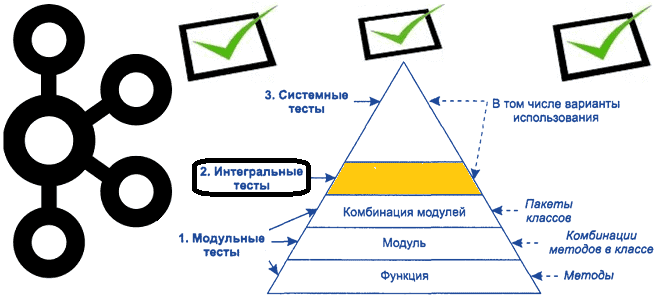
Продолжая важную для обучения разработчиков распределенных приложений и дата-инженеров тему про тестирование Big Data систем на базе Apache Kafka, сегодня рассмотрим некоторые средства для создания интеграционных тестов. Краткий ликбез по интеграционному тестированию приложений Apache Kafka В отличие от модульного тестирования, которое мы разбирали ранее, интеграционное тестирование сосредоточено на интерфейсах и потоке...
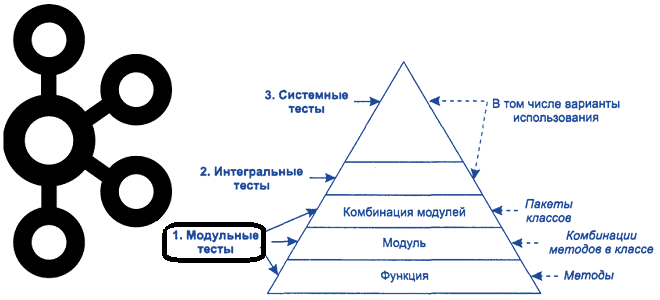
Чтобы сделать наши курсы по Apache Kafka еще полезнее, сегодня разберем, как тестировать распределенные приложения на базе этой платформы потоковой обработки событий. Краткий ликбез для разработчика Kafka Streams и дата-инженера: классы, методы и приемы модульных тестов с примерами. Ликбез по модульному тестированию: что такое mock-объекты Про виды тестирования мы уже...
Мы уже рассказывали, что такое реестр схема Apache Kafka и зачем он нужен. Чтобы глубже разобраться с этой темой, важной для обучения разработчиков распределенных приложений и дата-инженеров, сегодня заглянем под капот Schema Registry и разберем работу этого компонента платформы Confluent Apache Kafka с продюсерами и потребителями. Еще раз про реестр...
Недавно мы писали про Yandex Managed Service for Apache Kafka. Продолжая тему импортозамещения, сегодня рассмотрим, как этот и другие полностью управляемые сервисы Яндекса помогли отечественному маркетплейсу KazanExpress построить эффективное BI-решение. Что такое Yandex DataLens и как он способен заменить зарубежные системы бизнес-аналитики типа Tableau с Power BI, а также открытый Apache...

В свете импортозамещения сегодня рассмотрим российские альтернативы облачных управляемых сервисов для развертывания Apache Kafka. Сравнение отечественных Yandex Managed Service for Apache Kafka и VK Cloud Solutions Big Data с зарубежным Confluent Cloud. Облачная Apache Kafka от Confluent и не только Пожалуй, самым популярным облачным сервисом Apache Kafka во всем мире...
Сегодня рассмотрим, можно ли построить на Apache Kafka быстрый и надежный блокчейн для криптовалюты, NFT или других проектов, где нужны технологии распределенного реестра. Что общего у топика Apache Kafka с blockchain-цепочкой, чем они отличаются, возможно ли совместить их и для каких случаях. А в качестве примеров перечислим несколько реальных проектов....
Иногда в распределенных системах требуется строгий порядок событий, т.е. сообщений или записей с полезными данными и состоянием, который должен поддерживаться между продюсерами и потребителями в конвейере их обработки. Например, чтобы сохранить корректный порядок транзакций для правильного расчета остатков по счетам. Читайте далее, как это реализовать в Apache Kafka. Настройка продюсера...
Недавно мы писали про проектирование микросервисной архитектуры на базе Apache Kafka. В продолжение этой актуальной для ИТ-архитекторов, разработчиков и дата-инженеров темы, сегодня рассмотрим опыт американской медиакомпании Storyblocks по переходу от монолитной архитектуры системы поставки контента к распределенным микросервисам с Apache Kafka в Confluent Cloud. Постановка задачи: монолит vs микросервисы По...

В рамках обучения ИТ-архитекторов и разработчиков распределенных приложений рассмотрим, что представляет собой Transactional Outbox и как этот паттерн проектирования микросервисной архитектуры можно реализовать с помощью Neo4j и Apache Kafka, чтобы создать масштабируемый, общий и абстрактный способ запроса информации независимо от типа объекта. Постановка задачи: проблемы микросервисной архитектуры и способы их...
Мы уже рассказывали, что такое Graceful shutdown на примере Spark Streaming. Сегодня разберем реализацию этой идеи плавного завершения задач в потоковой обработке данных применяется в компании Carwow при работе с Apache Kafka и dyno-контейнерами приложений Heroku. Потоковая обработка данных и проблема завершения потоковых заданий в контейнерах Heroku Carwow - британская...

