
В уроке 13 мы разбирались с kafka-metadata-shell.sh - интерактивным шеллом для чтения содержимого KRaft-метаданных. Если вы там заходили в директорию /features/ и видели там metadata.version с каким-то числом - это как раз то, чем управляет утилита сегодняшнего урока. kafka-features.sh отвечает за управление feature-флагами кластера. Звучит абстрактно, но на практике...

В уроке 12 мы разобрали kafka-metadata-quorum.sh - как смотреть состояние кворума KRaft, кто сейчас лидер контроллера и насколько отстают фолловеры. Это взгляд на кворум снаружи: числа, статусы, смещения. Но иногда нужно заглянуть внутрь - буквально открыть метаданные кластера и посмотреть, что там хранится. Для этого в Apache Kafka есть...

В уроке 11 мы разобрали kafka-cluster.sh - как получить cluster ID от работающего брокера и как корректно вывести брокер из KRaft-кластера через команду unregister. После вывода брокера логично проверить, что кворум не пострадал и кластер продолжает работать нормально. Именно для этого существует утилита следующего урока. kafka-metadata-quorum.sh - инструмент для...

В уроке 10 мы разобрали kafka-storage.sh - утилиту, которая работает с хранилищем метаданных напрямую через файловую систему. Она генерирует cluster ID, форматирует директорию и записывает meta.properties. Но всё это происходит в оффлайне - до старта брокера. Теперь представьте обратную ситуацию: кластер уже запущен и работает, и вам нужно узнать его...

В уроке 9 мы разобрали kafka-server-start.sh и kafka-server-stop.sh - как запускать брокер в foreground и daemon-режиме, какие переменные окружения влияют на JVM и как правильно останавливать процесс без потери данных. Но прежде чем брокер вообще сможет стартовать в KRaft-режиме, нужно сделать один обязательный шаг - отформатировать хранилище метаданных. Этот...
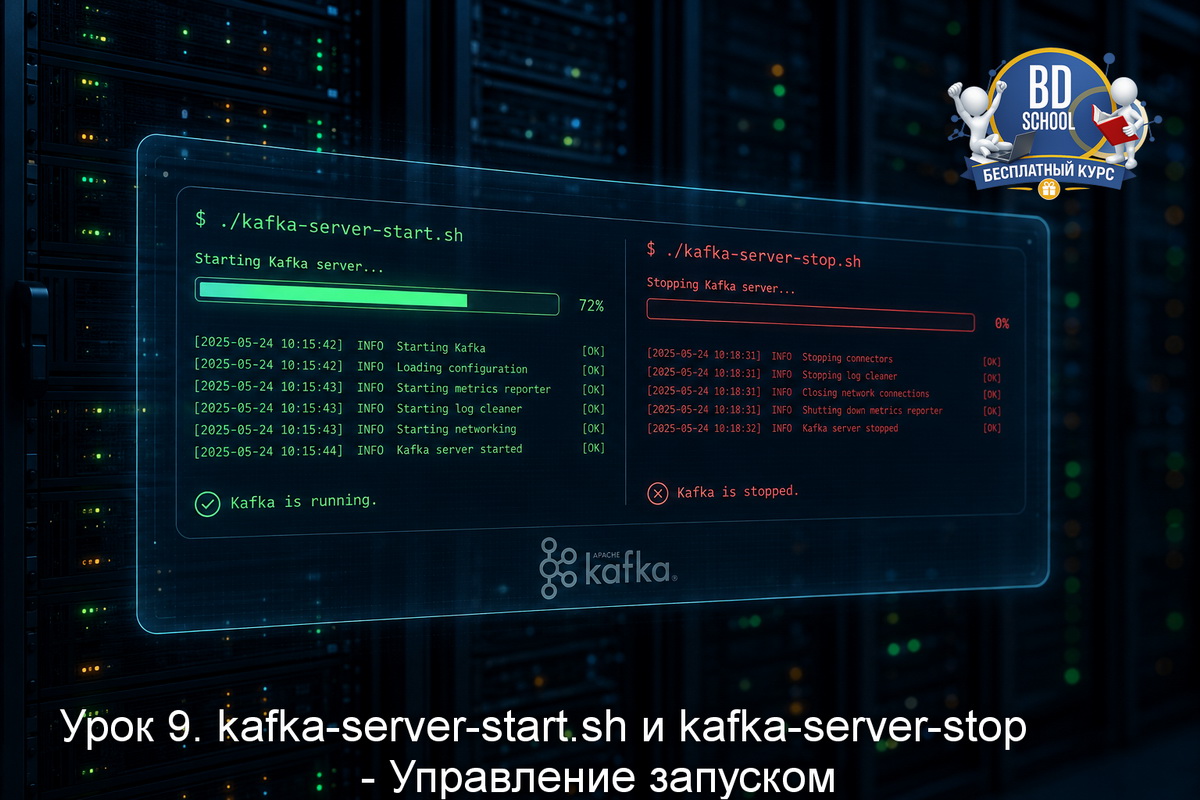
В уроке 8 мы разобрали kafka-console-consumer.sh - как читать сообщения из топика, управлять смещениями и фильтровать данные по партициям. Теперь сделаем шаг назад и посмотрим на кое-что фундаментальное: как именно запускается и останавливается сам брокер Kafka. Казалось бы, вопрос очевидный - мы уже запускали Kafka в уроках 2-4. Но...

