 1012
1012 
Что появилось нового в мажорном релизе самой популярной Python-библиотеки pandas, чем она похожа на Rust-пакет с Python API polars и в чем между ними разница: тестирование производительности и польза для дата-инженера.
Главные новинки pandas 2.0
3 апреля 2023 года вышел долгожданный релиз Python-библиотеки pandas, которая для многих дата-инженеров, аналитиков данных и специалистов по Data Science стала первым освоенным пакетом. Несмотря на широкую популярность этой библиотеки, использование pandas для работы с большими данными не считается хорошей практикой из-за высокого потребления памяти. Эту проблему разработчики библиотеки пытаются устранить в новой версии, добавив поддержку pyarrow в бэкэнд, чтобы использовать эффективный формат Apache Arrow для хранения датафреймов и рядов. Теперь при работе с файлами Parquet в pandas 2.0, по умолчанию будет использоваться pyarrow для обработки данных, что приводит к более быстрым и эффективным операциям с памятью благодаря колоночному формату памяти с параллельной обработкой.
Python c pandas 2.0 стал на шаг ближе к PySpark за счет поддержки отложенных вычислений и оптимизации копировании при записи. Теперь при создании копии объекта pandas, такого как DataFrame или Series, вместо немедленного копирования создается ссылка на исходные данные, а генерация нового объекта откладывается до тех пор, пока данные не будут изменены. Это означает, что при наличии нескольких неизменных копий одних и тех же данных, все они будут ссылаться на одну и ту же память. Такой прием позволяет значительно сократить использование памяти и повысить производительность, что пригодится при работе с большими наборами данных. Подробнее о возможностях и опасностях использования API PAndas в Apache Spark читайте в нашей новой статье.
Индексы в pandas 2.0 теперь могут содержать числовые типы NumPy, включая int8, int16, int32, int64, uint8, uint16, uint32, uint64, float32 и float64. Ранее поддерживались только типы int64, uint64 и float64. Это изменение дает более быстрый доступ и ускоряет вычисления. Кроме того, операции, которые ранее создавали 64-разрядные индексы, теперь могут создавать индексы с более низкими разрядами, например 32-разрядные.
Что такое polars: краткий обзор Python-библиотеки
Хотя фактически библиотека polars появилась несколько лет назад, в 2020 году, она все еще находится в зоне активного развития интереса любителей и профессионалов к этому пакету. Справедливости ради стоит отметить, что называть polars библиотекой Python не совсем корректно. Ядро этой высокопроизводительной библиотеки для управления структурированными данными написано на Rust, а сама она предоставляет API Python, Rust и NodeJS. Способность Rust немедленно компилироваться в машинный код без использования интерпретатора делает его быстрее классического Python, на котором работает pandas. Благодаря наличию Python API polars можно использовать как библиотеку Python с простым и понятным интерфейсом, используя преимущества производительности Rust.
Высокая эффективность работы polars также обеспечивается отсутствием внешних зависимостей, поддержкой всех уровней хранения данных (локально, в облаке или базе), встроенным оптимизатором запросов. Polars поддерживает преобразование данных вне ядра с помощью своего потокового API, который не требует, чтобы все данные находились в памяти одновременно. При этом библиотека полностью использует мощность компьютера, распределяя рабочую нагрузку между доступными ядрами ЦП без какой-либо дополнительной настройки. Пакет использует SIMD для оптимизации использования ЦП, механизм векторизованных запросов и колоночный формат данных Apache Arrow, о котором мы писали здесь.
