком Spark. Поэтому сегодня разберем важную тему из обучения дата-инженеров и аналитиков больших данных про оптимизацию SQL-запросов в этом NoSQL-хранилище. Смотрите, чем полезна векторизация HiveQL-операций, какие форматы файлов обрабатываются быстрее, почему денормализация данных в Hive –...

Чтобы добавить в наши курсы по Spark еще больше практических кейсов, сегодня ответим на самые частые вопросы относительно масштабирования распределенных приложений, написанных с помощью этого фреймворка. Читайте далее о пользе динамического распределения, оптимальном выделении ресурсов на драйверы и исполнители, а также каковы тонкости управления разделами в Apache Spark. Лебедь, рак...
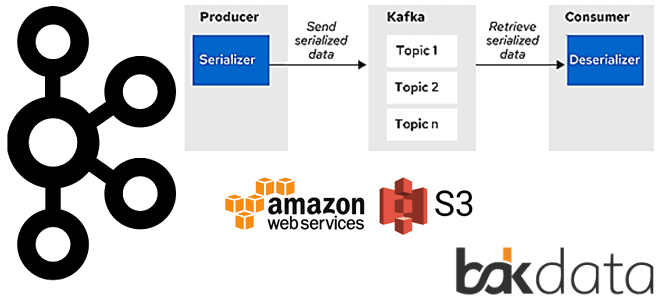
Сегодня рассмотрим проблему обработки больших сообщений в Apache Kafka Streams и способы ее решения с помощью средства сериализации и десериализации (SerDe) от немецкой ИТ-компании Bakdata. Узнайте, почему максимального лимита конфигурации max.message.bytes не хватает, зачем и как приложение Kafka Streams материализует данные, а также каким образом kafka-s3-backed-serde читает и записывает большие...

В недавней статье про оптимизацию SQL-запросов в Greenplum мы рассказывали про планы их выполнения и операторы просмотра этих планов. Сегодня разберем подробнее, какие операции с данными могут встретиться в отчете, сгенерированном командой EXPLAIN, а также рассмотрим, чем эта информация полезна дата-инженеру и аналитику данных. 5 операций в плане выполнения SQL-запросов...

Обучая разработчиков Big Data, сегодня рассмотрим, почему в распределенных приложениях Apache Spark случаются OOM-ошибки. Читайте далее, как работает сборка мусора JVM в Spark-приложениях, почему из-за нее случаются утечки памяти и что можно сделать на уровне драйвера и исполнителя для предупреждения OutOfMemoryError. Сборка мусора JVM и OOM-ошибки в Spark-приложениях На практике...
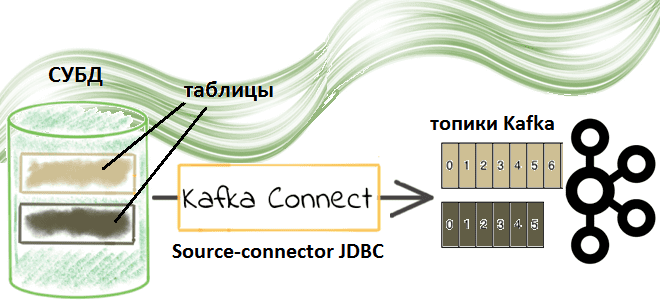
Недавно мы рассматривали пример потоковой передачи данных между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Сегодня заглянем под капот такой интеграции и разберем подробнее, что именно представляет собой JDBC-коннектор источника Kafka от Confluent. Компоненты Kafka Confluent для потоковой интеграции данных: коннекторы и реестр схем...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...
Обучая дата-аналитиков и инженеров данных тонкостям MPP-СУБД Greenplum, сегодня разберем, какой оператор помогает просмотреть план выполнения SQL-запроса, почему добавлять ANALYZE к EXPLAIN нужно с осторожностью и где найти универсальное решение анализа и визуализации PostgreSQL-совместимых продуктов. Я все объясню: команда EXPLAIN в PostgreSQL Разобравшись с оператором анализа и сбора статистики по...

В этой статье по обучению Apache Spark рассмотрим, чем графический веб-интерфейс этого фреймворка полезен разработчику распределенных приложений. Читайте далее, где посмотреть кэшированные данные, визуализацию DAG, переменные среды, исполняемые SQL-запросы, а также прочие важные метрики кластерных вычислений и аналитики больших данных. 9 страниц Apache Spark UI Apache Spark предоставляет набор пользовательских...

