
Всего через 1,5 месяца после выпуска версии 1.15.0, 22 декабря 2021 года вышел очередной релиз Apache NiFi. Разбираем главные новинки и исправленные баги, а также смотрим, как команда разработчиков решила избавиться от уязвимости Log4Shell. Не только Log4j: еще 3 исправленных ошибки Декабрьский релиз Apache NiFi не может похвастаться внушительным списков...
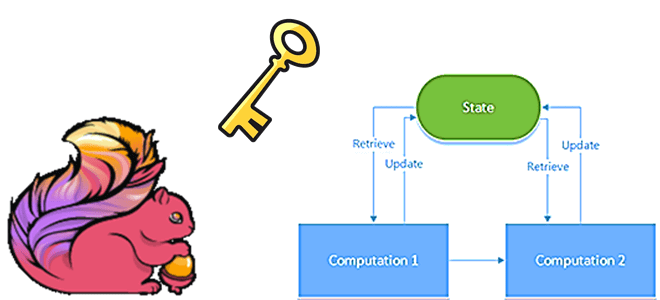
Что такое состояния в приложениях Apache Flink, каких видов они бывают, как ими управлять и зачем это нужно: основы разработки stateful-заданий и API DataStream. Чем состояние с ключом отличается от оператора состояния и почему первый чаще используется на практике. Состояния в Apache Flink Apache Flink поддерживает как stateful-, так и...
В этой статье разберем кейс бразильской фудтех-компании Ifood по реализации микросервисной ML-системы на Apache Kafka и serverless NoSQL-СУБД DynamoDB с пропускной способностью миллиарды сообщений в секунду. Сложности масштабирования микросервисов и оперативное чтение данных из Feature Store с помощью библиотеки Sarama – Go-клиента для Apache Kafka. Проблема микросервисов при множестве обращений...
Сегодня разберемся с serverless-технологиями и рассмотрим, как самостоятельно создать и интегрировать бессерверный парсер Selenium с Apache Nifi. Краткий ликбез по OpenFaaS, Selenium и Chromium, а также преимущества serverless-технологий и пример вызова функции сбора данных с веб-страницы на Python. Введение: serverless, OpenFaaS и Selenium с Chromium Serverless-стратегия организации платформенных облачных услуг,...

О том, что такое spill-эффект, мы недавно писали на примере Apache Spark. Однако, проблема переброса данных из оперативной памяти на жёсткий диск и обратна характерна и для Greenplum. Где посмотреть количество и объем spill-файлов, а также как устранить причину их образования с помощью конфигурационных параметров и инструментов администратора. Что такое...

Недавно мы рассказывали про KubeMQ – stateless-сервис обмена сообщениями для Kubernetes, который может заменить собой сложное развертывание Apache Kafka на этой платформе управления контейнерами. Сегодня разберем, как устроен KubeMQ и сравним его с Apache Kafka по нескольким параметрам, наиболее интересным для разработчиков распределенных приложений и администраторов. Операторы и пользовательские ресурсы...

Сегодня разберем пример европейской логистической компании Sixfold, которая смогла увеличить пропускную способность своей системы мониторинга транспортных отгрузок на базе Apache Kafka и Kubernetes. Также рассмотрим, как дата-инженеры Sixfold справились с проблемами изоляции при последовательной обработке сообщений и транзакционной записи в топики Kafka с базами данных отдельных микросервисов на подах Kubernetes....

В этой статье для разработчиков распределенных приложений разберем проблему с производительностью Apache Spark из-за неоптимальной стратегии переброса данных между оперативной и постоянной памятью. Что такое spill-эффект, почему он случается, как его идентифицировать и устранить. Что такое spill и почему он случается: под капотом Spark-приложений При том, что spill можно рассматривать...

7 ноября 2021 года вышел очередной релиз Apache NiFi с новыми фичами, улучшениями и исправлениями ошибок. Краткий обзор самых важных новинок: от постоянного хранилища для stateless-потоков и настроек облачных провайдеров до интеграции процессоров с пользователями Kerberos и улучшения работы с GitHub. Новинки и улучшения Apache NiFi 1.15.0 Свежий выпуск Apache...

Сегодня рассмотрим, как индийская ИТ-компания Razorpay с помощью Apache Flink и Kafka свела к минимуму время простоя своего главного продукта - платежного шлюза для интернет-магазинов. Как всего 2 задания Flink могут быстро обнаруживать простои более 50 когорт событий на уровне платежного шлюза и 200+ когорт разных интернет-магазинов. Работать нельзя остановиться:...

Недавно мы рассказывали про оптимизацию SQL-запросов в PXF – интеграционном фреймворке Greenplum. Сегодня рассмотрим, как этот способ обращения к внешним источникам данных можно применить к задачам машинного обучения на примере распознавания изображений. Platform Extension Framework как инструмент извлечения и преобразования изображений из облачных объектных хранилищ для обучений глубоких нейросетей с...
Мы уже писали о сложностях развертывания Apache Kafka на платформе управления контейнерами Kubernetes. Некоторые из этих проблем отлично решает KubeMQ – брокер очередей сообщений на Kubernetes. Зачем нужна очередная служба обмена данными, как она устроена и при чем здесь Kafka. Проблемы Kafka на Kubernetes и не только Сложная архитектура современных...

