 1410
1410 
Содержание
Как развивались системы агентского ИИ, из каких компонентов они состоят, каковы их типовые архитектуры и чем отличаются друг от друга топологии построения рабочих процессов LLM.
История развития систем агентского ИИ
Развитие и практическое внедрение больших языковых моделей (LLM, Large Language Model) привело к появлению систем агентского ИИ, где LLM динамически управляют собственными процессами и использованием инструментов, сохраняя контроль над выполнением задач. Агенты ИИ используют инструменты (tools) для выполнения задач (tasks) – определенных действий, например, для получения или преобразования данных, запуска кода или взаимодействия с внешними службами. По своей сути, задачи ИИ-агента похожи на задачи в DAG-графе Airflow, а инструменты – на операторы AirFlow.
Исторически системы агентского ИИ развивались следующим образом:
- чат-бот на основе LLM, где большие языковые модели генерировали ответы на запросы пользователя, с учетом предварительно полученных знаний из обучающих датасетов;
- LLM с цепочками инструментов, расширяющими возможности больших языковых моделей. Например, RAG (Retrieval Augmented Generation) для увеличения базы знаний LLM с помощью пользовательских наборов документации и API для интеграции с внешними службами.
- ИИ-ассистент – приложение для прямого взаимодействия с пользователями и выполнения задач благодаря пониманию естественного человеческого языка и вводимых данных. ИИ ассистенты могут рассуждать и предпринимать действия от имени пользователей под их руководством. В отличие от полноценного ИИ-агента, ИИ-ассистент отвечает на запросы или промпты пользователя и может рекомендовать действия, но принятие решений остается за человеком.
- автономный ИИ-агент, который автономно планирует и выполняет задачи на основе своего понимания проблемы. ИИ-агенты по-прежнему используют инструменты, но сами решают, какой из них применять, когда и как.
- мультиагентная ИИ-система, где несколько ИИ-агентов сотрудничают или конкурируют для достижения общей цели.
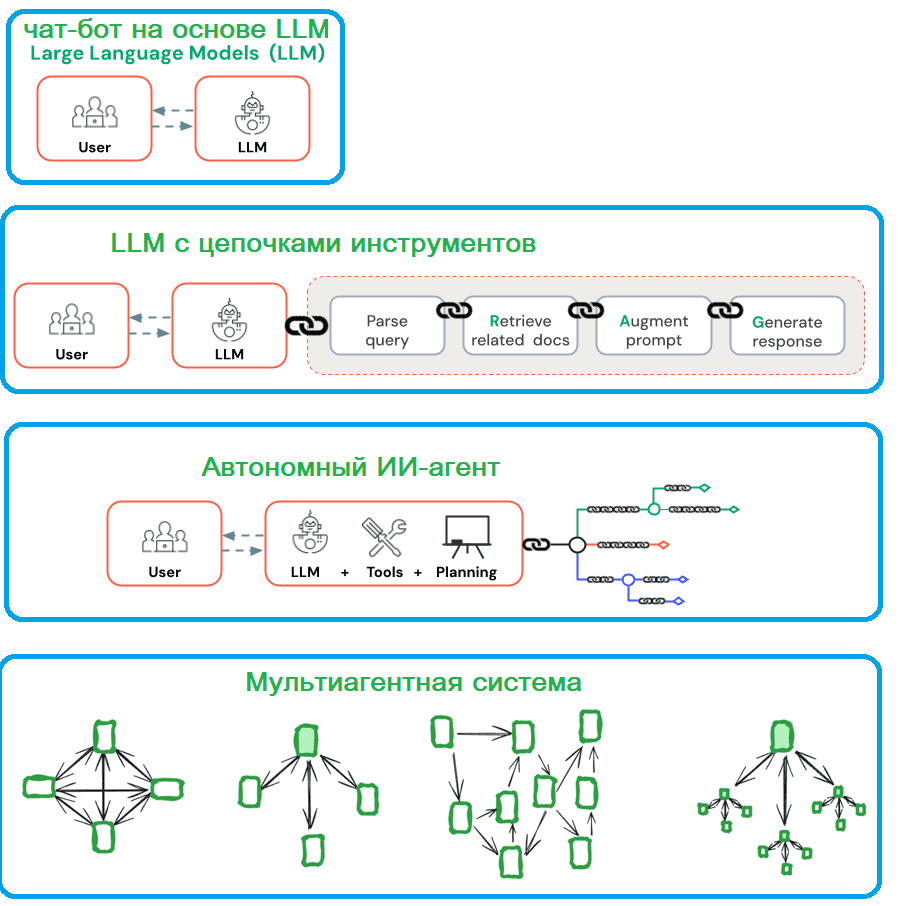
В первых двух уровнях рабочие процессы, состоящие из цепочки инструментов, обеспечивают предсказуемость и согласованность для четко определенных задач. Последние 2 уровня, т.е. полноценные агентские ИИ-системы больше подходят для ситуаций, когда нужны гибкость и динамическое принятие решений без четкого алгоритма. В отличие от предсказуемых рабочих процессов с использованием LLM, ИИ-агенты хороши для открытых задач, в которых трудно предопределить фиксированный путь решения. Автономность ИИ-агентов делает их идеальными инструментами для масштабирования задач в доверенных средах. Но автономность ИИ-агентов приводит к росту затрат и удорожанию стоимости ошибок. Впрочем, для многих приложений обычно достаточно оптимизации отдельных вызовов LLM с извлечением и примерами в контексте.
