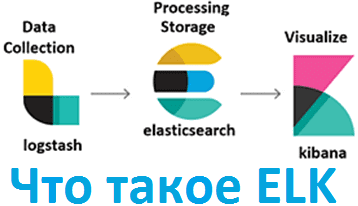
В этой статье рассмотрим ELK-инфраструктуру: разберем, зачем поисковый движок Elasticsearch использует сборщик логов Logstash и при чем здесь визуальный интерфейс Kibana. Также поговорим, в каких Big Data проектах используются эти системы и для чего. Зачем вам Elasticsearch: полнотекстовый поиск по Big Data Чтобы определить, почему деньги пропали с банковского счета или...

Выбирая курсы по Spark, Hadoop, Kafka и другим технологиям больших данных, легко запутаться во многочисленных предложениях от различных учебных центров и платформах онлайн-обучения. Сегодня мы расскажем, что должна включать программа курса по Big Data, чтобы результат обучения оправдал ваши ожидания и даже превзошел их. 4 главных свойства эффективного курса по...

Обычно курсы по Spark подробно рассказывают, чем хорош этот Big Data фреймворк для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных. Но, чтобы обучение Apache Spark было максимально полезным, стоит знать и о недостатках этого многофункционального инструмента обработки больших данных. Сегодня мы рассмотрим некоторые проблемы, которые возникают при практическом...

Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления...

Для высоконагруженных Big Data систем и платформ интернета вещей (Internet of Things, IoT) с непрерывными информационными потоками Apache Kafka, практически, стала стандартом де факто для обмена сообщениями и управления очередями. Аналогичную популярность среди DevOps-инструментов завоевал Kubernetes (K8s) как наиболее мощное средство для автоматизации развертывания и управления контейнеризованными приложениями. В этой...

Мы уже упоминали Apache Kafka в статье про промышленный интернет вещей (Industrial Internet Of Things, IIoT). Сегодня поговорим о том, где и для чего еще в Big Data проектах используется эта распределённая, горизонтально масштабируемая система обработки сообщений. Как работает Apache Kafka Apache Kafka позволяет в режиме онлайн обеспечить сбор и...

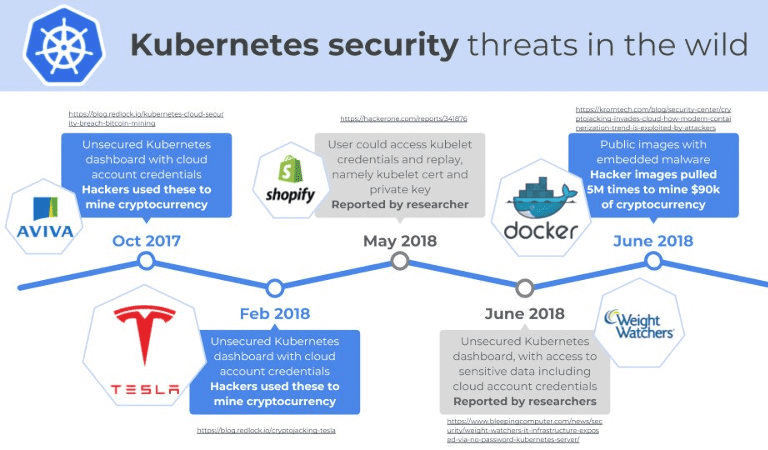
Проанализировав самые критичные уязвимости Kubernetes за последние 2 года и ключевые факторы их возникновения, сегодня мы поговорим, как DevOps-инженеру и администратору обеспечить информационную безопасность в контейнерах Kubernetes для их эффективного применения в Big Data системах. Лучшие практики cybersecurity для Kubernetes Комплексную безопасность кластера Kubernetes и больших данных, которые там хранятся...

Мы уже рассказывали про самые критичные уязвимости Kubernetes за последние 2 года. Продолжая тему информационной безопасности в контейнерах Big Data систем, сегодня мы поговорим, почему популярнейшая DevOps-технология так чувствительна к хакерским атакам. Читайте в нашей статье об основных факторах нарушения cybersecurity в DevOps-инфраструктуре на примере Kubernetes и Docker. Основные векторы...
В продолжении темы контейнеризации приложений и применения этой технологии в Big Data системах, сегодня мы поговорим, действительно она абсолютно безопасна. А также насколько популярнейшая DevOps-технология, Kubernetes, «великий кормчий» среди систем оркестрации контейнеров, соответствует своему визуальному образу «неуязвимого» океанического лайнера. Спойлер: на самом деле нет, K8s, как и любые другие технологии...