Сегодня рассмотрим, как организовать полностью сохраняемый сервис Apache NiFi с помощью Docker, чтобы обеспечить безопасность конвейеров и потоков данных при изменении конфигураций и перезапуске служб. А также разберем, как дата-инженеру и администратору кластера NiFi запустить его на Kubernetes. Проблемы масштабирования и отказоустойчивости Apache NiFi Благодаря наличию веб-GUI, множеству готовых процессоров...
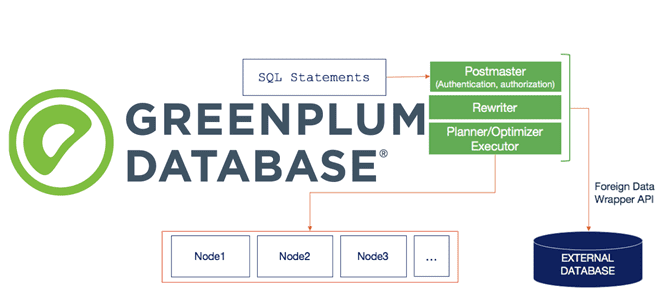
Сегодня продолжим разбираться с интеграционным фреймворком Greenplum и рассмотрим, как PXF реализует SQL-запросы к различным OLAP и OLTP-источникам, поддерживая разные форматы данных. Зачем создавать внешнюю таблицу для Greenplum и какие параметры при этом указывать, а также чем хороша технология оптимизации pushdown. SQL и PXF: интеграция Greenplum с внешними источниками на...
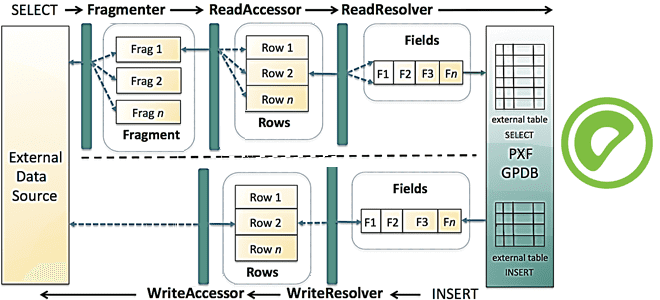
Специально для дата-инженеров, разработчиков OLAP-конвейеров и архитекторов DWH на MPP-СУБД Greenplum и Arenadata DB сегодня рассмотрим, что представляет собой PXF, из каких компонентов он состоит и как они взаимодействуют друг с другом, чтобы обеспечить параллельный высокопроизводительный доступ к данным и объединенную обработку запросов к разнородным источникам. Что PXF и зачем...
Добавляя в наши курсы по Apache Kafka еще больше полезных кейсов, сегодня рассмотрим пример интеграции этой распределенной платформы потоковой передачи событий с масштабируемой key-value СУБД GridDB через JDBC-коннекторы Kafka Connect. Apache Kafka как источник данных: source-коннектор JDBC Apache Kafka часто используется в качестве источника или приемника данных для аналитической обработки...
Чтобы добавить в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как построить конвейер преобразования CSV-файлов и загрузить данные в масштабируемую NoSQL-СУБД GridDB с помощью Apache NiFi. Краткий ликбез по GridDB и Apache NiFi в кейсе построения ML-системы для анализа данных временных рядов. Анализ данных временных рядов c...

Постоянно обновляя наши курсы по Apache Kafka, сегодня рассмотрим еще один полезный инструмент для администраторов, дата-инженеров и разработчиков, который повышает эффективность взаимодействия с этой распределенной платформой потоковой обработки событий. Что такое Saamsa, какие проблемы Kafka она решает и как ее использовать на практике. 5 вопросов разработчика и дата-инженера к Apache...
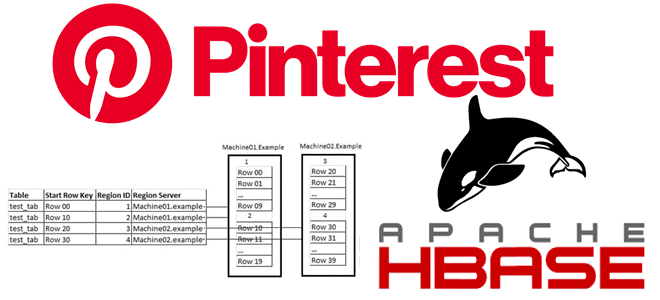
Обучая дата-инженеров и разработчиков распределенных приложений для аналитики больших данных, сегодня рассмотрим кейс компании Pinterest по построению масштабируемого решения для индексации записей в Apache HBase. Чем хранилище Ixia отличается от Lily HBase Indexer, зачем понадобился собственный аналог Solr и ElasticSearch, а также как все это работает в реальном времени с...

Недавно мы писали про платформы потоковой обработки событий, альтернативные Apache Kafka и Flink/Spark Streaming. В продолжение этой темы сегодня рассмотрим еще пару вариантов для разработки и самообслуживаемого использования потоковых конвейеров аналитики больших данных: DataCater и Flow. Читайте далее, что это за системы, как они связаны с Apache Kafka и какова...