
Сегодня разберем практический вопрос из обучения администраторов кластера Apache Kafka и разработчиков распределенных приложений. Про исключения в Kafka-приложениях: какие они бывают, почему случаются, с какими параметрами конфигурации связаны и что могут сказать о тонкостях потоковой обработки больших данных. Исключения и транзакции в Apache Kafka В ИТ под исключением понимается исключительная...

Чем хороши JSON-файлы и как с ними работать в Apache Spark и Hive: проблемы обработки вложенных структур данных и способы их решения на практических примерах. Как автоматизировать переименование некорректных названий полей во вложенных структурах данных JSON-файлов на любом количестве таблиц со множеством полей, чтобы создать таблицу в Hive Metastore и...
Недавно мы писали про пользу snapshot’ов Apache HBase на примере компании Vimeo. Сегодня рассмотрим кейс корпорации Box, которая специализируется на облачных enterprise-продуктах совместного управления контентом и файлами. Переход от локальной HBase к Google Cloud BigTable: сложности миграции и способы их обхода. Сходства и различия Apache HBase с Google Cloud BigTable...

Разбираемся с механизмами отказоустойчивости Flink-приложений. Что такое контрольные точки (Checkpoint), чем они отличаются от точек сохранения (Savepoint) и что между ними общего. А также при чем здесь snapshot, что выбирать в разных случаях и как это использовать для отказоустойчивости stateful-приложений Apache Flink. Snapshot как механизм обеспечения отказоустойчивости приложений Apache Flink...
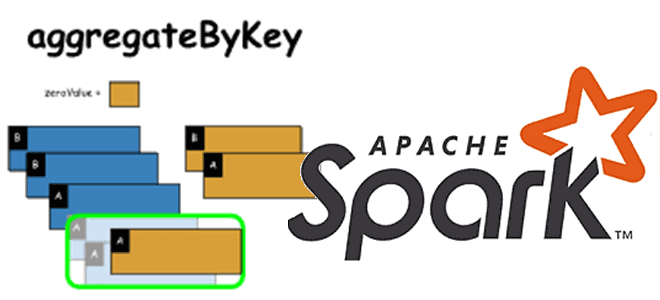
В рамках обучения дата-аналитиков и разработчиков Spark-приложений, сегодня рассмотрим одну из агрегатных функций обработки данных в этом распределенном вычислительном фреймворке. Чем aggregateByKey() отличается от reduceByKey() и groupByKey(), и когда стоит ее использовать. Как устроена функция aggregateByKey(): назначение и синтаксис Функция aggregateByKey() - одна из агрегатных функций, наряду с reduceByKey() и...

Чтобы сделать наши курсы по Apache Kafka для администраторов кластеров и разработчиков распределенных приложений еще более полезными, сегодня рассмотрим несколько полезных и значимых конфигурационных параметров этой платформы потоковой передачи событий. Что настроить на брокере, топике, продюсере и потребителе, как распараллелить потоки и обрабатывать транзакции. Настройка брокеров и потоков в Apache...

Добавляя новые интересные примеры в наши курсы для дата-аналитиков, разработчиков распределенных приложений и администраторов SQL-on-Hadoop, сегодня рассмотрим опыт видеоаналитики в компании Vimeo с использованием Apache Spark. Как быстро запросить множество данных из Apache HDFS через Phoenix и Spark из моментальных снимков HBase с минимальным влиянием на кластер. Аналитика очень больших...

Сегодня рассмотрим кейс международной ИТ-компании AppsFlyer, которая создает SaaS-решения для маркетинговой аналитики в режиме онлайн. В этой статье команда разработки аналитического продукта Data Locker делится опытом оптимизации ETL-приложений Apache Spark для снижения стоимости обработки данных и ускорения вычислений. Предыстория: слишком много файлов в ETL-решении на Spark и AWS S3 в...

В этой статье для дата-аналитиков и разработчиков Neo4j, разберем, как реализовать GraphQL-сервер для взаимодействия с этой графовой NoSQL-СУБД. Библиотека Neo4j GraphQL и ее практическое применение для графовой аналитики больших данных в бизнес-приложениях. Еще раз про GraphQL О том, что такое GraphQL (GQL) и как это связано с архитектурным стилем REST, мы писали...
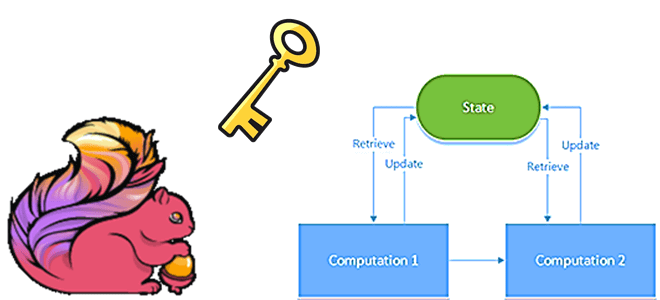
Что такое состояния в приложениях Apache Flink, каких видов они бывают, как ими управлять и зачем это нужно: основы разработки stateful-заданий и API DataStream. Чем состояние с ключом отличается от оператора состояния и почему первый чаще используется на практике. Состояния в Apache Flink Apache Flink поддерживает как stateful-, так и...

