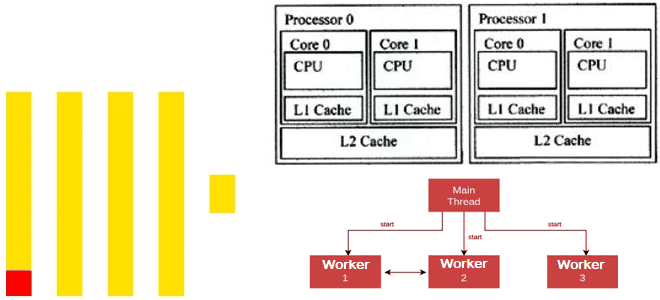
Как ClickHouse распараллеливает обработку данных для максимального использования всех ядер ЦП: особенности многопоточных вычислений в колоночной СУБД. Особенности многопоточной обработки в Clickhouse Современные центральные процессоры (ЦП) содержат несколько ядер и могут работать с несколькими задачами одновременно. Это называется многопоточной обработкой, где каждый поток, последовательность выполняемых инструкций, представляется как отдельная задача....
Зачем в ClickHouse 25.4 добавлена отложенная материализация и как ленивые вычисления позволяют ускорить работу аналитической СУБД благодаря сокращению объемов читаемых данных и снижению количества операций дискового ввода-вывода. Еще раз о пользе ленивых вычислений Отложенные или ленивые вычисления (lazy evaluation), которые выполняются не сразу, а откладываются до момента, когда их результат...
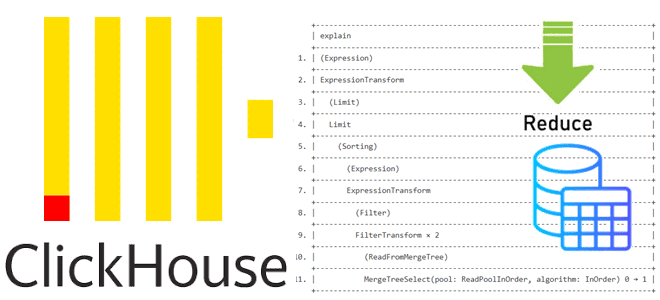
Как устроена оптимизация PREWHERE для сокращения объема сканируемых данных в ClickHouse: разбираемся с деталями реализации и смотрим планы выполнения SQL-запросов. Как устроена оптимизация PREWHERE в ClickHouse Недавно мы писали, как оптимизация PREWHERE позволяет сократить объем сканируемых данных и повысить скорость выполнения SQL-запроса в ClickHouse. Сегодня рассмотрим техническую реализацию этого оператора...
Как ускорить выполнение SQL-запроса в ClickHouse, сократив объем сканируемых данных с помощью оператора PREWHERE: практический пример простой, но эффективной оптимизации. Как работает оператор PREWHERE в ClickHouse ClickHouse имеет ряд многоуровневых оптимизаций, благодаря которым позволяет анализировать огромные объемы данных почти в реальном времени. Одной из таких оптимизаций является PREWHERE, которая сокращает...

Что общего у ClickHouse и StarRocks, чем они отличаются, и что выбирать для аналитики больших данных в реальном времени: сравнение колоночных OLAP-СУБД с векторным движком. Чем похожи ClickHouse и StarRocks: 7 главных сходств Хотя ClickHouse сегодня считается одной из наиболее популярных СУБД для аналитики больших данных в реальном времени с...
Как сократить затраты на хранение исторических данных в ClickHouse для ИИ-сценариев, сохранив высокую скорость аналитики по широким таблицам и озеру данных: эволюция колоночной СУБД в новом проекте с исходным кодом Antalya от Altinity. Проблемы совмещения ClickHouse с озерами данных и способы их решения Благодаря колоночной структуре хранения данных ClickHouse не...
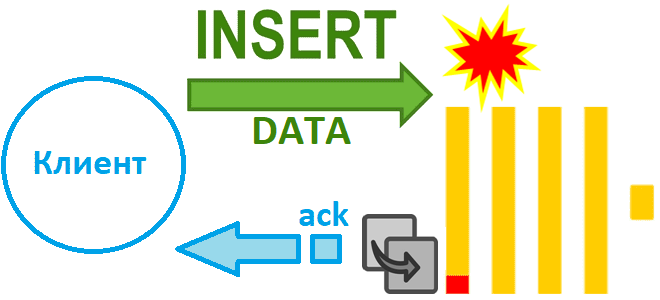
Как избежать потери данных при асинхронной вставке в Clickhouse при сбое сервера и зачем в версию 24.2 добавлен адаптивный тайм-аут очистки буфера: тонкости ETL с колоночной СУБД. Асинхронная вставка с возвратом подтверждения Недавно мы рассказали, чем хороши асинхронные вставки в ClickHouse и отметили, что при их использовании можно настроить параметр...
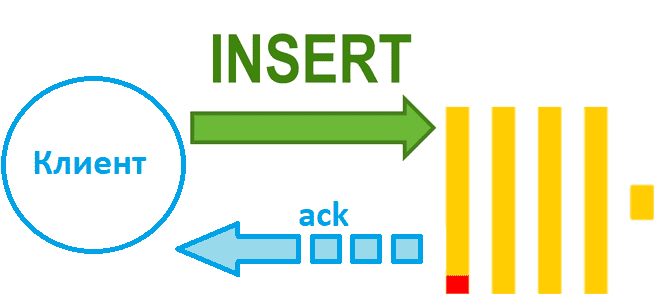
Чем синхронная вставка в ClickHouse отличается от асинхронной и как это настроить: лучшие практики и риски загрузки данных в колоночное хранилище. Синхронная вставка данных в ClickHouse Хотя скорость вставки данных в ClickHouse зависит от множества факторов, ее можно ускорить за счет асинхронных вставок, если предварительное пакетирование на стороне клиента невозможно....

