
Что общего у Apache HBase с Google Bigtable, чем они отличаются и какую NoSQL-СУБД выбирать для практического использования. Чем похожи NoSQL-хранилища для больших данных Apache HBase часто называют Google BigTable для Hadoop, поскольку она обеспечивает аналогичные возможности и использует многие концепции этой облачной NoSQL-СУБД. В частности, именно Bigtable был выпущен...

В рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях сегодня познакомимся с графовой резидентной СУБД Memgraph и сравним ее с Neo4j, определив достоинства, недостатки и варианты использования в задачах аналитики больших данных. Memgraph vs Neo4j Memgraph — это высокопроизводительная графовая СУБД с открытым исходным кодом, которая хранит и...

Сегодня на примере Apache HBase и Redis разберемся со сходствами и отличиями NoSQL-СУБД типа «семейство колонок» и «ключ-значение». Что между ними общего и что выбирать для практического использования в зависимости от сценариев применения. 3 типа NoSQL-хранилищ данных Apache HBase и Redis являются довольно популярными базами данных среди NoSQL-решений. Однако, они...

Что общего у Neo4j с TigerGraph и чем они отличаются: разбираемся с популярными графовыми СУБД и их возможностями для аналитики больших данных в рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях. Сравнение Neo4j с TigerGraph Подробно об архитектуре, принципах работы, функциональных возможностях и вариантах использования TigerGraph мы писали...

Зачем биотехнологической платформе Polly от Elucidata понадобился API SQL-запросов в облачном сервисе Elasticsearch и как дата-инженеры реализовали его, развернув Delta Lake с AWS Atnena и S3. Что не так с SQL-запросами в облачном Elasticsearch на AWS Ежедневно биотехнологическая платформа Polly от Elucidata обрабатывает гигабайты биомолекулярных данных для биологов по всему...

Продолжая разговор про языки запросов к графовым базам данных, сегодня познакомимся с GSQL, который поддерживается в MPP-СУБД TigerGraph. Как работает эта распределенная NoSQL-база данных и каким образом реализует ACID-требования к транзакциям в операциях с графами. Архитектура и принципы работы графовой MPP-СУБД TigerGraph — это распределенное графоориентированное хранилище данных с массивно-параллельной...
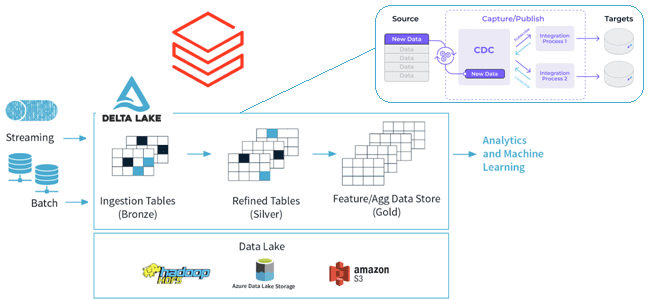
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных. CDC для Delta Lake Идея сбора и обработки не всего объема данных, а только...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...
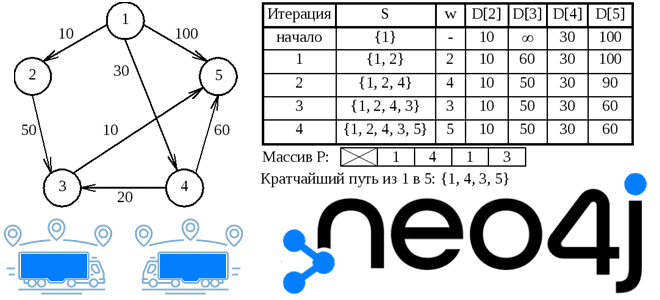
Вопрос перестройки логистических цепочек сегодня стал очень остро перед множеством предприятий, от малого до очень крупного бизнеса. Рассмотрим, как методы Data Science и аналитики больших данных помогают бизнесу справиться с современными вызовами на примере реализации алгоритма Дейкстры в библиотеке Graph Data Science графовой СУБД Neo4j. Постановка задачи: поиск кратчайшего пути...
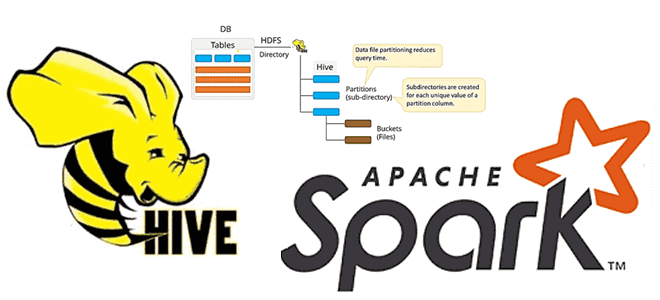
Недавно мы писали про обновление хранилища метаданных Apache Hive с помощью команды MSCK REPAIR TABLE, операторов AirFlow и Spark-заданий. В продолжение этой темы про работу с партиционированными Parquet-файлами сегодня рассмотрим применение Spark SQL для этого случая, чтобы использовать таблицу Hive вместо временного представления Spark. Временные таблицы Hive/Spark и разделы в Parquet-файлах...

