
В этой статье для обучения дата-инженеров и разработчиков распределенных приложений, сегодня разберем опыт ИТ-компании Similarweb, где Apache Spark на платформе Databricks вместо AWS Athena ускорил пакетную обработку данных в 50 раз. Также рассмотрим приемы повышения производительности ODBC-драйвера Databricks для улучшенного взаимодействия с озерами данных. Постановка задачи и ограничения POC для...

Сегодня рассмотрим, что такое воронки, шаблоны, порты и группы процессоров в Apache NiFi и как эти элементы помогают дата-инженеру эффективно проектировать потоковые конвейеры обработки данных. Из чего состоит конвейер обработки данных в Apache NiFi: обзор элементов Благодаря веб-GUI Apache NiFi позволяет дата-инженеру быстро создавать конвейеры потоковой обработки данных, просто располагая...
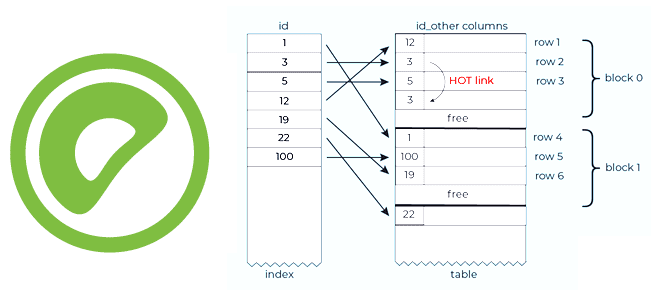
Чтобы сделать наши курсы по Greenplum еще более полезными, сегодня разберем особенности индексов и накладываемых ими ограничений на SQL-запросы к таблицам этой MPP-СУБД. Что такое уникальные индексы и как они поддерживаются в таблицах, оптимизированных для добавления, в Greenplum версии 7, выпущенной в середине декабря 2022 года. Еще раз о пользе...
Как использовать мощь Apache Kafka в ИТ-архитектуре корпоративных приложений и интеграции информационных систем: краткий ликбез по ключевым принципам работы этой платформы потоковой передачи событий и важность дата-контрактов для инженера данных, разработчика и архитектора. 9 лучших практик использования Apache Kafka в архитектуре приложений Чтобы успешно применять Apache Kafka в качестве основной...
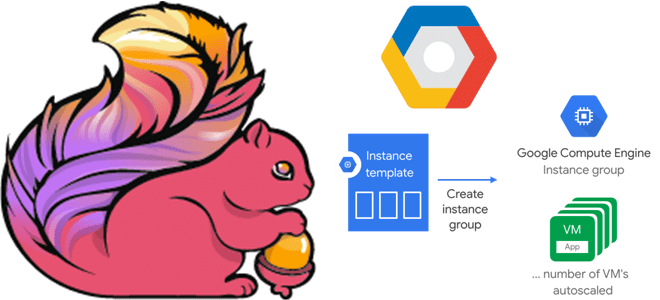
В этой статье для дата-инженеров и разработчиков Flink-приложений рассмотрим, как связаны диспетчеры задач и заданий, зачем настраивать автоматическое масштабирование кластера и как это сделать с помощью Google Auto Scaler в облачной инфраструктуре этого провайдера. Роль диспетчера заданий в Apache Flink и механизмы отказоустойчивости Apache Flink — отличный фреймворк создания приложений...

Учитывая рост интереса к DevOps-инструментам, сегодня рассмотрим, зачем переводить кластер Apache Spark, управляемый YARN, в Kubernetes, и как это сделать наиболее эффективно. А также разберем, какие системные метрики контейнерных Spark-приложений надо отслеживать и с помощью каких средств. Зачем переводить кластер Apache Spark от YARN на Kubernetes Apache Spark не зря...
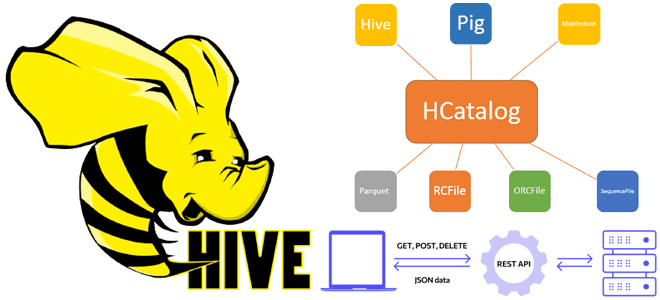
Сегодня рассмотрим, что такое WebHCat в Apache Hive и как этот REST API позволяет взаимодействовать с HCatalog, используя стандартные HTTP-методы. Еще разберем, какие DDL-команды Hive и HiveQL не поддерживает HCatalog, а также что полезного может быть в лог-файлах Templeton. Принципы работы компонента WebHCat как REST-сервиса Apache Hive Будучи NoSQL-хранилищем класса...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня рассмотрим, какие интерфейсы и протоколы для связи клиента с брокером использует эта платформа потоковой передачи событий. А также рассмотрим, что обеспечивает двунаправленную совместимость API. Протоколы и интерфейсы Apache Kafka для общения клиентов с брокерами Apache Kafka использует бинарный протокол...
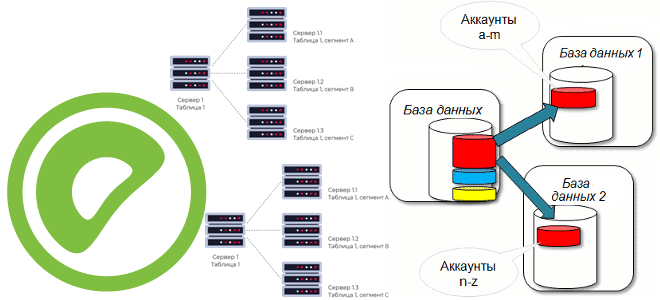
В этой статье для дата-инженеров и ИТ-архитекторов поговорим про шардирование баз данных и разберем, как этот способ горизонтального масштабирования системы реализуется в MPP-СУБД Greenplum, при чем здесь ключ дистрибуции и как его задать. Что такое шардирование БД и как оно работает Чтобы повысить производительность приложения через увеличение пропускной способности СУБД...