В прошлом уроке мы научились отправлять сообщения через kafka-console-producer.sh: вводить строки вручную, работать с ключами и загружать данные из файла. Теперь нужно научиться их читать. За это отвечает kafka-console-consumer.sh - стандартная утилита для чтения сообщений из топика прямо в терминале. Это инструмент из той же категории «быстро проверить»: подключился,...

В предыдущем уроке мы научились работать с топиками через kafka-topics.sh: создавали, описывали, меняли настройки и удаляли. Теперь у нас есть готовый топик, и логичный следующий вопрос - как туда что-нибудь положить. Именно этим занимается kafka-console-producer.sh. Это утилита для ручной отправки сообщений в топик прямо из терминала. Незаменима для быстрых...

Изучаем Apache Kafka с нуля. Урок 6. kafka-topics.sh - Управление топиками ПО: Apache Kafka 4.2.0, KRaft-режим | Окружение: Ubuntu 22.04 LTS / macOS 14+ | Уровень: начинающий+ В прошлом уроке мы разобрались с переменными окружения, алиасами и базовой структурой каталога $KAFKA_HOME/bin/. Теперь умеем запускать утилиты из любой директории и понимаем...
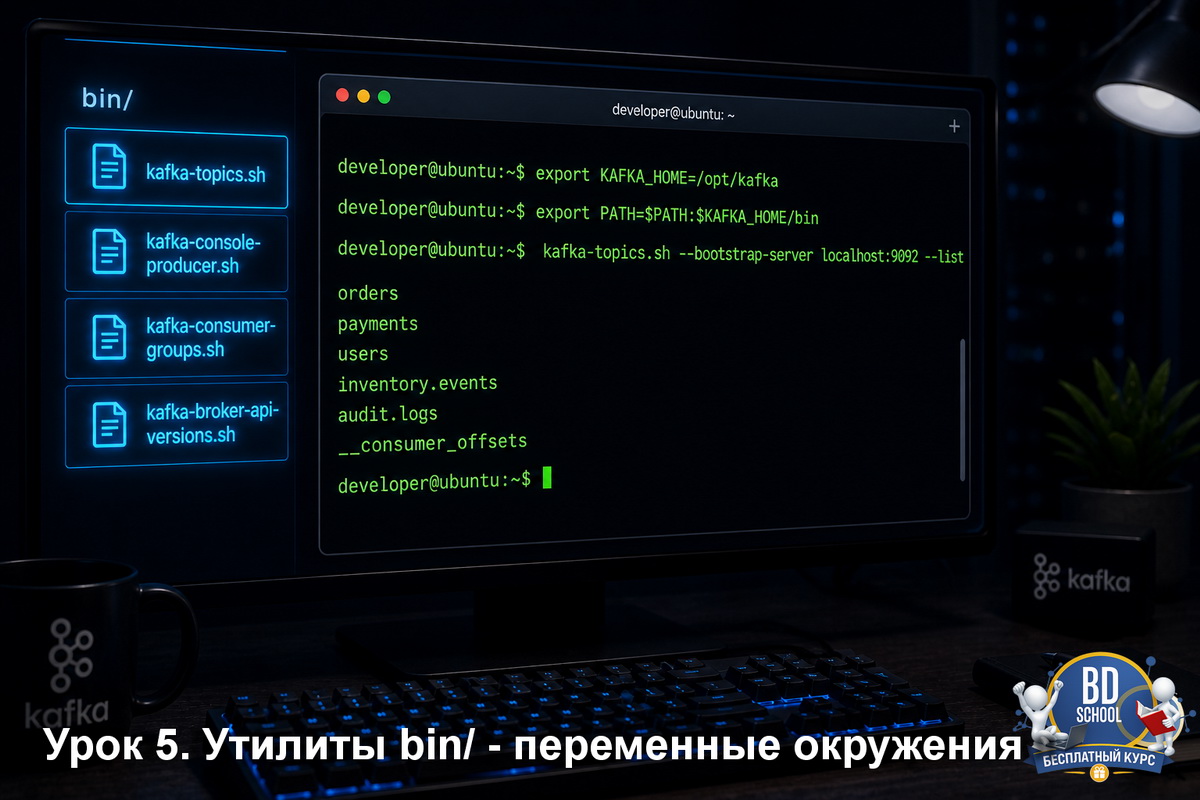
Изучаем Apache Kafka с нуля. Урок 5. Утилиты Kafka bin/ - переменные окружения и основы ПО: Apache Kafka 4.2.0 | Окружение: Ubuntu 22.04 LTS, Java 17 | Уровень: начинающий В четвёртом уроке мы собрали трёхнодовый Kafka-кластер в Docker Compose. Для проверки его работы запускали команды через docker exec и прописывали...

