
Продолжая разбирать тонкости сериализации данных в Apache Kafka на практических примерах, сегодня рассмотрим кейс индийской ИТ-компании Naukri Engineering о повторной обработке сообщений и особенностях форматов. Читайте далее, чем хороши заголовки Kafka и почему их не так просто использовать, а также зачем писать свой сериализатор с десериализатором для достижения 100%-ного SLA....

Продолжая обучение дата-инженеров, сегодня рассмотрим, как сделать управление потоками данных в Apache NiFi эффективнее. Читайте далее, какие настройки позволят обойтись без процессора RetryFlowFile для повторных попыток, зачем менять GetFile на ListFile и FetchFile, когда использовать воронки и почему типичные настройки Linux не подходят для NiFi. Неочевидные особенности готовых процессоров Напомним,...

В недавней статье про оптимизацию SQL-запросов в Greenplum мы рассказывали про планы их выполнения и операторы просмотра этих планов. Сегодня разберем подробнее, какие операции с данными могут встретиться в отчете, сгенерированном командой EXPLAIN, а также рассмотрим, чем эта информация полезна дата-инженеру и аналитику данных. 5 операций в плане выполнения SQL-запросов...

В рамках нового курса Эксплуатация Apache NIFI, сегодня разберем особенности развертывания этого маршрутизатора потоков Big Data на платформе управления контейнерными приложениями Kubernetes. Советы дата-инженерам, как сократить расходы на AWS, избежать сбоев узлов и потерь данных, обеспечить безопасность и автоматическое масштабирование облачного кластера Apache NiFi в Amazon EKS, а также зачем...
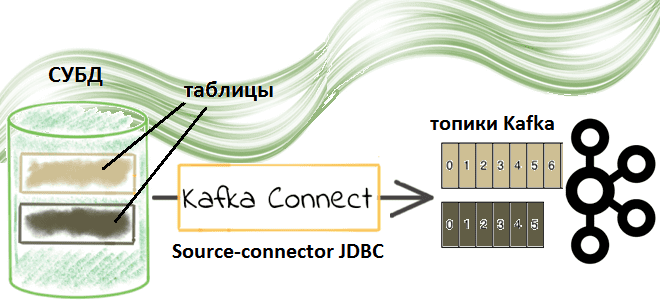
Недавно мы рассматривали пример потоковой передачи данных между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Сегодня заглянем под капот такой интеграции и разберем подробнее, что именно представляет собой JDBC-коннектор источника Kafka от Confluent. Компоненты Kafka Confluent для потоковой интеграции данных: коннекторы и реестр схем...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...
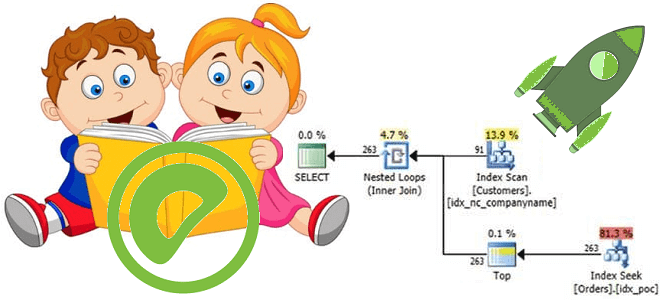
Обучая дата-аналитиков и инженеров данных тонкостям MPP-СУБД Greenplum, сегодня разберем, какой оператор помогает просмотреть план выполнения SQL-запроса, почему добавлять ANALYZE к EXPLAIN нужно с осторожностью и где найти универсальное решение анализа и визуализации PostgreSQL-совместимых продуктов. Я все объясню: команда EXPLAIN в PostgreSQL Разобравшись с оператором анализа и сбора статистики по...

Запуская наш новый курс по Эксплуатация Apache NIFI, сегодня рассмотрим 3 популярных вопроса про этот Big Data фреймворк с комментариями компании Cloudera. Читайте далее, может ли NiFi заменить пакетные ETL-оркестраторы, как использовать REST API для управления потоками данных в этом фреймворке, а также где настраивать политики управления доступом в многопользовательской...

Сегодня в рамках обучения разработчиков распределенных приложений и дата-инженеров рассмотрим практический пример потоковой интеграции данных из 2-х разных источников с Apache Kafka. Читайте далее, как мгновенно передать данные между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Apache Kafka как средство потоковой интеграции данных Интеграция...

Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками. 3 бэкенда Apache Flink для хранения...