Мы уже рассказывали про достоинства и недостатки самой популярной DevOps-технологии 2019 года – платформы управления контейнерами Kubernetes для Big Data систем. Сегодня поговорим, зачем вообще нужны контейнеры, чем они отличаются от виртуальных машин, каковы их плюсы и минусы, а также для чего нужна их оркестрация. Что такое контейнеризация приложений и...

Сегодня, когда ИТ-компании распиливают монолиты своих Big Data систем на микросервисы, а DevOps-подход совершает свое победное шествие по локальным и облачным кластерам, Kubernetes стал, пожалуй, самой востребованной технологией 2019 года. Однако, K8s нужен далеко не каждому проекту. В этой статье мы поговорим о достоинствах и недостатках кубернетис, в каких случаях...

В прошлых выпусках мы рассмотрели, чем занимаются аналитик (Data Analyst), исследователь (Data Scientist) и инженер больших данных (Data Engineer). Завершая цикл статей о самых популярных профессиях Big Data, поговорим об администраторе больших данных – его рабочих обязанностях, профессиональных компетенциях, зарплате и отличиях от других специалистов. Итак, в сегодняшней статье –...

Продолжая тему развития Agile, сегодня мы расскажем о новом видении DevOps, предполагающем полный отказ от девопс-инженеров при сохранении всех принципов этого похода. Читайте в нашей статье, что такое NoOps и как эта концепция реализуется в мире Big Data. 5 разных мнений о DevOps Хотя термину «DevOps» уже исполнилось более 10...

Несмотря на почти 20-летнюю историю термина «DevOps», даже в ИТ-среде до сих пор есть мнение, что все рабочие задачи этого девопс-инженера может выполнить рядовой системный администратор. Почему это не так и как обстоят дела с администрированием Big Data систем, читайте в нашей сегодняшней статье. Критерии и источники данных для сравнения...

Рассматривая облачные сервисы для Big Data проектов, мы уже говорили про SLA (Service Level Agreement, соглашение об уровне предоставления услуг) и упоминали показатели измерения эксплуатационной надежности в материале про эволюцию Agile-подходов. Читайте в нашей сегодняшней статье, как эти SRE-метрики помогают DevOps-инженерам и администраторам обосновать экономическую необходимость затрат на средства дополнительной защиты Big...
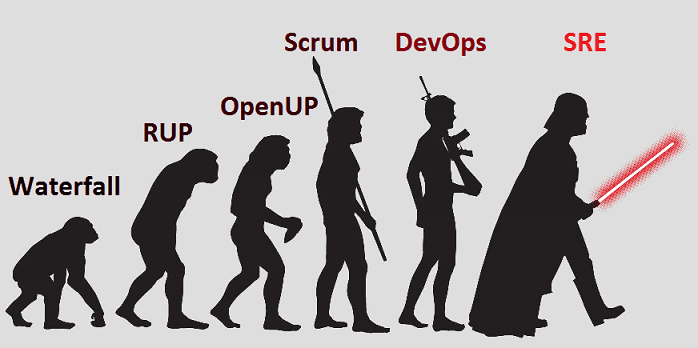
Большие данные требуют огромной гибкости и большой надежности – сегодня мы расскажем, что кто обеспечивает бесперебойную работу Google и других ИТ-гигантов и что нас ждет после DevOps. Читайте в нашей новой статье, как развиваются Agile-подходы к организации процессов разработки и эксплуатации Big Data систем и сколько это стоит. Что такое...

При всех достоинствах DevOps, этот, особенно популярный сейчас, подход к организации процессов разработки и эксплуатации ПО, не лишен недостатков. Сегодня мы поговорим о том, когда лучше обойтись без девопс и как его внедрить, если он не очень подходит, а очень хочется. Также расскажем, почему DevOps – не панацея и какие...

Ранее мы уже писали про DataOps- и DevOps-инженеров, а также про администраторов больших данных. Продолжая тему гибкого управления проектами (Agile) для повышения эффективности и ускорения бизнес-процессов, сегодня поговорим о том, какие еще специалисты нужны для успешного Big Data проекта. Профильные категории и процессы Big Data проекта Независимо от конечной цели...

Мы уже писали о происхождении термина DataOps, а также про методы и средства реализации этой концепции непрерывной интеграции данных между процессами, командами и системами в рамках data-driven company. Продолжая тему развития Agile-подходов в мире больших данных, сегодня рассмотрим, чем отличаются сферы ответственности DataOps- и DevOps-инженеров и почему оба этих специалиста...

DataOps (DATA Operations, датаопс), по аналогии с DevOps (DEVelopment Operations, девопс) — это концепция и набор практик непрерывной интеграции данных между процессами, командами и системами для повышения эффективности корпоративного управления или отраслевого взаимодействия за счет распределенного сбора, централизованной аналитики и гибкой политики доступа к информации с учетом ее конфиденциальности, ограничений на...