Изучаем Apache Kafka с нуля. Урок 4. Kafka Docker KRaft 3х узловый кластер ПО: Apache Kafka 4.2.0 (образ apache/kafka:4.2.0) | Docker: Engine 28.1, Compose v2.35 | Окружение: Ubuntu 22.04 LTS / macOS 14+ | Уровень: начинающий+ В прошлом уроке мы подняли один брокер Kafka в Docker за несколько...

Изучаем Apache Kafka с нуля. Урок 3. Kafka Docker KRaft. Однонодовый кластер ПО: Apache Kafka 4.2.0 (образ apache/kafka:4.2.0) Docker: Engine 28.1, Compose v2.35 \ Окружение: Ubuntu 22.04 LTS / macOS 14+ Уровень: начинающий В прошлом уроке мы установили Apache Kafka 4.2.0 вручную прямо на хост. Получилось рабочее окружение, но...

Изучаем Apache Kafka с нуля. Урок 2. Установка Apache Kafka в режиме KRaft ПО: Apache Kafka 4.2.0 Окружение: Ubuntu 22.04 LTS, Java 17 Уровень: начинающий В первом уроке мы установили Apache Kafka 3.9.0 в связке с ZooKeeper. Это был классический способ развернуть кластер - тот, которым пользовались годами. Но...

Изучаем Apache Kafka с нуля. Урок 1. Установка с Zookeeper Версии: Apache Kafka 3.9.0, Apache ZooKeeper (встроен в дистрибутив) Окружение: Ubuntu 24.04 LTS, Java 17 Сложность: начальный уровень Кто мы и зачем этот курс Мы - команда bigdataschool.ru. Уже несколько лет мы обучаем инженеров и аналитиков работе с большими данными:...

Представьте, что вы работаете в e-commerce. У вас есть 50 таблиц в Postgres (заказы, товары, пользователи, отзывы...), и каждую из них нужно переливать в ClickHouse по одной и той же схеме: Скачать -> Очистить -> Загрузить. Новичок создаст 50 файлов: dag_orders.py, dag_users.py, dag_items.py... В каждом файле будет одинаковый код,...

Если Postgres - это надежный банковский сейф, где каждая транзакция на вес золота, то ClickHouse - это промышленная мясорубка. Ему все равно, уникальны ли ваши записи (по умолчанию), он не поддерживает классические транзакции, но зато он умеет делать SELECT count(*) FROM hits по миллиарду строк за доли секунды. Для...

Установка Claude Code на Ubuntu 24.04 — процесс довольно прямолинейный, но требующий аккуратности с версиями Node.js и правами доступа. Как «самоучка», я рекомендую использовать официальный скрипт установки или NPM, но без использования sudo для самого пакета, чтобы избежать проблем с правами в будущем. Claude Code - это специализированный CLI-инструмент от...

До этого момента все наши DAG-и жили по расписанию. schedule_interval='@daily' - это классика. Но современный бизнес не хочет ждать "утреннего отчета". Если данные прилетели в 14:00, отчет должен быть готов в 14:10, а не на следующее утро. Здесь мы сталкиваемся с фундаментальным конфликтом: Airflow - это Batch-инструмент (запускает задачи...

В прошлых статьях мы выяснили: если задача тяжелая и требует Java (Spark), мы используем SparkSubmitOperator. Но что делать, если у вас "тяжелый" Python? Типичная ситуация когда вы написали отличный код на Pandas внутри PythonOperator. На тестовом файле в 100 Мб все летало. В продакшене пришел файл на 10 Гб. Как...
Запуск по требованию Jupyter notebook и сохранение данных блокнотов .ipynb Этот гайд предназначен для тех кто использует эпизодически Jupyter Notebook и хочет иметь к ним доступ из Windows при этом оставляя возможность иметь доступ ко всем файлам блокнота и погасить Jupyter следующего раза. Итак приступим! Шаг 1: Подготовка...