Чтобы сделать наши курсы по Greenplum и аналитике больших данных еще более полезными, сегодня рассмотрим особенности выполнения SQL-запросов в этой MPP-СУБД. Читайте далее, зачем и когда запускать оператор анализа табличной статистики ANALYZE, как он связан с планом выполнения SQL-запроса и какие инструменты помогут дата-инженеру, аналитику или разработчику повысить их производительность....
Сегодня рассмотрим 2 важных понятия архитектуры распределенных систем для хранения и аналитики больших данных на примере платформы потоковой обработки событий Apache Kafka.Читайте далее, что такое согласованность и полнота, а также в чем преимущества строго однократной доставки сообщений на основе транзакционной записи и фиксации смещений в журналах, и как все это...
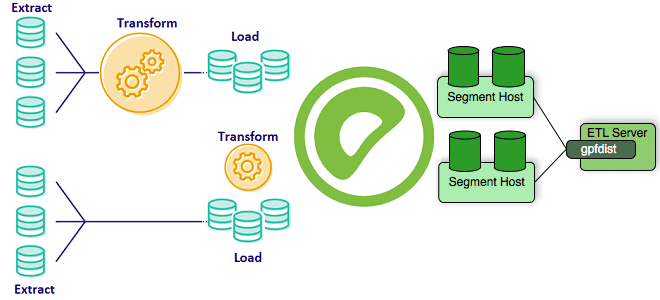
Greenplum часто используется в качестве корпоративного хранилища или аналитического озера данных (Data Lake). Поэтому важно знать особенности реализации ETL-процессов при работе с этой MPP-СУБД, что входит в наш новый курс «Greenplum для инженеров данных». Сегодня рассмотрим способы загрузить большие данные в Greenplum, разберем отличия внешних таблиц от внутренних и отметим,...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...
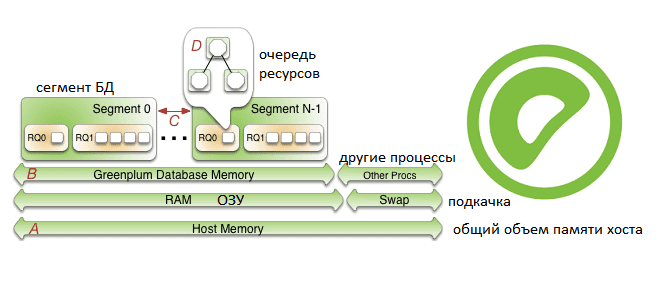
Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня поговорим про особенности конфигурирования памяти в этой MPP-СУБД: разберем, как память хоста распределяется между сегментами и рассмотрим, как администратор кластера может ускорить работу этой базы данных. Также читайте далее о связи RAM с настройками ядра операционной системы и схемами...
Чтобы сделать обучение разработчиков Apache Spark, дата-аналитиков и инженеров Big Data еще более наглядным, сегодня рассмотрим проблему JOIN-соединений при неравномерном распределении данных по узлам кластера и способы ее решения. Читайте далее, как избавиться от перекосов и ускорить выполнение SQL-запросов в Spark-приложениях. Перекосы данных в Apache Spark: что это и чем...

Вчера мы рассказывали, почему некоторые OOM-ошибки stateful-приложений Kafka Streams могут быть вызваны некорректной работой RocksDB – встроенного key-value NoSQL-хранилище состояний. Сегодня рассмотрим, какие проблемы с дисковыми операциями характерны для этой СУБД, как они отражаются на Kafka-приложениях потоковой аналитики больших данных и каким образом можно это исправить. Быстрые диски, RocksDB и...

Сегодня заглянем под капот stateful-приложений Kafka Streams и рассмотрим, что такое RocksDB, как устроено это key-value NoSQL-хранилище и почему его необходимо настраивать для быстрой и безотказной работы приложений потоковой аналитики больших данных. Читайте далее, какие проблемы приложений Kafka Streams связаны с RocksDB и как ограничить повышенное потребление оперативной памяти. Что...

Cегодня рассмотрим некоторые инструменты защиты данных в Greenplum. Читайте далее про особенности шифрования в этой MPP-СУБД и лучшие практики обеспечения информационной безопасности и защиты в этой системе хранения и аналитики больших данных. Администраторы и суперпользователи Greenplum Для надежной защиты данных, хранящихся в MPP-СУБД Greenplum, и обеспечения информационной безопасности кластера рекомендуется...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...