 972
972 
Содержание
Как не запутаться в многообразии коннекторов к Kafka, доступных во Flink Table API, и выбрать наиболее подходящий для своего сценария применения. Разница между Append Mode и Upsert-режимом коннектора Flink SQL к Kafka.
2 режима работы коннектора Kafka в Apache Flink
Apache Flink поставляется с универсальным соединителем Kafka, который поддерживает последнюю версию клиента этой распределенной платформы потоковой передачи событий. Если рассматривать связку Flink-Kafka с точки зрения слоев типичной информационной системы, в этом случае Flink-задание выступает приложением, реализующим бизнес-логику обработки данных, хранящихся в Apache Kafka.
DataStream API в Apache Flink предоставляет коннектор Kafka, который работает в режиме добавления, и может использоваться Flink-приложением, написанным на Scala/Java API. Также у Flink есть Table API, который предлагает два режима коннектора Kafka для приемника данных:
- Append — режим добавления;
- Upsert – режим вставки и обновления данных.
Append-режим означает, что потребители должны рассматривать все входные данные как добавления. Поэтому, чтобы получить самое последнее значение для каждого ключа, приложение-потребитель должно использовать логику дедупликации/группировки. Это может быть сделано внешней резидентной программой, которая выполнит это в памяти, или другим заданием Flink, группирующим записи по идентификатору и сортирующим их по времени происхождения события.
Это основное различие между двумя режимами потоковой передачи при работе с таблицей, поддерживаемой Kafka. Режим Upsert позволяет легко получить последние изменения, а также понять, являются ли потоковые данные новыми или их следует рассматривать как обновление или удаление. Удаление будет обнаружено, когда любое значение для определенного ключа равно NULL. Поэтому любая таблица, использующая Upsert-коннектор Kafka, должна иметь первичный ключ.
При использовании данных из таблицы «upsert-kafka» Flink вводит оператор ChangeLogNormalize, который агрегирует входные данные и возвращает последнюю запись для определенного первичного ключа. При чтении данных из таблицы, где коннектор Kafka работает в режиме добавления, Flink не внедряет оператор ChangelogNormalize в граф задания.
Два разных режима потоковой передачи имеют большое значение, когда несколько таблиц соединяются с использованием SQL-оператора JOIN. Разные механизмы работы Append- и Upsert-режимов могут привести к дублированию данных. Чтобы понять эту разницу, далее рассмотрим практический пример.
Практический пример работы коннектора Kafka во Flink SQL
Рассмотрим, как избежать дублирования данных при соединении двух таблиц Flink, поддерживаемых топиками Kafka. Например, в службе такси есть реестр автомобилей, каждый из которых имеет класс (Blue или Black). Именно класс автомобиля определяет его норму пробега. Вторая таблица содержит распределение автомобилей по районам города. По мере движения автомобиля генерируется событие назначения, которое передается в конвейер потоковой передачи, позволяя отслеживать изменение местоположения машины. С точки зрения бизнеса, надо ответить на вопрос, какие автомобили в настоящее время находятся в том или ином районе.
Создадим таблицу машин:
CREATE TABLE `cars` ( `carId` INT NOT NULL, `carClass` VARCHAR(50) )
И таблицу распределения машин по районам города:
CREATE TABLE `assignments` ( `carId` INT NOT NULL, `borough` VARCHAR(50)
Cформулируем SQL-запрос на соединение этих таблиц:
SELECT borough, carClass, collect(carId) AS carIds FROM ( SELECT c.carId, borough, carClass FROM cars c JOIN assignments a ON c.carId = a.carId ) GROUP BY borough, carClass;
Сперва посмотрим, как работает режим добавления в Flink SQL. При cоединении таблиц в режиме добавления можно получить дубликаты, если не выполнять операции дедупликации. Дубликаты возникают, когда автомобиль меняет свой район, т.е. один и тот же идентификатор автомобиля с течением времени может оказаться в другом районе.
