 1407
1407 
Содержание
Как расширение Citus повышает производительность PostgreSQL, организуя распределенный кластер с помощью шардирования и почему этого недостаточно для эффективных OLAP-запросов как в Greenplum.
Что такое Citus для PostgreSQL
Поскольку Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных, у тех, кто знакомится с Greenplum впервые, возникает вопрос, в чем отличие этих СУБД. Ключевой разницей между ними является архитектура: Greenplum изначально разрабатывался как аналитическая СУБД с поддержкой массивно-параллельной обработки (MPP) для выполнения сложных аналитических запросов с огромными объемами данных.
Клиенты Greenplum отправляют запросы координатору кластера, который взаимодействует с сегментами – другими экземплярами PostgreSQL, где хранятся и обрабатываются данные. Сегменты взаимодействуют друг с другом по интерконнектам — межсетевым соединениям, обеспечивающим межпроцессное взаимодействие с высокой производительностью, о чем мы писали здесь. Однако, PostgreSQL тоже можно адаптировать для работы с большими объемами данных, установив в нее расширение Citus. Citus добавляет в PostgreSQL возможности горизонтального масштабирования, позволяя распределять данные и запросы по множеству узлов. Он хорошо подходит для транзакционных нагрузок и аналитических запросов в реальном времени.
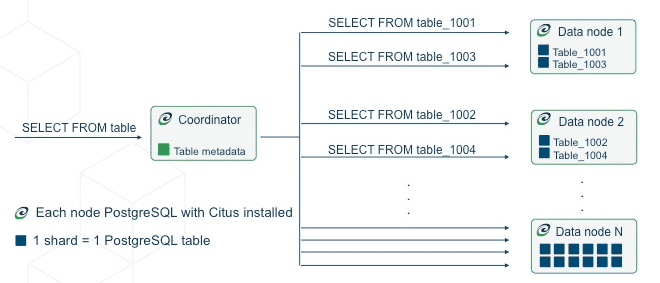
Citus преобразует отдельные экземпляры PostgreSQL в распределенный кластер, который будет размещать части табличных данных (шарды), где данные распределены по ключу шардирования. Также Citus работает как колоночное хранилище, позволяет использовать распределенный механизм запросов данных из любого узла. Сочетание параллелизма Citus, хранения большего количества данных в памяти и высокой пропускной способности ввода-вывода полезно в многопользовательских SaaS-приложениях и рабочих нагрузок временных рядов.
Однако, Citus не может использоваться совместно с автономными транзакциями PostgreSQL. Запросы к распределённым таблицам Citus могут возвращать некорректные результаты при установке параметра enable_self_join_removal в значение on. Кроме того, Citus не стоит использовать совместно с перепланированием запросов в реальном времени и с выключенным параметром конфигурации standard_conforming_strings.
По сути, Citus предоставляет распределенный движок поверх изначально автономных экземпляров PostgreSQL. Greenplum тоже использует отдельные экземпляры на сегментах и мастере. Однако, с архитектурной точки зрения они отличаются. Кроме того, в них по-разному реализуются распределенные транзакции, что мы и разберем далее.
Распределенные транзакции в Citus и Greenplum
Citus может применять ограничение первичного ключа или уникальности только для столбцов с ключом распределения. Столбец с первичным ключом тоже должен быть столбцом распределения. Благодаря этому Citus локализует проверку уникальности в одном сегменте и PostgreSQL может выполнять проверку уникальности на рабочем узле.
В Citus можно подключиться к любому узлу и начать работать с распределенными таблицами благодаря синхронизации метаданных внутри двухфазной транзакции. Citus использует libpq-протокол и libpq-соединения для соединений между узлами, которые кэшируются и используются повторно. Напомним, libpq — это библиотека C, обеспечивающая интерфейс для взаимодействия с PostgreSQL. Она служит клиентской частью, позволяя приложениям подключаться к PostgreSQL-серверу, отправлять SQL-запросы и получать результаты. Библиотека поддерживает управление транзакциями, включая их фиксацию и откат, а также имеет функции обработки ошибок, позволяя получать детальную информацию о возникших проблемах. Libpq считается базовой библиотекой, на основе которой построены многие другие клиентские библиотеки и драйверы для разных языков программирования, обеспечивающие стандартный и надежный способ подключения к PostgreSQL. Greenplum тоже использует libpq-протокол (собственный вариант) для отправки запросов сегментам, а данные перемещаются через быстрый интерконнект.
Для распараллеливания команд с одним узлом Citus поддерживает несколько соединений, когда это возможно. Поэтому для транзакций, затрагивающих несколько таблиц, после записи в шард, все транзакции, работающие с шардами этой группы, должны использовать одно и то же соединение, чтобы предупредить нарушение изоляции транзакций. Citus должен контролировать количество параллельных соединений, чтобы не перегружать узлы, соблюдать правила видимости данных и избегать взаимоблокировок.
Хотя Citus работает поверх PostgreSQL, для управления распределенными транзакциями он использует протокол двухфазной фиксации (2PC), а не MVCC-подход с моментальными снимками. В PostgreSQL используется многоверсионное управление параллельностью (MVCC), чтобы обеспечить согласованность данных без блокировок на уровне чтения. Однако MVCC, как таковой, не решает всех проблем, связанных с согласованностью в распределенных системах. