
Развивая наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим, почему в этой MPP-СУБД возникают проблемы нехватки памяти, каковы типовые способы их решения и чем очереди ресурсов отличаются от ресурсных групп. Читайте далее про схемы управления ресурсами в Greenplum и особенности параметра конфигурации statement_mem. Очереди vs Группы: 2 схемы управления...

Чтобы добавить в наши практические курсы по Apache Kafka еще больше интересных примеров, сегодня рассмотрим кейс немецкой ИТ-компании Mobimeo, которая несколько раз перекраивала свою систему аналитики больших данных, чтобы быстро узнавать о событиях клиентских приложений. Читайте далее, зачем дата-инженеры Mobimeo предпочли AVRO формату JSON, почему вместо брокера сообщений ActiveMQ решили...

Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим некоторые особенности хранения данных в этой MPP-СУБД, а также разберем связанные с ними лучшие практики ее администрирования. Читайте далее про важность RAID-массивов, механизмы дублирования кластеров, утилиты резервного копирования и восстановления данных в Greenplum. RAID-массивы и зеркалирование жестких дисков...

Сегодня разберем еще одну интересную тему из нашего нового курса «Greenplum для инженеров данных» по построению конвейеров приема данных для этой MPP-СУБД в рамках веб-интерфейса платформы автоматизированного управления потоками работ Apache NiFi. Читайте далее, как устроен коннектор VMware Tanzu Greenplum для Apache NiFi и какие возможности он предоставляет дата-инженеру. Что...

Партиционирование таблиц – надежный способ повышения производительности Greenplum, который тесно связан с особенностями распределения данных по сегментам кластера. Читайте далее, чем опасно неравномерное распределение данных и вычислений по узлам, а также как найти дата-инженеру и устранить эти перекосы в MPP-СУБД, чтобы повысить скорость выполнения SQL-запросов и решить проблемы с нехваткой...
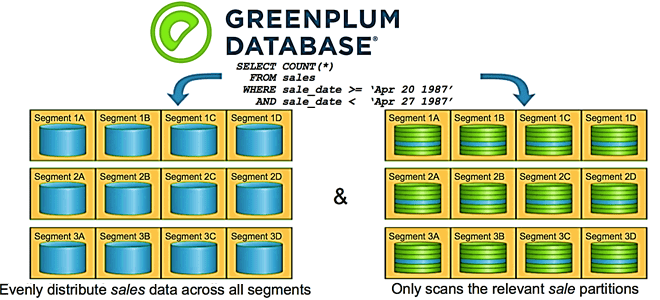
Мы уже рассказывали про основы хранения и аналитики больших данных в Greenplum, а также рассматривали особенности индексации и сжатия данных в этой MPP-СУБД. Продолжая разговор о нашем новом курсе «Greenplum для инженеров данных», сегодня разберем лучшие практики разбиения данных на разделы и пример их распределения по сегментам кластера. Кратко о...

В продолжение вчерашней статьи по нашему новому курсу «Greenplum для инженеров данных», сегодня рассмотрим особенности индексации и сжатия данных в этой MPP-СУБД. Читайте далее, почему в Greenplum можно обойтись без индексов, когда выбирать RLE-сжатие вместо zlib, зачем сжимать рабочие файлы при выполнении SQL-запросов и что такое селективность индекса. ТОП-10 советов по...

Продвигая наш новый курс «Greenplum для инженеров данных», сегодня мы рассмотрим особенности организации таблиц в этой MPP-СУБД, типы данных и оптимальное расположение столбцов. Читайте далее, чем heap storage отличается от append-optimized, когда выбирать колоночную, а когда – строковую модель хранения данных для таблицы, почему BIGINT с TIMESTAMP следует размещать перед...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Сегодня рассмотрим преимущества потоковой обработки данных с Apache Kafka и Flink над пакетными Big Data технологиями в виде Hadoop, Spark и Oozie. В качестве примера разберем реальный кейс аналитики больших данных по пользовательским сеансам в музыкальном онлайн-сервисе Spotify, а также возможность замены Apache Flink на Spark Structured Streaming. От рекламы...

В рамках обучения дата-инженеров, сегодня рассмотрим проблему роста числа операций ввода-вывода в секунду (IOPS) при обработке большого количества данных в потоках Apache NiFi и способы ее решения. Читайте далее, как перемещение репозиториев NiFi с жесткого диска в оперативную память снижает IOPS, а также зачем при этом в Big Data систему...

Поскольку наши курсы по Apache Spark предполагают практическое обучение с глубоким погружением в особенности разработки и настройки распределенных приложений, сегодня рассмотрим, как именно выполняются кластерные вычисления в рамках этого Big Data фреймворка. Читайте далее, из чего состоит архитектура Spark-приложения, как связаны SparkContext и SparkConf, а также зачем ограничивать размер драйвера...

Продолжая вчерашний разговор про потоковую аналитику больших данных на Apache Kafka и Pinot, сегодня рассмотрим особенности интеграции этих систем. Читайте далее, как входные данные Kafka разделяются, реплицируются и индексируются в Pinot, каким образом выполняется обработка данных через распределенные SQL-запросы. Также разберем, почему управление памятью серверов Pinot, потребляющих данные из Kafka,...

В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене...
Вчера мы упоминали, как долгожданный KIP-500, реализованный в марте 2021 года, позволяет не только отказаться от Zookeeper в кластере Apache Kafka, но и снимает ограничение числа разделов, чтобы масштабировать брокеры практически до бесконечности. Однако, не все так просто: читайте далее, какие важные функции еще не поддерживаются в этом экспериментальном режиме...
Сегодня рассмотрим важную практическую задачу из курсов Kafka для разработчиков и администраторов кластера – разделение топиков по брокерам. Читайте далее, как пропускная способность всей Big Data системы зависит от числа разделов, коэффициента репликации и ответного ack-параметра, а также при чем здесь KIP-500, позволяющий отказаться от Zookeeper. Что такое партиционирование в...

В поддержку курса Hadoop для инженеров данных сегодня разберем, в чем проблема безопасной отправки заданий и файлов в облачное хранилище Amazon S3 и как ее решить. Читайте далее, почему AWS S3 не дает гарантий согласованности как HDFS, из-за чего S3Guard не обеспечивает транзакционность и как настроить коммиттеры S3A для Spark...

Продолжая разговор про оптимизацию приложений Apache Spark в Kubernetes, сегодня разберем, как сократить расходы на облачный кластер с помощью спотовых узлов. А в качестве практического примера рассмотрим кейс компании Weather2020, дата-инженеры которой смогли всего за 3 недели развернуть террабайтные ETL-конвейеры в AWS с AirFlow и Spark на Kubernetes без глубокой...

Недавно мы рассказывали об особенностях запуска приложений Apache Spark в кластере Kubernetes с учетом новшеств релиза 3.1.1, где с этого варианта развертывания снят экспериментальный режим. В дополнение к ранее рассмотренным способам оптимизации Спарк-приложений, сегодня разберем, как инженеру Big Data ускорить их при запуске на платформе K8s. Как ускорить Spark-приложения на...

Сегодня рассмотрим особенности ухода с коммерческого дистрибутива Hadoop к версии сообщества на примере американской рекламной платформы Outbrain. Читайте далее, зачем дата-инженеры компании приняли такое решение, почему им не подошли альтернативы от MapR, Cloudera и Google Cloud Platform (DataProc), как проходила миграция на Apache Hadoop и что получилось в итоге. Предыстория:...