
Сегодня разберем, как из ClickHouse обратиться к встроенной key-value БД RockDB, используя табличный движок EmbeddedRocksDB, и познакомимся с возможностями новой песочницы колоночной базы данных. Постановка задачи и DDL-скрипты Колоночная СУБД ClickHouse поддерживает несколько движков таблиц, включая интеграционные механизмы для взаимодействия со сторонними системами, одной из которых является key-value база данных...

Тонкости параллельной среды выполнения Cypher-запросов в NoSQL-СУБД Neo4j и критерии выбора runtime для аналитических и транзакционных сценариев работы с графами. Слотовая и конвейерная среды выполнения Вообще в графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. По умолчанию в версии в Community Edition используется слотовая, а...
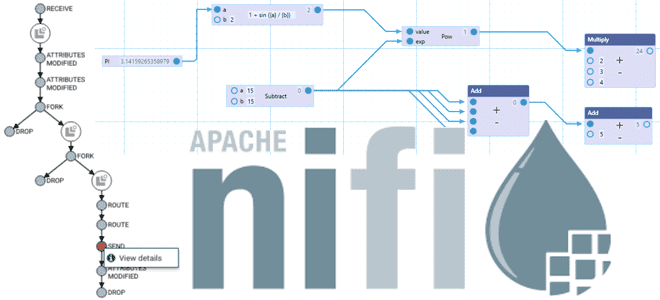
Что такое программирование потоков данных и как ключевые идеи FBP-парадигмы обеспечивают высокую скорость и мощь Apache NiFi в потоковой обработке. Что такое Flow-Based Programming Каждый дата-инженер, работающий с Apache NiFi, знает, что этот фреймворк поддерживает потоковую обработку информации, понимая под потоком неограниченно поступающие данные. Однако, фундаментальные концепции NiFi основаны на...

В конце февраля вышел очередной релиз Apache Kafka за номером 3.7. Поддержка JBOD в KRaft-кластерах, новый протокол перебалансировки потребителей, мониторинг метрик клиента на брокере, новинки Streams и Connect, и другие изменения самой популярной платформы потоковой передачи событий для дата-инженера и администратора. Изменения в брокерах, продюсера, контроллерах и Admin Client 27...
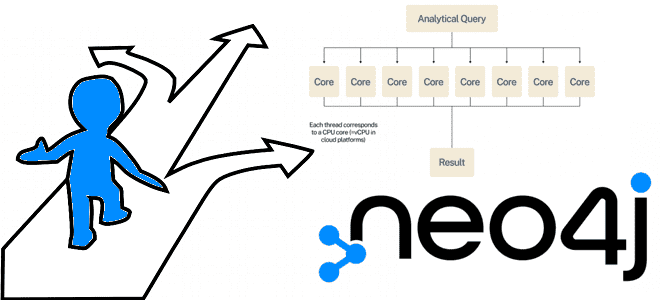
Чем слотовая среда выполнения Cypher-запросов в Neo4j отличается от конвейерной, как ее задать и что выбрать для транзакционных и аналитических сценариев работы с графами: наглядные примеры. Слотовая среда выполнения В графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. В большинстве случаев среды выполнения по умолчанию...