Современные системы агентского ИИ имеют следующие способности:
- рассуждать, используя логику и доступную информации для вывода заключений и генерации вариантов решения проблем. Агенты ИИ с сильными способностями к рассуждению могут анализировать данные, выявлять закономерности и принимать обоснованные решения на основе доказательств и контекста.
- действовать, т.е. выполнять задачи на основе решений, планов или внешнего ввода, например, отправка или загрузка данных, их обновление или запуск других процессов.
- наблюдать, т.е. выполнять непрерывный сбор информации об окружающей среде или ситуации через различные формы восприятия, такие как компьютерное зрение, обработка естественного языка или анализ данных датчиков. Это необходимо для понимания контекста и принятия обоснованных решений.
- планировать свою работу, определяя необходимые шаги и их потенциальные последствия, чтобы выбирать наилучший курс действий на основе доступной информации и желаемых результатов. Это часто включает в себя прогнозирование будущих состояний и анализ рисков.
- сотрудничество с людьми или другими агентами ИИ для достижения общей цели;
- саморазвитие— способность к самостоятельному улучшению на основе опыта и непрерывная коррекция поведения по обратной связи.
Таким образом, ИИ-агент поддерживает контекст, учится на опыте и обратной связи от пользователя, а также повышает свою производительность, вспоминая прошлые взаимодействия и адаптируясь к новым ситуациям. Чтобы оставаться в контексте, ИИ-агент оснащен следующими видами памяти:
- краткосрочная для немедленных взаимодействий;
- долгосрочная для исторических данных и разговоров;
- эпизодическая память для прошлых взаимодействий;
- консенсусная память для общей информации и обмена данными между агентами.
Топологии рабочих процессов и архитектуры систем агентского ИИ
В основе каждого вида систем агентского ИИ лежит LLM с инструментами, памятью и возможностями поиска. Благодаря этому они могут генерировать собственные поисковые запросы, выбирать соответствующие инструменты и определять, какую информацию сохранять.
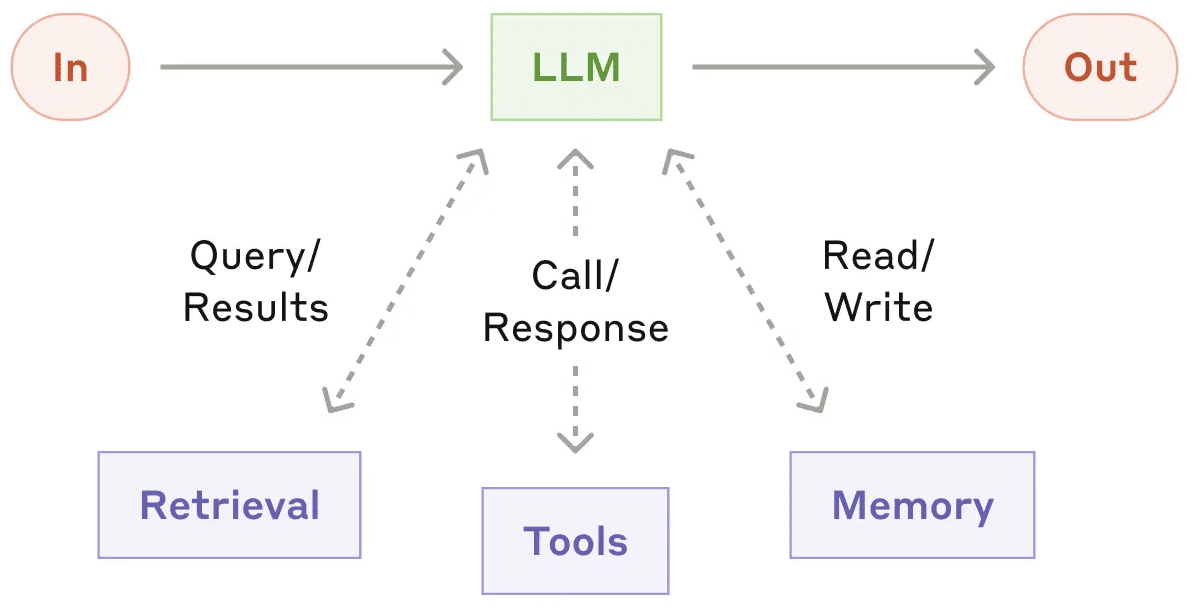
Чтобы получить сложный, но контролируемый и предсказуемый граф поведения агентской системы в виде набора LLM с цепочками инструментов, их следует соединить между собой. Для определения топологии такого графа есть ряд паттернов:
- цепочка промптов, когда их последовательность разбивает задачу на набор шагов, где каждый вызов LLM обрабатывает вывод предыдущего. Этот рабочий процесс идеально подходит для ситуаций, когда задачу можно легко и точно разложить на фиксированные подзадачи. Например, создание маркетингового текста и его перевод на другой язык, составление плана документа и его проверка с последующим наполнением контентом.
