
Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...

В июле 2021 года «Аренадата Софтвер», российская ИТ-компания разработчик отечественных решений для хранения и аналитики больших данных, представила минорный релиз корпоративного дистрибутива на базе Apache Hadoop — Arenadata Hadoop 2.1.4. Главными фишками этого выпуска стало наличие 3-й версии Apache Spark и External PostgreSQL для Hive MetaStore. Сегодня рассмотрим, что именно...

Сегодня в рамках обучения разработчиков Apache Spark и дата-аналитиков, поговорим про детерминированность UDF-функций и особенности их обработки оптимизатором SQL-запросов Catalyst. На практических примерах рассмотрим, как оптимизатор Spark SQL обрабатывает недетерминированные выражения и зачем кэшировать промежуточные результаты, чтобы гарантированно получить корректный выход. Еще раз про детерминированность функций и планы выполнения...

Мы уже рассказывали про коннектор Greenplum-Spark, 2-я версия которого вышла в октябре 2020 года. А сегодня рассмотрим российскую альтернативу для отечественной MPP-СУБД Arenadata DB на базе Greenplum, выпущенную компанией Аренадата в июле 2021 года. Краткий обзор ADB-Spark Connector: архитектура, принципы работы, сценарии использования, а также отличия от PXF-фреймворка и варианта...

Вчера мы упоминали, что использование Spark или Tez в качестве движка исполнения SQL-запросов в Apache Hive вместо классического Hadoop MapReduce намного ускоряет аналитику больших данных. Сегодня рассмотрим подробнее, чем отличаются эти механизмы и какой из них выбирать в разных случаях использования. Что такое Apache Tez и как он работает с...

Чтобы добавить в наши курсы по Spark еще больше практических кейсов, сегодня ответим на самые частые вопросы относительно масштабирования распределенных приложений, написанных с помощью этого фреймворка. Читайте далее о пользе динамического распределения, оптимальном выделении ресурсов на драйверы и исполнители, а также каковы тонкости управления разделами в Apache Spark. Лебедь, рак...

Обучая разработчиков Big Data, сегодня рассмотрим, почему в распределенных приложениях Apache Spark случаются OOM-ошибки. Читайте далее, как работает сборка мусора JVM в Spark-приложениях, почему из-за нее случаются утечки памяти и что можно сделать на уровне драйвера и исполнителя для предупреждения OutOfMemoryError. Сборка мусора JVM и OOM-ошибки в Spark-приложениях На практике...

В этой статье по обучению Apache Spark рассмотрим, чем графический веб-интерфейс этого фреймворка полезен разработчику распределенных приложений. Читайте далее, где посмотреть кэшированные данные, визуализацию DAG, переменные среды, исполняемые SQL-запросы, а также прочие важные метрики кластерных вычислений и аналитики больших данных. 9 страниц Apache Spark UI Apache Spark предоставляет набор пользовательских...
Продвигая наши курсы по Apache Spark для разработчиков, сегодня рассмотрим пользовательские функции и особенности работы с ними в API SQL-модуле этого фреймворка. Читайте далее про идемпотентность UDF-функций и их влияние на распределение данных в кластере Apache Spark. Как устроены UDF в Apache Spark: краткий ликбез Пользовательские функции (User Defined Functions,...
В рамках обучения разработчиков Apache Spark, сегодня рассмотрим еще несколько интересных особенностей этого фреймворка, ограничивающих его типовые возможности и на PySpark-примерах разберем, как с этим бороться. Читайте далее, что такое оконные функции и зачем они нужны, как сортировка влияет на фрейм окна в Spark SQL и чем опасны действия над...
Чтобы сделать наши курсы по Apache Spark еще более полезными, мы рассказываем о неочевидных тонкостях этого фреймворка, знание которых позволит разработчику распределенных приложений использовать возможности этой технологии более эффективно. Сегодня на практических примерах PySpark в API DataFrame рассмотрим разницу между функциями сортировки массивов и особенности объединения контенкации, а также разберемся...
Продолжая разговор про вычислительные операции над датафреймами в Apache Spark, сегодня рассмотрим, какие преобразования (transformations) и действия (actions) чаще всего используются при разработке распределенных приложений и аналитике больших данных. Читайте далее, про виды столбцовых преобразования и отличия действия collect() от take(). Преобразования в Apache Spark: виды и особенности реализации Напомним,...
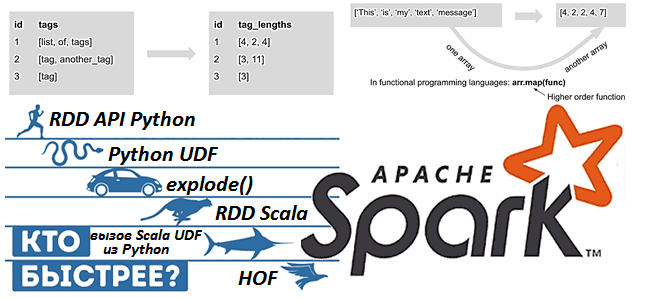
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...