18 марта 2024 года вышел очередной релиз Apache Flink. Знакомимся с его главными новинками и разбираемся, чем они полезны для потоковой обработки больших данных: ключевые изменения выпуска 1.19 для разработчика stateful-приложений. Динамическая настройка параллелизма Выпуск Apache Flink 1.19 можно назвать значимой вехой, поскольку он не только включает новые функции, улучшения...
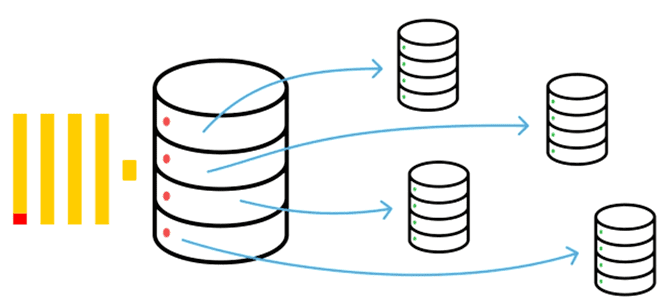
Как повысить производительность ClickHouse с помощью горизонтального масштабирования, разделив данные на шарды: принципы шардирования, стратегии выбора ключа, особенности работы с distributed-таблицами и настройки конфигураций сервера. Шардирование в ClickHouse Именно хранилище данных всегда является узким местом любой системы. Поэтому именно его надо расширить для повышения производительности. Это можно сделать с помощью...
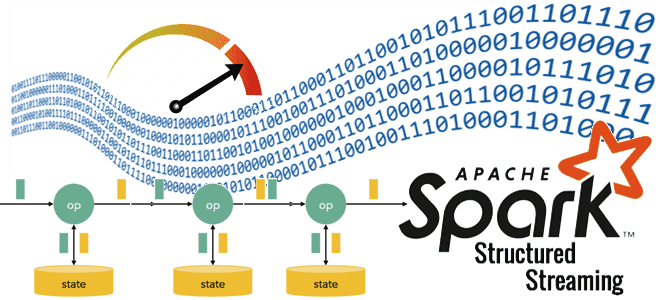
Где хранятся состояния операторов в stateful-приложениях Apache Spark Structured Streaming, зачем разработчику нужны данные о состояниях, как их получить и чем для этого полезен новый API State Reader от Databricks. Хранение состояние в Apache Spark Structured Streaming В феврале 2024 года компания Databricks выпустила очередную версию Databricks Runtime – среду...
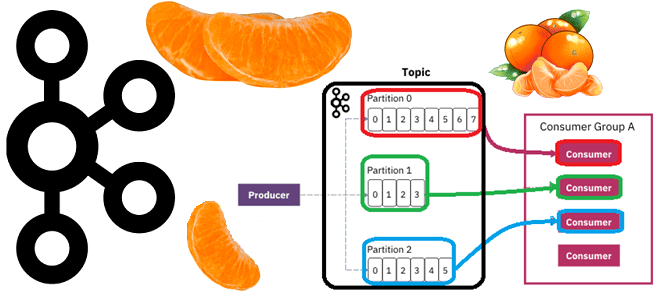
Почему раздел называется единицей параллелизма и как определить оптимальное число разделов в топике Apache Kafka в зависимости от количества потребителей и вариативности их поведения, разницы пропускной способности публикации и потребления сообщений, семантики партиционирования, толерантности к упорядоченности событий и ресурсных возможностей узла кластера. Что учитывать при разделении топика Apache Kafka Хотя...
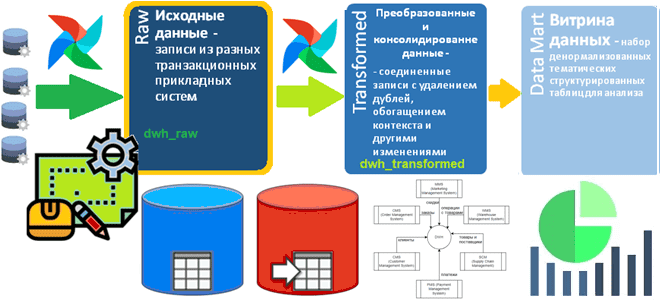
Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных. Постановка задачи: анализ систем-источников Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на...
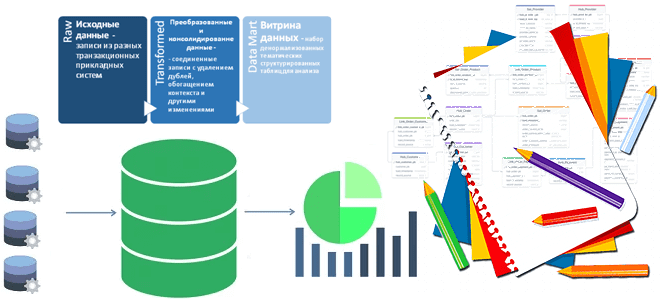
Как построить хранилище данных с подходом Data Vault: пример проектирования схемы данных и разработка DDL-скрипта для Transformed-слоя DWH интернет-магазина. Слоистая структура DWH и подход Data Vault Корпоративное хранилище данных (DWH, Data Warehouse) часто бывает гетерогенным, т.к. организованным с помощью нескольких баз данных, связанных ETL-процессами. Согласно концепции слоистой архитектуры (LSA, Layered...