Сегодня в рамках обучения разработчиков распределенных приложений и дата-инженеров рассмотрим практический пример потоковой интеграции данных из 2-х разных источников с Apache Kafka. Читайте далее, как мгновенно передать данные между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Apache Kafka как средство потоковой интеграции данных Интеграция...

Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками. 3 бэкенда Apache Flink для хранения...

Чтобы сделать наши курсы по Greenplum и аналитике больших данных еще более полезными, сегодня рассмотрим особенности выполнения SQL-запросов в этой MPP-СУБД. Читайте далее, зачем и когда запускать оператор анализа табличной статистики ANALYZE, как он связан с планом выполнения SQL-запроса и какие инструменты помогут дата-инженеру, аналитику или разработчику повысить их производительность....
Продвигая наши курсы по Apache Spark для разработчиков, сегодня рассмотрим пользовательские функции и особенности работы с ними в API SQL-модуле этого фреймворка. Читайте далее про идемпотентность UDF-функций и их влияние на распределение данных в кластере Apache Spark. Как устроены UDF в Apache Spark: краткий ликбез Пользовательские функции (User Defined Functions,...
Сегодня рассмотрим 2 важных понятия архитектуры распределенных систем для хранения и аналитики больших данных на примере платформы потоковой обработки событий Apache Kafka.Читайте далее, что такое согласованность и полнота, а также в чем преимущества строго однократной доставки сообщений на основе транзакционной записи и фиксации смещений в журналах, и как все это...
В рамках обучения разработчиков Apache Spark, сегодня рассмотрим еще несколько интересных особенностей этого фреймворка, ограничивающих его типовые возможности и на PySpark-примерах разберем, как с этим бороться. Читайте далее, что такое оконные функции и зачем они нужны, как сортировка влияет на фрейм окна в Spark SQL и чем опасны действия над...
Чтобы сделать наши курсы по Apache Spark еще более полезными, мы рассказываем о неочевидных тонкостях этого фреймворка, знание которых позволит разработчику распределенных приложений использовать возможности этой технологии более эффективно. Сегодня на практических примерах PySpark в API DataFrame рассмотрим разницу между функциями сортировки массивов и особенности объединения контенкации, а также разберемся...
Продолжая разговор про вычислительные операции над датафреймами в Apache Spark, сегодня рассмотрим, какие преобразования (transformations) и действия (actions) чаще всего используются при разработке распределенных приложений и аналитике больших данных. Читайте далее, про виды столбцовых преобразования и отличия действия collect() от take(). Преобразования в Apache Spark: виды и особенности реализации Напомним,...
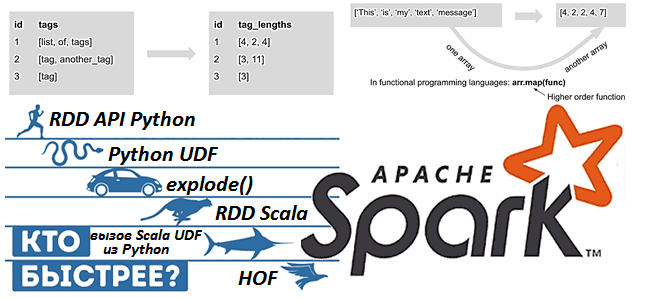
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий...
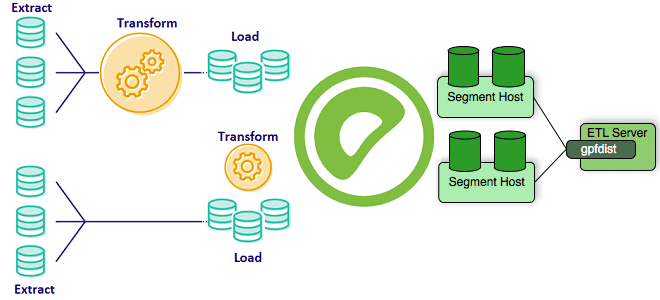
Greenplum часто используется в качестве корпоративного хранилища или аналитического озера данных (Data Lake). Поэтому важно знать особенности реализации ETL-процессов при работе с этой MPP-СУБД, что входит в наш новый курс «Greenplum для инженеров данных». Сегодня рассмотрим способы загрузить большие данные в Greenplum, разберем отличия внешних таблиц от внутренних и отметим,...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...