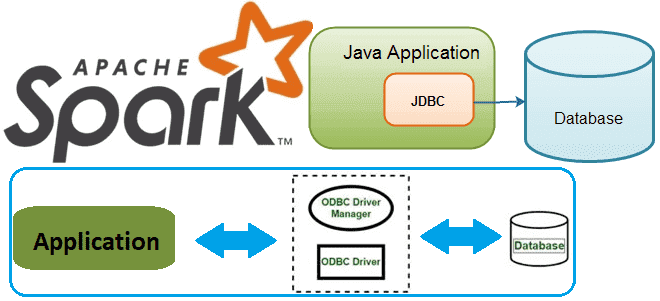
В этой статье для разработчиков распределенных приложений и дата-инженеров разберем, как Spark-задание может подключиться к базе данных через JDBC и ODBC драйверы. В качестве примера рассмотрим код на PySpark и Python-библиотеки pyodbc, а также JDBC-коннекторы в Spark SQL. Доступ к БД из кластера Spark с ODBC-драйвером Напомним, получить соединение с...

Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое Nebula Graph и как использовать мощные возможности обработки графов этой NoSQL-СУБД в сочетании с Apache Spark, одним из самых популярных механизмов анализа данных. Что такое Nebula Graph и как это работает Nebula Graph — это...

Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и...

Постоянно добавляя в наши курсы для дата-инженеров и разработчиков распределенных Spark-приложений интересные примеры, сегодня мы хотим поделиться с вами простыми, но эффективными приемами, как улучшить производительность этого вычислительного движка. Чем метод take() лучше collect() в Apache Spark, какие открытые инструменты помогут выполнить профилирование кода и как быстро прочитать множество маленьких...
Чтобы добавить в наши курсы для дата-инженеров и разработчиков распределенных приложений еще больше практических примеров, сегодня рассмотрим, как написать Python-код для вычисления задержки потребителя Apache Kafka, расширив типовой слушатель StreamingQueryListener, который есть в Java и Scala API библиотеки Spark Structured Streaming, но недоступен в PySpark. Проблема отставания потребителя Apache Kafka...

Как Cluster Autotuner от Sync для автонастройки кластера Spark в AWS EMR помог edtech-компании Duolingo снизить затраты на 55%. Полезный сервис для дата-инженера и администратора кластера, чтобы устранить неэффективную ручную настройку, обеспечив оптимальную стоимость, производительность и надежность распределенных вычислений без изменения кода. Дорогой Apache Spark на AWS EMR Duolingo –...

Постоянно добавляя в наши курсы по Apache Spark полезные материалы, сегодня мы рассмотрим, что происходит под капотом этого вычислительного движка, чтобы помочь разработчикам распределенных приложений и дата-инженерам повысить его эффективность. Тонкости сериализации данных, компиляции SQL-запросов в JavaBytecode и сборка мусора. 2 библиотеки сериализации данных в Apache Spark В распределенных системах...

28 июня 2022 года в сотрудничестве с сообществом разработчиков Apache Spark компания Databricks анонсировала проект Lightspeed, новое поколение этого потокового движка. Читайте далее, что это такое и чем оно отличается от классического Apache Spark Structured Streaming. Потоковая обработка данных с Apache Spark Structured Streaming Потоковая передача событий весьма востребована современным...

Сегодня разберемся, когда для Data Science-проектов вместо Apache Spark, самого популярного вычислительного движка аналитики больших данных, стоить выбрать Dask – легковесную Python-библиотеку для параллельных вычислений. И, наоборот, в каких случаях инженер данных и Data Scientist получают преимущества, выбирая Spark. Что такое Dask и зачем он нужен Data Scientist’у Прежде чем...
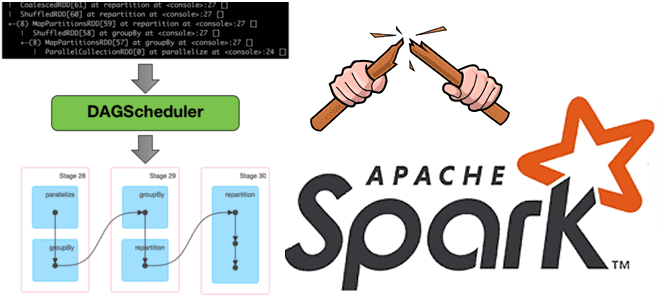
Недавно мы говорили про трудности наблюдаемости данных вообще и возможности мониторинга их происхождения в Apache Spark. Сегодня рассмотрим, зачем дата-инженеру прерывать DAG lineage в Spark-приложениях и как это сделать. Что такое DAG lineage и зачем его прерывать? Напомним, Apache Spark использует концепция DAG для выполнения распределенных вычислений. Направленный ациклический граф...

