
Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм,...

Flink часто сравнивают с Apache Spark, другим популярным инструментом потоковой обработки данных. Оба этих распределенных отказоустойчивых фреймворка с открытым исходным кодом используются в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop [1] и других кластерных системах. В этой статье мы поговорим, чем похожи и чем отличаются Флинк и Спарк, а...

Проанализировав сходства и различия Apache Kafka Streams и Spark Streaming, можно сделать некоторые выводы относительно выбора того или иного решения в качестве основного инструмента потоковой обработки Big Data. В этой статье мы собрали для вас аргументы в пользу Кафка Стримс и Спарк Стриминг в конкретных ситуациях, а также нашли некоторые...

Сегодня мы рассмотрим популярные Big Data инструменты обработки потоковых данных: Apache Kafka Streams и Spark Streaming: чем они похожи и чем отличаются. Стоит сказать, что Спарк Стриминг и Кафка Стримс – возможно, наиболее популярные, но не единственные средства обработки информационных потоков Big Data. Для этой цели существует еще множество альтернатив,...
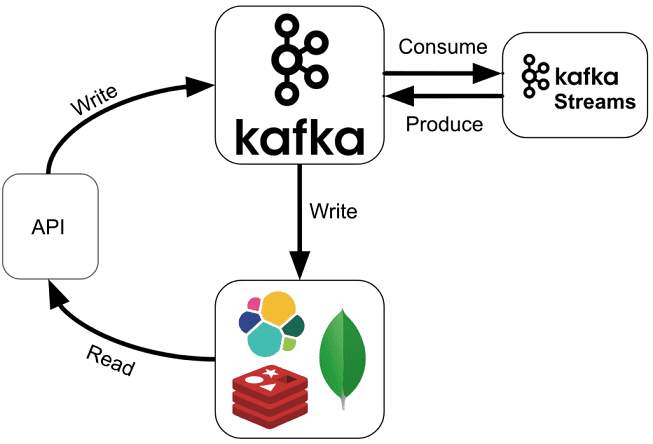
Продолжая разговор про Apache Kafka Streams, сегодня мы расскажем, как API этой мощной библиотеки упрощает жизнь DevOps-инженеру и разработчику Big Data систем. Читайте в нашей статье, как Kafka Streams API эффективно обрабатывать большие данные из топиков Кафка на лету без использования Apache Spark, а также быстро создавать и развертывать распределенные...

Мы уже рассказывали, как машинное обучение (Machine Learning) и большие данные (Big Data) помогают бизнесу сделать свои маркетинговые кампании персональными и оптимизировать рекламный бюджет. В этой статье рассмотрим, как метеоусловия влияют на маркетинг и каким образом бизнес может заработать на использовании данных об этих внешних условиях. Как погода влияет на...

Продолжая разговор про форматы Big Data файлов, сегодня мы рассмотрим разницу между линейными и колоночными типами, а также расскажем о том, как выбирать между AVRO, Sequence, Parquet, ORC и RCFile при работе с Apache Hadoop, Kafka, Spark, Flume, Hive, Drill, Druid и других средствах работы с большими данными. Итак, форматы...

Мы уже упоминали формат Parquet в статье про Apache Avro, одну из наиболее распространенных схем данных Big Data, часто используемую в Kafka, Spark и Hadoop. Сегодня рассмотрим более подробно, чем именно хорошо Apache Parquet и как он отличается от других форматов Big Data. Что такое Apache Parquet и как он...

Мы уже рассказывали, зачем нужна интеграция Apache Kafka и Spark Streaming. Сегодня рассмотрим, как технически организовать такой Big Data конвейер по непрерывной обработке потоковых данных в режиме реального времени. Способы интеграции Наладить двустороннюю связь между Apache Kafka и Spark Streaming возможны следующими 2-мя способами: получение сообщений через службу синхронизации Zookeeper...
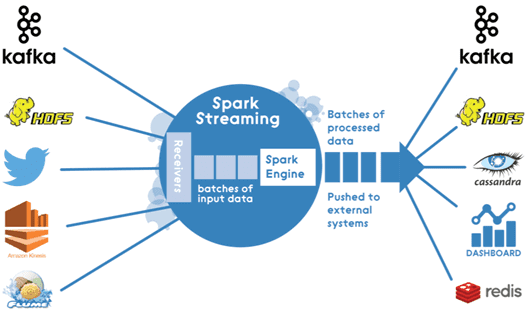
В этой статье мы рассмотрим архитектуру Big Data конвейера по непрерывной обработке потоковых данных в режиме реального времени на примере интеграции Apache Kafka и Spark Streaming. Что такое Spark Streaming и для чего он нужен Spark Streaming – это надстройка фреймворка с открытым исходным кодом Apache Spark для обработки потоковых...
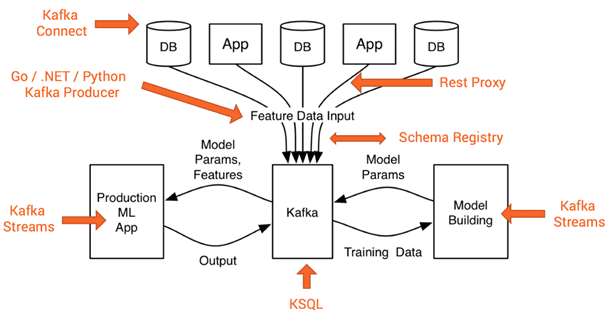
Рассмотрев основы Apache Kafka, сегодня мы расскажем о месте этого распределённого брокера сообщений в архитектуре Big Data систем. Читайте в нашей статье, какие компоненты Кафка обеспечивают ее использование в программных продуктах машинного обучения (Machine Learning, ML), интернете вещей (Internet Of Things, IoT), системах бизнес-аналитики (Business Intelligence, BI), а также других...

Сегодня мы поговорим о заблуждениях насчет базового инфраструктурного понятия хранения и обработки больших данных – экосистеме Hadoop и развеем 3 самых популярных мифа об этой технологии. А также рассмотрим применение Cloudera, Hortonworks, Arenadata, MapR и HDInsight для проектов Big Data и машинного обучения (Machine Learning). Миф №1: Hadoop – это...
В прошлом месяце Apache Spark выпустили свою последнюю новую версию Apache Spark 2.4.0. Это пятая версия в серии 2.x. В новой версии Apache Spark появляется метод Барьерной синхронизации для лучшей интеграции с системами глубокого обучения. Apache Spark 2.4.0 содержит более 30 встроенных функций и функций более высокого порядка для работы...