Что такое гонка данных, почему она опасна в ETL-заданиях и как ее избежать: зачем разделять задания репликации в RAW-слой хранилища от их преобразования и сохранения в Transformed-слое DWH перед созданием витрин данных для BI-приложений. Что такое гонка данных в дата-инженерии Одна из главных особенностей распределенных систем – это задержка между...
29 января 2024 года вышла очередная веха 2-ой версии Apache NiFi, которая включает ряд новых функций и существенных обновлений зависимостей, а также несколько критических изменений. Рассмотрим самые интересные из них. Новые процессоры Apache NiFi 2.0.0-M2 С точки зрения управления версиями, веха рассматривается как некоторое значимое обновление, контрольная точка, меняющая дальнейшее...

Что такое graceful shutdown в Apache Kafka, когда используется такое плавное завершение работы, при чем здесь синхронизация реплик и как это влияет на плановые операции обслуживания кластера. Как работает механизм Graceful shutdown в Apache Kafka Благодаря множеству внутренних механизмов обеспечения отказоустойчивости, Apache Kafka имеет высокую надежность и позволяет строить нагруженные...

Почему тормозит Cypher-запрос к Neo4j, как его отладить и чем оператор PROFILE отличается от EXPLAIN. Краткий ликбез с примерами выполнения запросов к графовой базе данных для аналитиков и разработчиков. Как выполняются Cypher-запросы в Neo4j Любой дата-аналитик и разработчик, работающий с базами данных, знает, что одной из самых частых причин медленного...

От оркестрации и синхронизации конвейеров обработки данных до управления хранилищами, включая хранение состояний для stateful-приложений: сложности проектирования архитектуры потоковой обработки событий и способы их решения. Основные сложности проектирования современной архитектуры данных Из-за принципиальных отличий потоковой парадигмы обработки данных от пакетной, что разбиралось здесь, задача проектирования дата-конвейеров сильно усложняется, т.к. редко...

Как найти зависший процесс в базе данных Greenplum, создать резервную копию каталога, разделить лог-файл по тестам и проверить его на наличие повреждений. Знакомимся с набором утилит gpsupport. 6 инструментов утилиты gpsupport для техподдержки Greenplum Как и любая крупная система Greenplum, помимо компонентов, обеспечивающих ее ключевые функции, также включает дополнительные инструменты,...

Как с помощью Flink SQL организовать потоковую агрегацию данных из таблицы PostgreSQL: знакомство с API таблиц в Ververica Cloud на практическом примере. API таблиц Ververica Cloud: создаем внешние источники и приемники данных Как я недавно рассказывала, немецкая фирма Ververica создала высокопроизводительный облачный сервис для обработки данных в реальном времени на...
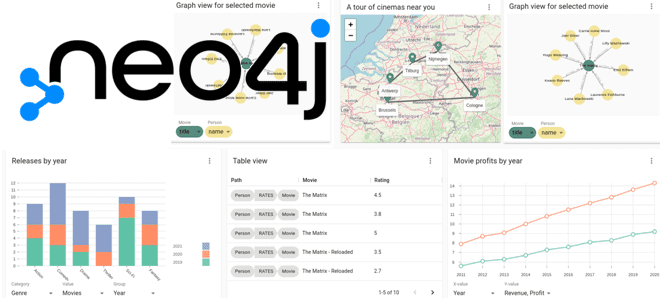
Создаем визуализации Cypher-запросов к своему графу в графовой базе данных Neo4j с помощью дэшборда NeoDash на примере анализа финансовых транзакций в банке. Python-генерация графа в Neo4j с фейковыми данными Поскольку NoSQL-СУБД Neo4j отлично подходит для задач графовой аналитики больших данных благодаря своей нативно графовой модели хранения данных, ее можно использовать...
Сегодня я покажу, как проверить доступность веб-сайта с помощью http-хука в Apache AirFlow и отправить результаты проверки в Телеграм-бот. Еще раз про хуки и соединения Apache AirFlow Доступность системы является ключевым свойством информационной безопасности. Проверить, что веб-сервис доступен, можно по статусу HTTP-ответа на GET-запрос. Чтобы делать такую проверку периодически, т.е....