16 июня 2022 года вышла новая версия Apache Spark – 3.3.0. Разбираем главные фичи этого минорного релиза, особенно важные для дата-инженера и разработчика распределенных приложений: от расширения поддержки ANSI SQL до профилирования UDF на Python. Главные изменения Apache Spark 3.3.0 Apache Spark 3.3.0 — это четвертый релиз линейки 3.x, в...
Вчера мы рассказывали, почему важна наблюдаемость данных какие платформы помогают комплексно обеспечить все ее аспекты. В продолжение этой темы сегодня заглянем под капот происхождения данных в Apache Spark с помощью агента Spline и других способов. Трудности data lineage в Apache Spark Когда конвейер данных выходит из строя, дата-инженеру нужно скорее...

Что такое SparkListener, какие встроенные слушатели бывают в Apache Spark, как написать собственный перехватчик событий и зачем это нужно разработчику распределенного приложения. Также рассмотрим, как реализовать свой слушатель для приложения на PySpark и зачем включать уровень логирования INFO для SparkContext. Что такое слушатель Spark Apache Spark позволяет быстро обрабатывать большие...

Сколько ядер ЦП выделить на каждый исполнитель и каково оптимальное количество памяти для Spark-приложения при статическом и динамическом выделении ресурсов. Важные вопросы эффективной утилизации кластера, с которыми сталкивается каждый дата-инженер и разработчик распределенных программ. Запуск распределенного приложения через spark-submit Повысить эффективность работы приложения Apache Spark можно не только через оптимизацию...

Что такое Tungsten, зачем он нужен в Apache Spark и как этот проект устраняет узкие места вычислительного движка, чтобы повысить его производительность и эффективность утилизации ресурсов за счет приближения JVM к bare metal. Рассматриваем самые важные для разработчика распределенных приложений особенности и разбираемся, при чем здесь вольфрам и почему с...

Специально для обучения начинающих аналитиков данных и дата-инженеров сегодня рассмотрим примеры выполнения простых SQL-запросов и оконных функций в Apache Spark на Google Colab. Как быстро проанализировать датафрейм из CSV-файлов с помощью нескольких строк на PySpark. Запуск и использование PySpark в Google Colab Предположим, необходимо определить потенциальный доход от проведения обучающих...

В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi. Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт)....
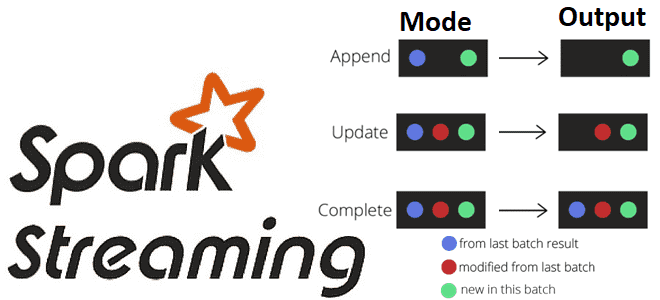
Какие бывают режимы вывода в структурированной потоковой передаче Spark, чем они отличаются и как их использовать на практике: разбираемся на практическом примере. Краткий ликбез по output modes в Apache Spark Structured Streaming для обучения дата-инженеров и разработчиков распределенных приложений. Что такое режимы вывода в Apache Spark Structured Streaming Apache Spark...
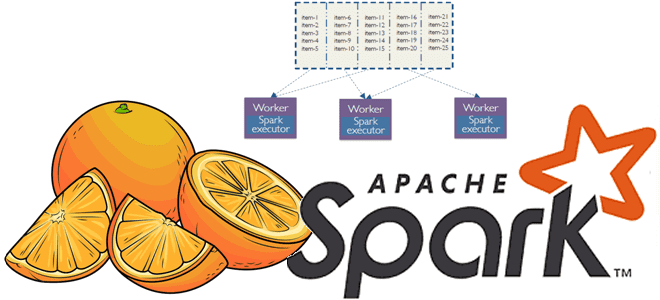
Мы уже рассказывали про функции перераспределения данных по разделам coalesce() и repartition(). Сегодня сравним их работу с еще одним методом управления разделами в Apache Spark и разберем, как все они могут помочь дата-инженеру и разработчику распределенных приложений повысить эффективность этого популярного фреймворка аналитики больших данных. Отобрать и поделить: лучшие практики партиционирования данных...

Как настроить Apache Spark 3.0.1 и Hive 3.1.2 на Hadoop 3.3.0: тонкости установки и конфигурирования для обучения администраторов кластера и инженеров с примерами команд и кода распределенных приложений. Запуск Spark-приложения на Hadoop-кластере Прежде всего, для настройки кластера Apache Spark нужен работающий кластер Hadoop. Сама установка и настройка выполняется в 2...