Apache Spark + AirFlow – известная каждому дата-инженеру комбинация технологий Big Data для запуска сложных конвейеров обработки данных. Но совместное использование этих фреймворков ограничено недостатками AirFlow, часть из которых можно обойти с помощью Apache Livy. Однако эксплуатация AirFlow менее удобна, чем Dagster. Поэтому сегодня рассмотрим, как этот альтернативный оркестратор данных...
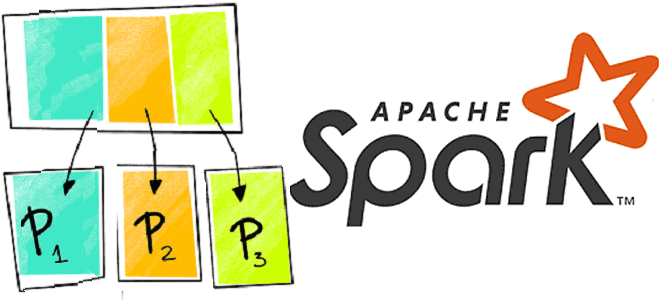
Чтобы сделать обучение разработчиков Apache Spark, дата-аналитиков и инженеров Big Data еще более наглядным, сегодня рассмотрим проблему JOIN-соединений при неравномерном распределении данных по узлам кластера и способы ее решения. Читайте далее, как избавиться от перекосов и ускорить выполнение SQL-запросов в Spark-приложениях. Перекосы данных в Apache Spark: что это и чем...

Продолжая добавлять в наши практические курсы по Apache Kafka и Spark еще больше интересных примеров, сегодня рассмотрим, как с помощью этих технологий Big Data анализировать метаданные сетевых потоков в реальном времени. В этой статье мы приготовили для вас кейс по потоковой аналитики больших данных о сетевом трафике с помощью Apache...
Сегодня поговорим про обработку геопространственных данных с Apache Spark и рассмотрим, что такое Apache Sedona, как этот фреймворк связан с GeoSpark, какие форматы и структуры данных он поддерживает. Читайте далее про пространственные RDD, Spatial SQL-запросы и построение конвейеров обработки геоданных в облачных сервисах Amazon. Как обработать геопространственные данные в...

Сегодня рассмотрим инструмент, который облегчает практическое использование Apache Spark, позволяя дата-аналитику и разработчику распределенных приложений быстро писать и выполнять SQL-запросы в рамках удобного веб-редактора. Читайте далее, что такое Hue, как он связан со Spark SQL и Hive, а также причем здесь Livy. Что Hue и при чем здесь Apache Livy...
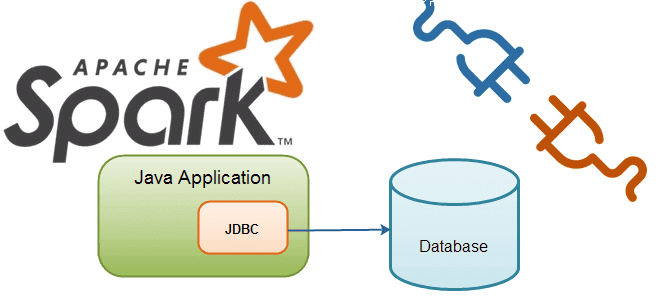
В этой статье рассмотрим особенности подключения Apache Spark к внешним СУБД как к источникам данных для аналитики Big Data средствами SQL-модуля этого фреймворка. Читайте далее о том, что такое JDBC-драйвер, чем источник данных JDBC отличается от сервера Spark SQL JDBC, при чем здесь RPC-фреймворк и язык описания интерфейсов Thrift, а...