Почему не рекомендуется публиковать в Kafka сообщения больших размеров, и как это сделать, если очень нужно: когда приходится перенастраивать конфигурации продюсера, топика и потребителя, и какие это параметры. Почему не нужно публиковать в Kafka сообщения больших размеров Apache Kafka, как и другие брокеры сообщений, оптимизирована для передачи данных небольшого размера....
Как именно формат, сортировка, сжатие и интерфейс передачи данных в ClickHouse влияют на скорость операций загрузки: бенчмаркинговое сравнение от разработчиков колоночной СУБД. В каком формате данные быстрее всего вставляются в ClickHouse Продолжая недавний разговор про вставку данных в ClickHouse, сегодня рассмотрим, ключевые факторы, которые особенно сильно влияют на скорость загрузки...

Как выполняется вставка данных в ClickHouse, от чего зависит ее скорость и каким образом ее повысить: последовательность операций загрузки и ее оптимизации. От чего зависит скорость вставки данных в ClickHouse Поскольку ClickHouse часто используется для построения хранилищ или витрин данных, скорость загрузки данных в эту базу очень важна. Хотя на...
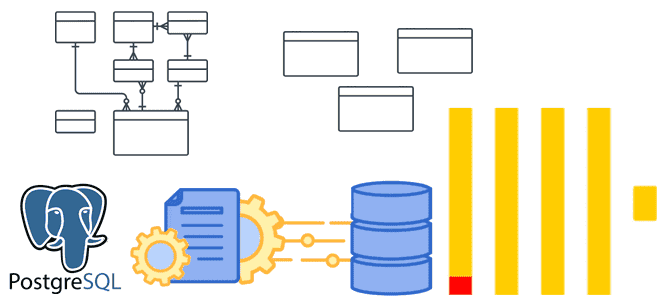
Денормализация таблиц, оптимизация SQL-запросов, словари вместо измерений и AggregatingMergeTree-движок с инкрементными матпредставлениями для приема измененных данных из PostgreSQL в ClickHouse. Оптимизация SQL-запросов Хотя передача изменений из PostgreSQL в ClickHouse может сопровождаться дублированием или потерями данных, эти проблемы решаемы, о чем мы рассказывали здесь и здесь. Однако, репликация данных из реляционной...
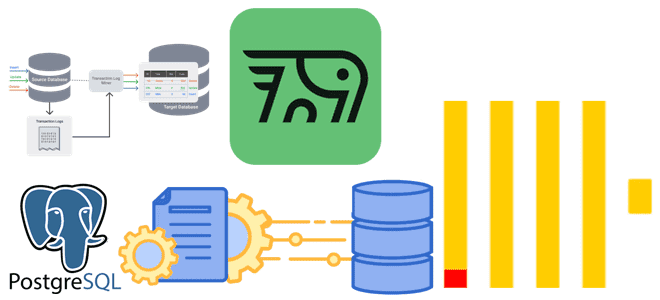
Почему ключи сортировки в ClickHouse могут стать причиной появления дублей или пропусков при CDC-передаче изменений из PostgreSQL и как этого избежать: особенности логической репликации из транзакционной базы данных в аналитическую. Влияние ключей сортировки на CDC-передачу изменений из PostgreSQL в ClickHouse Продолжая разбираться с дублированием данных при передачи изменений из PostgreSQL...
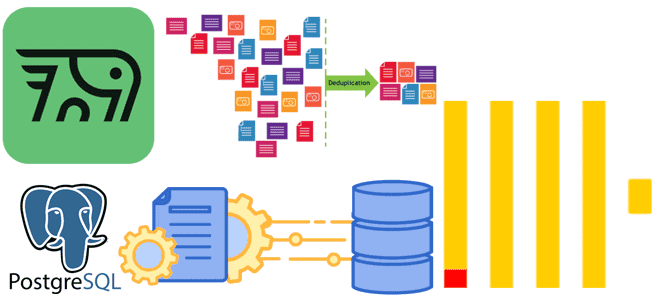
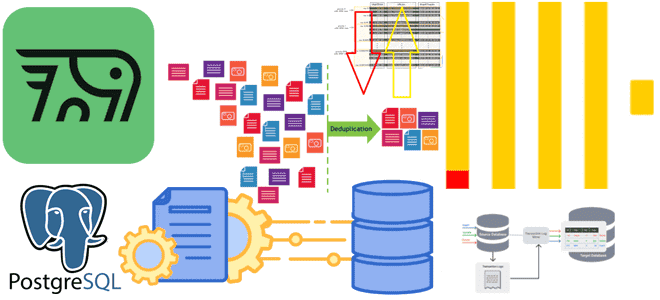
Почему табличный движок ReplacingMergeTree в PeerDB и ClickPipes не избавит от дублей при передаче измененных данных из PostgreSQL в ClickHouse и можно ли полностью выполнить дедупликацию с помощью модификатора FINAL, политики строк, обновляемых представлений или агрегатных и оконных функций. Как движок ReplacingMergeTree допускает дубли при импорте изменений из PostgreSQL в...