Создадим таблицы приемников с режимом добавления, задав значение свойства connector равным kafka, что соответствует Append-mode:
CREATE TABLE cars ( carId INT NOT NULL, carClass VARCHAR(50) ) WITH ( 'connector' = 'kafka', 'key.format' = 'csv', 'key.fields' = 'carId', 'properties.group.id' = 'sample-group-cars', 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = '....kafka.svc.cluster.local:9092', 'topic' = 'cars', 'value.format' = 'csv' ); CREATE TABLE assignments ( carId INT NOT NULL, borough VARCHAR(50) ) WITH ( 'connector' = 'kafka', 'key.format' = 'csv', 'key.fields' = 'carId', 'properties.group.id' = 'sample-group', 'scan.startup.mode' = 'earliest-offset', 'properties.bootstrap.servers' = ....kafka.svc.cluster.local:9092', 'topic' = 'assignments', 'value.format' = 'csv' );
Определим SQL-скрипт для генерации данных и их сохранения в обеих таблицах:
CREATE TEMPORARY TABLE assignments_log (
carId INT NOT NULL,
borough VARCHAR(50)
) WITH (
'connector' = 'faker',
'rows-per-second' = '1',
'fields.carId.expression' = '#{number.numberBetween ''1'',''10''}',
'fields.borough.expression' = '#{regexify ''(Brooklyn|Queens|Staten Island|Manhattan|Bronx){1}''}'
);
BEGIN STATEMENT SET;
INSERT INTO cars VALUES
(1, 'Blue'), (2, 'Black'), (3, 'Premium'),
(4, 'Blue'), (5, 'Black'), (6, 'Premium'),
(7, 'Blue'), (8, 'Black'), (9, 'Premium');
INSERT INTO assignments SELECT * FROM assignments_log;
END;
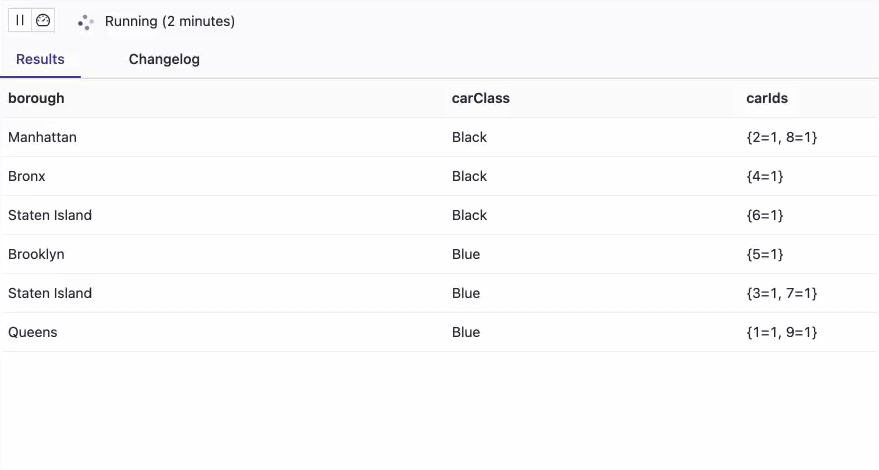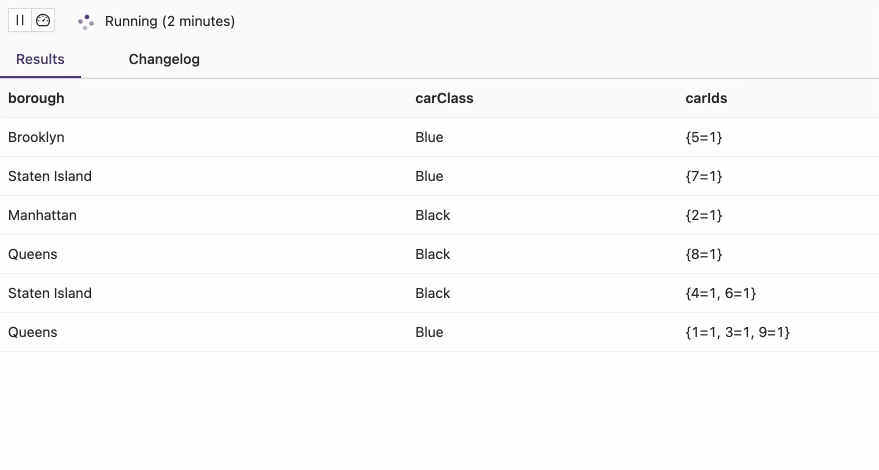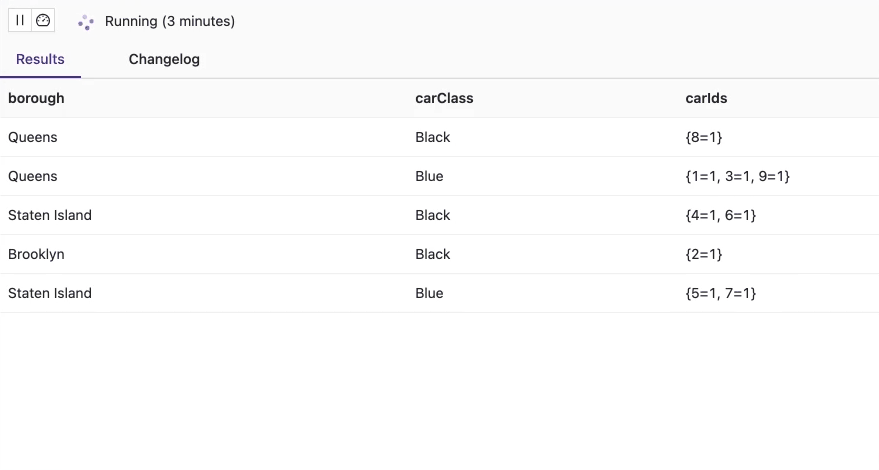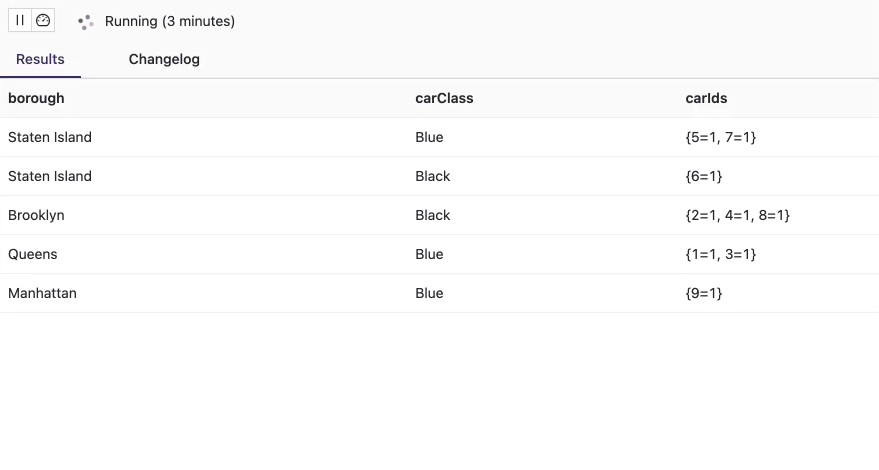
В результате выполнения этих запросов один и тот же автомобиль будет соответствовать нескольким районам, хотя должен быть назначен только одному району за раз.