В этой статье для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных разберем пример перевода сервиса Strava с кластера Cassandra в облачное хранилище AWS S3 и какую роль в этом сыграл вычислительный движок Apache Spark. Постановка задачи: слишком дорогая Cassandra Strava – это глобальный сервис отслеживания активности велосипедистов, бегунов...
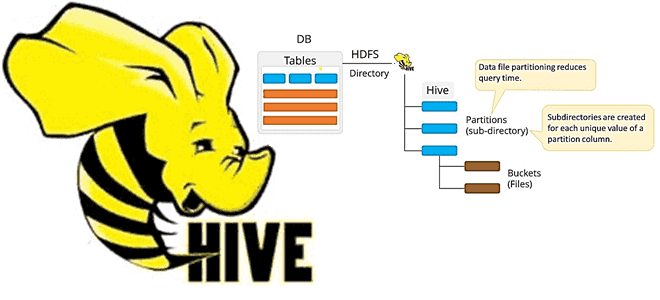
Что такое MSCK REPAIR TABLE в Apache Hive, зачем нужна эта команда, ее достоинства и недостатки, а также альтернативные варианты для задач пакетной дата-инженерии. Разбираем на примере конвейера обработки данных в ML-приложениях при работе с Data Lake. Команда MSCK REPAIR TABLE в Apache Hive В ML-приложениях особенно важно, как озеро данных (Data...

В этой статье для дата-инженеров и администраторов SQL-on-Hadoop рассмотрим, что такое Cloudera Data Platform Operational Database, как это связано с Apache HBase и Phoenix. Также разберем, каким образом перенести данные из кластера HBase в Cloudera Operational Database, избежав их потери и других подводных камней. Что такое Cloudera Operational Database: назначение...

Что такое Hive Transform, зачем это нужно дата-инженеру и разработчику распределенных приложений, где и как использовать эту функцию популярного средства SQL-on-Hadoop. Краткий обзор альтернативного способа операций с данными в Apache Hive, его возможности и ограничения, а также связь с HiveQL. Преобразования в Apache Hive Apache Hive – это популярная экосистема...

В прошлый раз мы говорили про метаданные в Apache Impala. Сегодня поговорим про функции командной строки в Impala. Читайте далее про особенности работы функций командной строки Impala, благодаря которым становится возможным процесс оптимизации обработки Big Data массивов. Как работают функции командной строки в Impala: особенности оптимизации обработки Big Data Командная...

Сегодня в рамках обучения дата-аналитиков и разработчиков распределенных приложений, рассмотрим, что такое пользовательские функции в Apache Hive, как их создать и использовать. А также в чем проблема вызова UDF-функции, зарегистрированной в Hive, из Impala и при чем здесь Sentry. Простые и сложные UDF в Apache Hive Пользовательские функции в Hive...

В прошлый раз мы говорили про DML-операции в Hive. Сегодня поговорим про DDL-операции в этой распределённой Big Data платформе. Также рассмотрим применение этих операций к объектам, хранящимся в этой СУБД. Читайте далее про особенности работы DDL-операции в Hive. DDL-операции в СУБД Apache Hive DDL-операции (Data Definition Language, Язык Определения Данных)...

В прошлый раз мы говорили про индексы в Hive. Сегодня поговорим про DML-операции в этой распределённой Big Data платформе. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про DML-операции в Hive и их особенности. DML-операции в СУБД Apache Hive DML-операции (Data Manipulation Language) -...

В прошлый раз мы говорили про особенности работы механизмов группировки и сортировки в распределенной среде Impala. Сегодня поговорим про метаданные таблиц в Impala и про то, как их извлекать и выводить на экран. Читайте далее про табличные метаданные в Impala, благодаря которым становится доступным и весьма удобным legacy-проектирование. Что из...

В этой статье мы поговорим про основные базовые операции распределенной СУБД Hbase. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД на практических примерах. Читайте далее про базовые CRUD-операции в Hbase и их особенности. Основные CRUD-операции в распределенной СУБД Hbase HBase - это распределенная NoSQL столбцово-ориентированная (данные представлены...