- маршрутизация, когда входные данные классифицируются и направляются в специализированную последующую задачу. Такой рабочий процесс позволяет разделять проблемы и создавать более специализированные промпты. Это позволяет более эффективно обрабатывать данных и утилизировать ресурсы. Маршрутизация хорошо подходит для сложных задач, где есть отдельные категории, которые можно точно выделить и обрабатывать по отдельности. Например, обработка пользовательских обращений разных типов, перенаправление различных по сложности вопросов в более мелкие или, наоборот, крупные ML-модели для оптимизации затрат и скорости.
- распараллеливание, когда несколько LLM работают над задачей одновременно и программно агрегируют результаты. Этот рабочий процесс может выполняться как партиционирование (разбиение задачи на независимые подзадачи, выполняемые параллельно) или голосование (выполнение одной и той же задачи несколько раз для получения разных результатов). Партиционирование полезно, когда один экземпляр модели обрабатывает запросы пользователя, а другой проверяет их на наличие несоответствующего контента или запросов. Еще один сценарий применения этого паттерна — автоматизация оценки производительности LLM, где каждый вызов LLM оценивает отдельный аспект производительности модели по заданному запросу. Голосование подходит для проверки фрагмента кода на наличие уязвимостей, когда несколько различных команд проверяют код и отмечают его, если находят проблему. Также голосование подойдет для оценки приемлемости контента на основе промптов, оценивающих различные его аспекты или требующие разных пороговых значений, чтобы сбалансировать ложные положительные и отрицательные результаты.
- оркестратор-исполнители, где оркестратор — центральная LLM динамически разбивает задачи и делегирует их другим LLM – исполнителям, в последствии агрегируя их результаты. Такой рабочий процесс хорошо подходит для сложных задач, где количество подзадач нельзя предсказать заранее. Главным отличием этого паттерна от распараллеливания является его гибкость: подзадачи не определены заранее, а определяются оркестратором на основе конкретных входных данных. Например, поисковые задачи, включающие сбор и анализ информации из нескольких источников для поиска потенциально релевантной информации.
- оценщик-оптимизатор, где одна LLM генерирует ответ, а другая оценивает его и обеспечивает обратную связь, повышая качество ответов. Это похоже на генеративно-состязательные нейросети (GAN, Generative Adversarial Network), которые сегодня часто используются для получения фотореалистичных изображений, подготовки видеокадров и трёхмерной графики. Оценщик-оптимизатор особенно эффективен, когда есть четкие критерии оценки и итеративное уточнение обеспечивает измеримую ценность. Например, литературный перевод, и сложные поисковые задачи, требующие нескольких раундов поиска и анализа для сбора информации с ее последующей оценкой для принятия решений насчет дальнейших поисков.