Как передать изменения данных из транзакционной базы в аналитическую без дублей и задержек: CDC-ETL из PostgreSQL в ClickHouse с PeerDB. CDC для ClickHouse с PeerDB и ClickPipes Возможности Clickhouse позволяют построить на нем корпоративное хранилище данных целиком или реализовать отдельный слой, например, для денормализованных витрин. Также совместное использование транзакционных и...
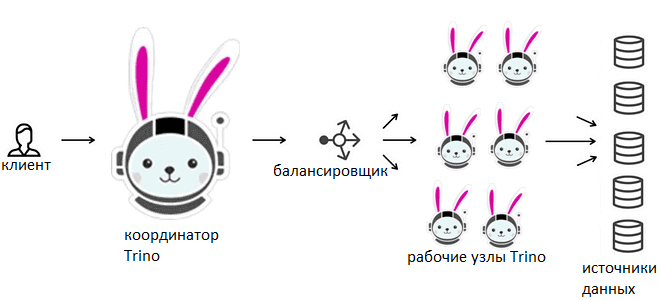
Как ускорить работу Trino при росте нагрузки и сэкономить на кластере при ее сокращении: автомасштабирование рабочих узлов и операций записи, а также настройка групп ресурсов. Масштабирование кластера Классическим способом справиться с растущими вычислительными нагрузками в гомогенной распределенной системе является горизонтальное масштабирование кластера. Это сводится к добавлению новых узлов, которые отвечают...
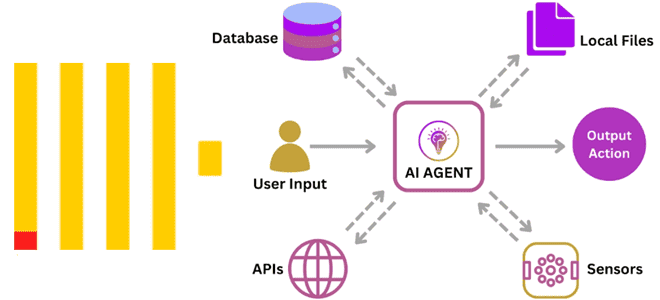
Зачем использовать ClickHouse для аналитики в реальном времени с агентами ИИ и как это сделать: современные вызовы внедрения LLM. Как реализовать ML-систему агентского ИИ с ClickHouse Продолжим разговор про агентский ИИ на основе LLM, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без прямого...

7 февраля 2025 года вышел очередной релиз ClickHouse. Знакомимся с его главными новинками: ускорение параллельного хэш-соединения, индексы MinMax на уровне таблицы, автоинкременты полей и улучшенное объединение таблиц с табличной функцией merge. Улучшение параллельного хэш-соединения в ClickHouse 25.1 В ClickHouse 25.1 добавлено 15 новых функций, 36 улучшений и 77 исправлений ошибок....

Особенности хранения и аналитической обработки JSON-документов в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL: объяснение бенчмаркингового теста. JSON в ClickHouse Недавно мы писали про бенчмаркинговое сравнение хранения и обработки JSON-данных в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL. В этом тесте, проведенном самими разработчиками ClickHouse, эта СУБД показала максимальную эффективность, которая обоснована...

Почему ClickHouse требует меньше места для хранения JSON-документов и быстрее выполняет аналитические запросы к ним по сравнению с MongoDB, Elasticsearch, DuckDB и PostgreSQL: бенчмаркинговый тест от разработчиков колоночной СУБД. Как Clickhouse делает быстрее агрегации в JSON-данных Хотя бенчмаркинговые тесты от вендоров редко бывают объективными, просматривать их довольно интересно. Недавно мне...