В недавней статье про преимущества хранилища метаданных Apache Hive и другие плюсы этого популярного инструмента SQL-on-Hadoop, мы упоминали формат открытых таблиц Iceberg как альтернативу для хранения огромных наборов аналитических данных. Он добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы Spark, Trino, Presto, Flink и Hive. Сегодня рассмотрим подробнее, что такое Apache Iceberg и...
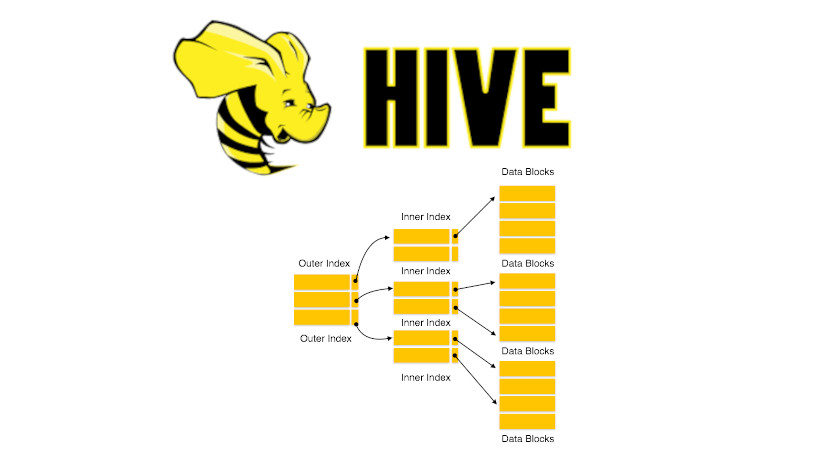
В прошлый раз мы говорили про драйвер JDBC и его использование в Hive. Сегодня поговорим про особенности создания и работы индекса в распределенной Big Data платформе Apache Hive. Читайте далее про особенности работы с индексами в распределенной среде Big Data СУБД Hive. Какую роль играет использование индекса при обработке Big...
Появившись более 10 лет назад, Apache Hive до сих пор является самым популярным инструментом стека SQL-on-Hadoop и активно используется для аналитики больших данных. Однако, технологии Big Data постоянно развиваются: Spark все чаще заменяет Hadoop MapReduce, а вместо HDFS все чаще используются объектные облачные хранилища: AWS S3, Delta Lake, Apache Ozone...
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...

В рамках курсов по Apache Hadoop для дата-аналитиков и инженеров данных сегодня рассмотрим пару практических примеров работы с популярным SQL-on-Hadoop инструментом этой экосистемы. Читайте далее, как настроить соединение удаленного сервера Apache Hive к Spark-приложению через JDBC и решить проблему запроса таблицы HBase в Hive вместо повторной репликации данных. Подключение удаленного...

Сегодня рассмотрим, что такое Beekeeper и как этот сервис помогает администраторам Hadoop и пользователям Apache Hive очищать метаданные этого NoSQL-хранилища. Читайте далее, зачем удалять устаревшие пути из Metastore и как настроить конфигурацию Hive-таблиц для автоматического прослушивания событий их изменения. Для чего очищать потерянные метаданные в Apache Hive Напомним, Apache Hive...

В прошлый раз мы говорили про особенности работы с основными join-операциями в Hive. Сегодня поговорим про использование JDBC-драйвера при работе в распределенной Big Data платформе Apache Hive. Читайте далее про особенности использования этого драйвера при работе в распределенной среде Hive. Использование драйвера JDBC в распределенной СУБД Apache Hive Драйвер JDBC...

В июле 2021 года «Аренадата Софтвер», российская ИТ-компания разработчик отечественных решений для хранения и аналитики больших данных, представила минорный релиз корпоративного дистрибутива на базе Apache Hadoop — Arenadata Hadoop 2.1.4. Главными фишками этого выпуска стало наличие 3-й версии Apache Spark и External PostgreSQL для Hive MetaStore. Сегодня рассмотрим, что именно...

Вчера мы упоминали, что использование Spark или Tez в качестве движка исполнения SQL-запросов в Apache Hive вместо классического Hadoop MapReduce намного ускоряет аналитику больших данных. Сегодня рассмотрим подробнее, чем отличаются эти механизмы и какой из них выбирать в разных случаях использования. Что такое Apache Tez и как он работает с...

Apache Hive – востребованный инструмент класса SQL-on-Hadoop, который также активно используется в работе с фреймворком Spark. Поэтому сегодня разберем важную тему из обучения дата-инженеров и аналитиков больших данных про оптимизацию SQL-запросов в этом NoSQL-хранилище. Смотрите, чем полезна векторизация HiveQL-операций, какие форматы файлов обрабатываются быстрее, почему денормализация данных в Hive –...