Это произошло по причине того, что агрегирующая функция collect() возвращает мультимножество, содержащее пары ключ-значение. Каждый ключ является значением из соответствующего столбца таблицы (carId), а значение представляет собой количество вхождений для этого ключа. Мультимножество {1=27, 3=56} для района Staten Island означает, что автомобиль с id=1, назначается 27 раз, а автомобиль с id=3 назначается 56 раз в районе Staten Island . Получается, что одна и та же машина существует в 27 местах одновременно, что физически невозможно. Автомобили такси уникальны, у каждого из них есть свой уникальный идентификатор. Поэтому, чтобы понять, где находится конкретный автомобиль в текущий момент, надо дедуплицировать события назначения на основе атрибута времени, который следует добавить. Или использовать алгоритм дедупликации Flink, который мы разбирали здесь. Альтернативой такой ручной дедупликации является использование Upsert-режима коннектора к Kafka, куда непрерывно поступают новые события для их обработки Flink-приложением.
Чтобы создать входные таблицы с Upsert-режимом к Kafka, это следует указать в параметре коннектора:
CREATE TABLE assignments ( carId INT NOT NULL, borough VARCHAR(50), PRIMARY KEY (carId) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'key.format' = 'csv', 'properties.group.id' = 'sample-group', 'properties.bootstrap.servers' = '....kafka.svc.cluster.local:9092', 'topic' = 'assignments', 'value.format' = 'csv' ); CREATE TABLE cars ( carId INT NOT NULL, carClass VARCHAR(50), PRIMARY KEY (carId) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'key.format' = 'csv', 'properties.group.id' = 'sample-group-cars', 'properties.bootstrap.servers' = '....kafka.svc.cluster.local:9092', 'topic' = 'cars', 'value.format' = 'csv' );
После создания этих таблиц выполним SQL-запрос на их соединение, используя JOIN-оператор;
SELECT borough, carClass, collect(carId) AS carIds FROM ( SELECT c.carId, borough, carClass FROM cars c JOIN assignments a ON c.carId = a.carId ) GROUP BY borough, carClass;
Обе входные таблицы сначала нормализуются, прежде чем они соединятся JOIN-оператором. Поэтому в результате выполнения запроса не будет дублей, что соответствует рассматриваемому бизнес-контексту, т.к. нет автомобилей, которые существуют более чем в одном экземпляре в любом районе. Если данные во входные таблицы Flink SQL будут поступать из Kafka в потоковом режиме, то можно, например, каждую секунду получать события о перемещении машин по разным районам города. Значения в мультимножестве всегда равны 1, что является еще одним тестовым случаем, подтверждающим правильность запроса.
Таким образом, коннектор Kafka во Flink SQL может работать в двух режимах потоковой передачи. Режим Upsert позволяет автоматически получать последнее значение для определенного объекта без ручной дедупликации. Это пригодится при соединении двух таблиц, в одной из которых хранится история изменений для некоторого идентификатора объекта. Режим Upsert позволяет увидеть последнее значение этого объекта благодаря автоматической нормализации журнала изменений перед соединением таблиц. Благодаря этому можно в режиме реального времени легко отвечать на типичные бизнес-вопросы представления об общих ресурсах, включая автомобили, самолеты и пр. Режим добавления подойдет, если не нужно отфильтровывать все исторические события, а следует показать историю изменений в конце. В этом случае запрос будет выполняться быстрее в Append-режиме, поскольку Flink не нужно выполнять нормализацию журнала изменений.
Узнайте больше про применение Apache Flink и Kafka для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