Практический пример аналитики больших данных в реальном времени с Apache Spark, Kafka, ClickHouse и AWS S3: возможности, архитектура, также специально для дата-инженеров и разработчиков распределенных приложений рассмотрим, сколько времени нужно для разрешения каждого вызова API в определенном временном диапазоне. Анализ событий пользовательского поведения в реальном времени Основным продуктом международной ИТ-компании...

Сегодня поговорим про администрирование кластера Apache Kafka и разработку потоковых приложений передачи и разберем, как обеспечить их работу в бессерверном режиме с платформой Upstash. Финансовая экономия, простота сопровождения и другие преимущества FaaS-сервисов и serverless-подхода с RESTfull API для обработки событий в реальном времени. Снова про serverless: что такое Upstash Kafka...
Мы уже рассматривали особенности обработки вложенных структур данных на примере парсинга JSON-файлов с Apache Spark и Hive. Развивая эту тему, сегодня поговорим про перенос записей с вложенными массивами из топиков Apache Kafka в реляционные СУБД с пользовательскими SMT-преобразователями и JDBC-коннектором: кейс для разработчиков. Проблемы обработки сложных структур данных с JDBC-коннектором...
Вчера мы писали о недавно вышедшем свежем релизе Apache Kafka 3.1.0, который вышел в январе 2022 года. Сегодня рассмотрим, как безболезненно перейти на эту версию и избежать возможных побочных эффектов, связанных с некоторыми архитектурными изменениями платформы. Побочные эффекты и подводные камни обновления Напомним, в Apache Kafka 3.1.0 добавлена новая фича...

24 января 2022 года вышел новый релиз Apache Kafka. Главные новинки самой последней на сегодня стабильной версии 3.1.0: добавленные фичи, улучшения и исправленные баги краткий обзор для разработчиков распределенных приложений Kafka Streams и администраторов кластера этой платформы потоковой передачи событий. Новинки Apache Kafka 3.1.0 для администратора кластера В свежем релизе...
Недавно мы писали про архитектурный шаблон CQRS и его реализацию на базе Apache Kafka. В продолжение этой темы для обучения ИТ-архитекторов и разработчиков Big Data приложений, сегодня рассмотрим еще несколько популярных шаблонов проектирования распределенных систем: достоинства, недостатки, примеры реализации и способы их использования. Шаблоны проектирования распределенных систем: что это и...
Сегодня обсудим ключевые тренды развития дата-инженерии и инструментальные средства их реализации. Как это применяется на практике, рассмотрим на примере эволюции хранилища данных в индонезийской ИТ-компании Bukalapak, от локального кластера Apache HBase до Лямбда-архитектуры в облаке Google Cloud Platform с Kafka, Spark и AirFlow. 7 главных драйверов развития дата-инженерии В наши...
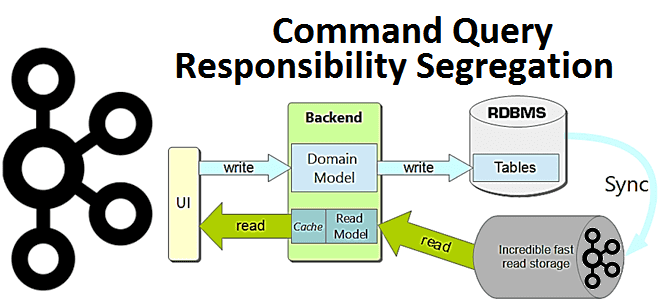
В этой статье для разработчиков распределенных приложений и ИТ-архитекторов разберем достоинства и недостатки паттерна проектирования CQRS, а также рассмотрим пример его реализации на Apache Kafka, Spring Cloud Stream и MongoDB. Что такое CQRS: основы проектирования архитектуры приложений Спрос на приложения, управляемые событиями, постоянно растет как для решения новых бизнес-задач, так...

Недавно мы писали про развертывание Apache Kafka на Kubernetes с помощью open-source проекта Strimzi. Сегодня рассмотрим, как обеспечить безопасный доступ к данным на таком кластере, применив различные методы аутентификации и авторизации. Лучшие практики cybersecurity на практическом примере. Постановка задачи: пример приложения с безопасным доступом к данным Напомним, Strimzi – это...

Чтобы сделать наши курсы для дата-инженеров еще более интересными, сегодня рассмотрим практический пример построения инфраструктуры для автоматической диагностики и исправления ошибок пакетной и потоковой обработки данных в Netflix. Комплексная система на базе Apache Spark, Kafka, Flink, Druid, сервисов AWS и других технологий Big Data. Предыстория: зачем Netflix разработал Pensive Обработка...