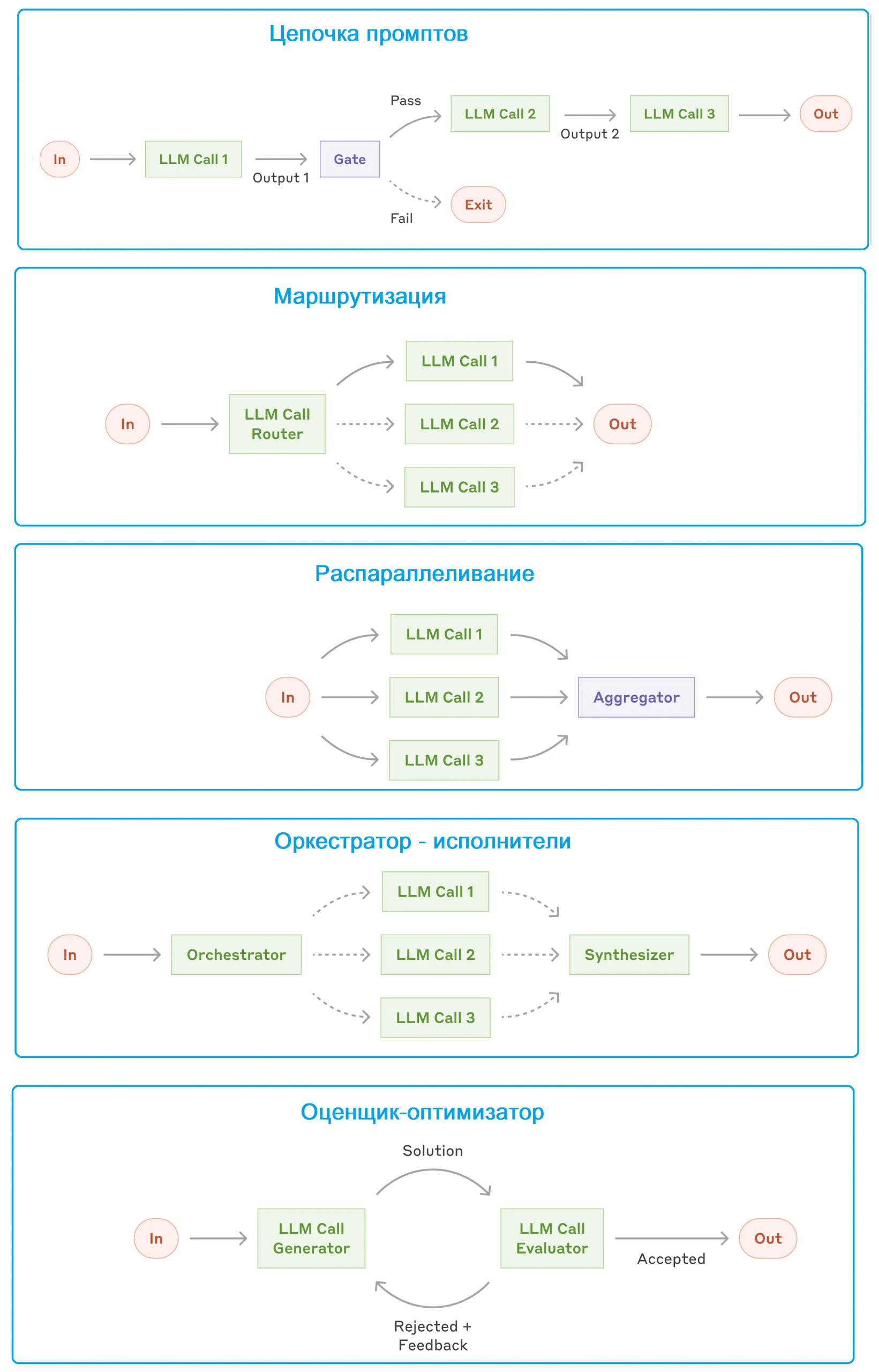
Как эти топологии можно реализовать на практике, рассмотрим в следующий раз, написав небольшой код на Python для создания рабочего процесса LLM с инструментами, используя API на основе Pydantic AI.
Узнайте больше про машинное обучение и ИИ на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://learn.microsoft.com/ru-ru/azure/databricks/generative-ai/agent-framework/ai-agents
- https://cloud.google.com/discover/what-are-ai-agents?hl=ru
- https://relevanceai.com/docs/get-started/introduction
- https://www.anthropic.com/engineering/building-effective-agents
- https://langchain-ai.github.io/langgraph/concepts/multi_agent/