В рамках обучения разработчиков Spark-приложений и дата-инженеров, сегодня рассмотрим, что такое локальность данных и как это влияет на производительность заданий. А также разберем, где в UI Apache Spark посмотреть нахождение данных для распределенных вычислений и какие параметры конфигурации следует настроить, чтобы повысить скорость их выполнения. Что такое локальность данных в...
В этой статье разберем кейс бразильской фудтех-компании Ifood по реализации микросервисной ML-системы на Apache Kafka и serverless NoSQL-СУБД DynamoDB с пропускной способностью миллиарды сообщений в секунду. Сложности масштабирования микросервисов и оперативное чтение данных из Feature Store с помощью библиотеки Sarama – Go-клиента для Apache Kafka. Проблема микросервисов при множестве обращений...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня поговорим про визуализацию графов в NoSQL-СУБД Neo4j. А также рассмотрим, как с помощью GraphKer получить визуальное отображение графа данных о информационной безопасности: уязвимости, атаки и прочие нарушения cybersecurity. ТОП-5 способов визуализации графов в Neo4j Поскольку люди лучше воспринимают визуальную информацию, инструменты...

О том, что такое spill-эффект, мы недавно писали на примере Apache Spark. Однако, проблема переброса данных из оперативной памяти на жёсткий диск и обратна характерна и для Greenplum. Где посмотреть количество и объем spill-файлов, а также как устранить причину их образования с помощью конфигурационных параметров и инструментов администратора. Что такое...
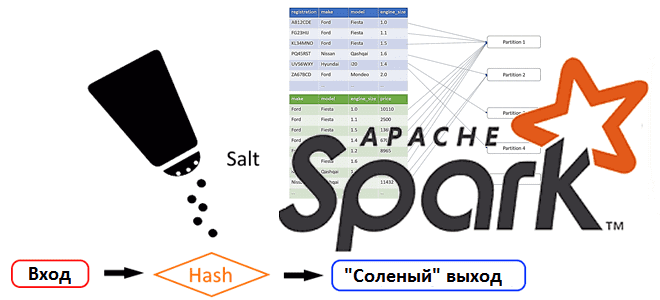
В этой статье для разработчиков Spark-приложений рассмотрим, как избежать искаженных данных с помощью простого и давно известного в криптографии приема, который принято называть «соль». Почему неравномерное распределение данных может вызвать ошибку нехватки памяти и как сбалансировать распределение ключей, добавив столбец со случайными числами. Перекосы и перемешивания Искажение или неравномерное распределение...

Ранее мы писали о том, как фотохостинг Pinterest с помощью новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, объединяет пакетную и потоковую аналитику больших данных, чтобы еще лучше обслуживать более 475 миллионов своих пользователей. Сегодня поговорим про контроль сетевого трафика и синхронизацию источников данных через генерацию...

Недавно мы рассказывали про KubeMQ – stateless-сервис обмена сообщениями для Kubernetes, который может заменить собой сложное развертывание Apache Kafka на этой платформе управления контейнерами. Сегодня разберем, как устроен KubeMQ и сравним его с Apache Kafka по нескольким параметрам, наиболее интересным для разработчиков распределенных приложений и администраторов. Операторы и пользовательские ресурсы...
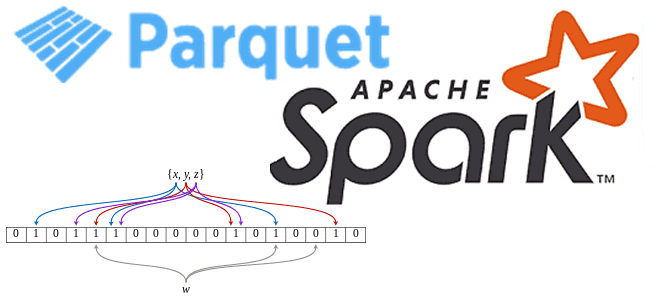
Сегодня рассмотрим, что такое фильтр Блума и как эта структура данных используется в Apache Spark для чтения Parquet-файлов. Про хеширование, UUID, достоинства и недостатки Bloom-фильтра для бинарного колоночного формата хранения больших данных в распределенных системах. Что такое фильтр Блума Фильтр Блума активно используется во многих информационных системах для быстрого поиска...
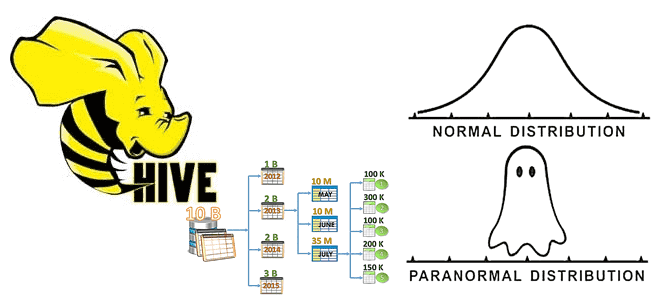
Мы уже писали, зачем нужна статистика таблиц при оптимизации SQL-запросов на примере Greenplum. Сегодня рассмотрим, как собрать статистические данные в таблицах Apache Hive, каким образом это поможет оптимизатору запросов и какие есть способы сбора статистики в этом популярном инструменте стека SQL-on-Hadoop. Еще раз о пользе статистики для оптимизации запросов в...
Продвигая наши курсы по прикладной Data Science и графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим специальную DS-библиотеку в Neo4j и ее возможности для фильтрации подграфов. А также разберем, чем версия сообщества отличается от Enterprise Edition, как запустить анализ слабо связанных компонент и алгоритм определения центральности на проекции графа в памяти. Graph...