В прошлый раз мы говорили про особенности работы с базовыми CRUD-операциями в Hive. Сегодня поговорим про основные join-операции в распределенной Big Data платформе Apache Hive. Также рассмотрим применение этих операций к данным, хранящимся в этой СУБД. Читайте далее про особенности работы с join-операциями в распределенной СУБД Apache Hive. Join-операции в...

Сегодня рассмотрим инструмент, который облегчает практическое использование Apache Spark, позволяя дата-аналитику и разработчику распределенных приложений быстро писать и выполнять SQL-запросы в рамках удобного веб-редактора. Читайте далее, что такое Hue, как он связан со Spark SQL и Hive, а также причем здесь Livy. Что Hue и при чем здесь Apache Livy...

Продолжая разбирать особенности бакетирования таблиц в Apache Spark, сегодня мы рассмотрим несколько примеров, как дата-инженер и аналитик данных могут работать с этим методом оптимизации SQL-запросов. Также читайте далее, какие конфигурации Apache Spark SQL связаны с бакетированием таблиц и что нового появилось в 3-ей версии этого Big Data фреймворка, чтобы такой...
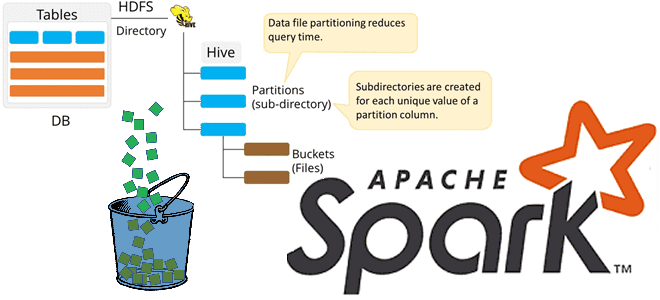
Бакетирование таблиц в Apache Spark – один из самых популярных методов оптимизации производительности задач последовательного чтения данных. Сегодня поговорим про сложности бакетирования с точки зрения дата-инженера, а также рассмотрим факторы, от которых зависит оптимальное количество бакетов. Большая проблема маленьких файлов и бакетирование таблиц в Apache Spark Напомним, бакетирование ускоряет выполнение...

В этой статье рассмотрим, как сделать SQL-запросы к колоночному хранилищу больших данных с поддержкой ACID-транзакций Delta Lake еще быстрее с помощью Apache Presto. Читайте далее про синергию совместного использования Apache Spark и Presto в Delta Lake для ускорения OLAP-процессов при работе с Big Data. Еще раз об OLAP: схема звезды...

В прошлый раз мы говорили про виды таблиц для быстрой работы с Big Data в Apache Hive. Сегодня поговорим про создание пользовательских функций и их применение в Hive. Читайте далее про особенности создания и применения UDF для работы с Big Data в распределенной платформе Apache Hive. Что такое пользовательские функции...
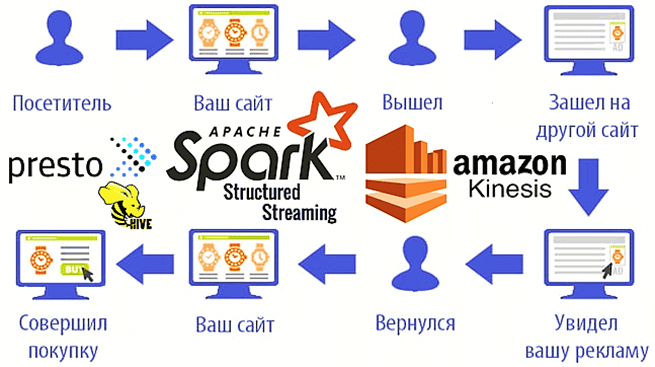
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

В прошлой статье мы рассматривали архитектуру Apache Hive и ее основные элементы. Сегодня поговорим про основные виды таблиц в Hive. Также подробно рассмотрим создание этих таблиц на практических примерах. Читайте далее про виды таблиц в Hive и их особенности. 2 основных вида таблиц для быстрой работы с большими данными в...

В этой статье мы поговорим про структуру системы управления базами данных (СУБД) Apache Hive. Также рассмотрим, какие базовые компоненты входят в структуру известной SQL-подобной СУБД, входящей в экосистему Hadoop. Читайте далее про основные компоненты структуры Apache Hive, которые делают эту СУБД весьма удобным и мощным средством хранения и обработки больших...

В этой статье разберем ключевые характеристики идеального конвейера обработки больших данных. Читайте далее, чем отличается Big Data Pipeline, а также какие приемы и технологии помогут инженеру данных спроектировать и реализовать его наиболее эффективным образом. В качестве практического примера рассмотрим кейс британской компании кибербезопасности Panaseer, которой удалось в 10 раз сократить...