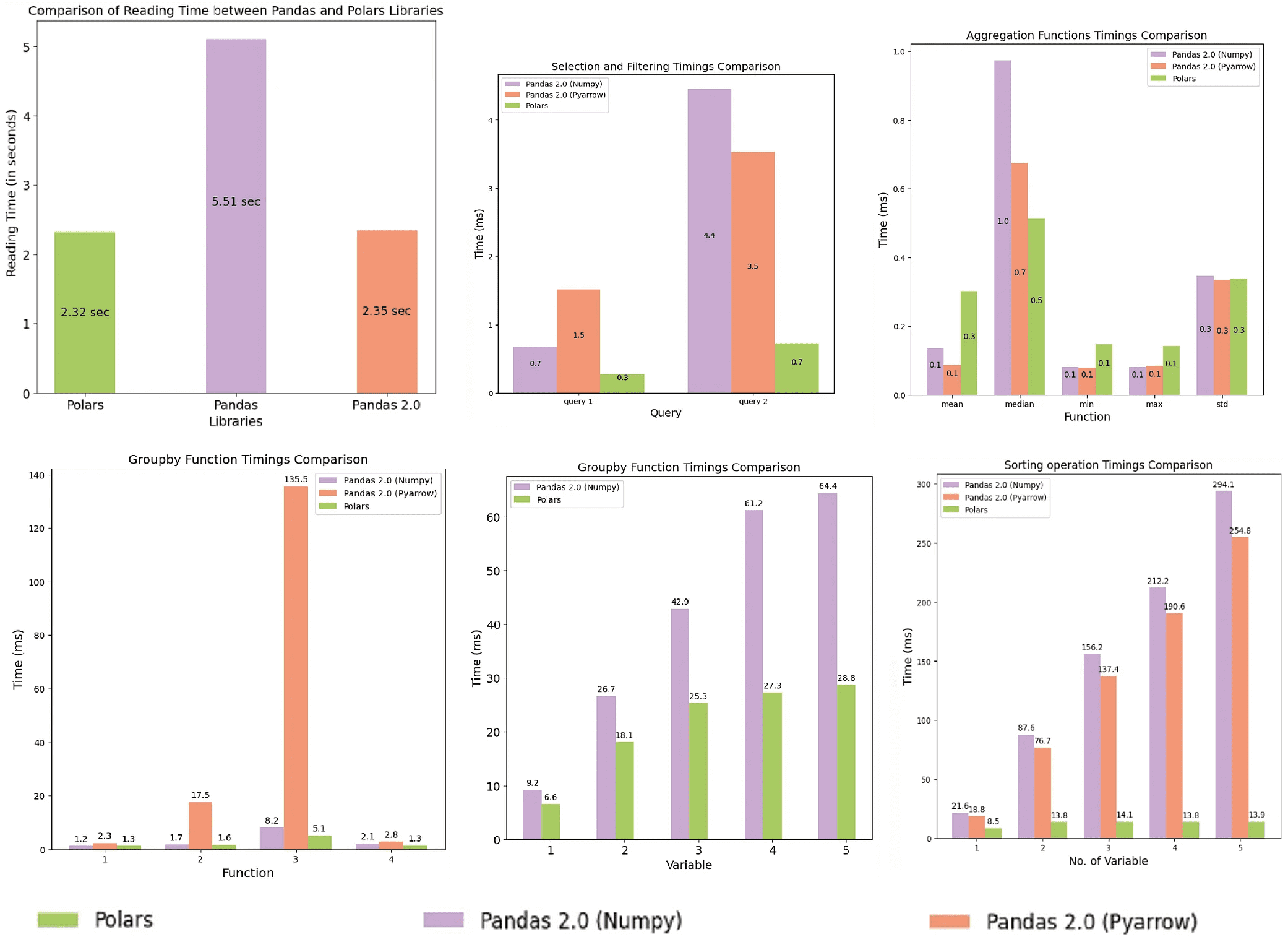
Polars поддерживает два API: отложенные вычисления и активную оценку, когда запрос выполняется немедленно. Polars отлично подходит для работы с большими объемами данных и является самой быстрой библиотекой для сложных случаев, таких как сортировка и группировка. Хотя Pandas более привлекателен синтаксически, polars имеет лучшую пропускную способность при работе с большими датафреймами, что может быть очень существенным критерием выбора инструмента для дата-инженера. В частности, при подготовке данных к интеллектуальному анализу и ML-моделированию, их необходимо очистить, нормализовать и выполнить прочие преобразования. Если объем данных большой, polars справится с этим быстрее pandas, даже если брать в расчет версию 2.0. Эти выводы подтверждаются бенчмаркинговым сравнением, проведенным энтузиастами в начале апреля 2023 года.
Для тестирования производительности библиотек использовался синтетический набор данных из 30 миллионов строк и 15 столбцов, который состоит из 8 категориальных и 7 числовых признаков. Тесты проводились на 4-ядерных процессорах и 32 ГБ ОЗУ.
Узнайте больше про использование Python для задач дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