Недавно мы писали про Apache NiFi 1.18. А 28 ноября опубликован новый выпуск - 1.19.0 и спустя немного времени первый баг-фикс к нему. Разбираемся с новинками свежего релиза самого популярного потокового ETL-маршрутизатора: новые процессоры, исправления ошибок и улучшения, о которых следует знать дата-инженеру и администратору кластера. Главные новости Apache NiFi...

Чтобы добавить в наши курсы по аналитики больших данных еще больше практически примеров, сегодня рассмотрим, как современные технологий Big Data помогают в реальном времени выявлять телекоммуникационные мошенничества. Почему для антифрод-задач особенно подходит Apache Flink с его потоковом движком обработки данных и за счет чего этот фреймворк такой быстрый. Антифрод в...

В этой статье для обучения ИТ-архитекторов и дата-инженеров сравним 2 подхода к аналитике больших данных, чтобы решить, когда потоковые вычисления, например, средствами ksqlDB в рамках Apache Kafka лучше аналитических баз данных реального времени, таких как Rockset, и наоборот. 2 способа выполнения аналитики больших данных в реальном времени Современный бизнес и...

Недавно мы писали про чтение данных из AWS S3 с помощью PySpark-задний. Продолжая разбираться, как перейти от HDFS к облачным объектным хранилищам, сегодня рассмотрим пример чтения и записи файлов из Google Cloud Storage с помощью Apache Spark. От HDFS к GCS Распределенная файловая система Apache Hadoop (HDFS) уже много лет...

Сегодня заглянем под капот Apache Kafka и рассмотрим, как на программном уровне работает упаковка сообщений от приложения-продюсера в пакеты перед их отправкой в топик платформы. Что такое RecordAccumulator, какие конфигурации с ним связаны и почему такое пакетирование обеспечивает эффективность потоковой обработки данных. Как устроено пакетирование потоковой обработки в Apache Kafka...

16 ноября 2022 года вышел 2-ой альфа-релиз Apache Hive 4.0.0. Какие ошибки в нем исправлены и что за новые функции, важные для дата-инженера и администратора кластера Hadoop, появились. А перед этим вспомним основные принципы работы Apache Hive. Принципы работы Apache Hive Apache Hive является популярным инструментом стека SQL-on-Hadoop, позволяя обращаться...

В этой статье для обучения дата-инженеров и администраторов кластера Apache NiFi познакомимся с NiFiKop – оператором, который упрощает запуск потокового ETL-маршрутизатора на платформе контейнерной виртуализации Kubernetes. 4 трудности управления кластером Apache NiFi При том, что Apache NiFI имеет множество достоинств, предоставляя возможности сбора, маршрутизации и обогащения потоков данных из разных...

Мы уже разбирали некоторые советы оптимизации Flink-приложений, связанные с неравномерным распределением данных по вычислительным узлам. Сегодня рассмотрим, как при этом пригодится паттерн MapReduce Combiner, который часто используется в экосистеме Apache Hadoop и вместо него лучше применить Bundle оператор, доступный с версии Flink 1.15. Проблема неравномерного распределения в Big Data вообще...

Недавно мы писали про новинки сентябрьского и октябрьского релизов Greenplum 6.22, а 18 ноября 2022 года вышла новая отладочная версия, которая решает некоторые проблемы с сервером СУБД, обработкой запросов и потоком данных. Разбираемся, что стало лучше в VMware Tanzu Greenplum 6.22.2 с точки зрения администратора кластера и дата-инженера. Новинки и...
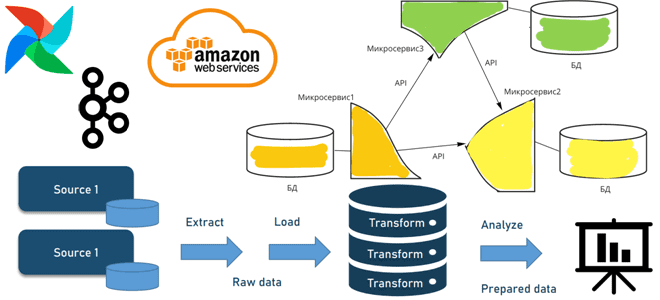
Когда и зачем переходить от пакетной парадигмы обработки к потоковой, как это сделать с помощью микросервисной архитектуры, какие проблемы могут при этом возникнуть и что за решения позволят их избежать. А в качестве примеров инструментальных средств рассмотрим сервисы AWS, Apache AirFlow и Kafka. От пакетов к потокам через микросервисы: архитектура...

Визуализация конвейеров обработки данных особенно важна в потоковой парадигме, поэтому мы часто рассматриваем полезные средства мониторинга для Apache Kafka. Сегодня разберем, что такое Streams Explorer от Bakdata и как это пригодится для дата-инженера. Проекты Bakdata для развертывания и мониторинга приложений Kafka Streams При работе с крупномасштабными потоковыми данными крайне важно...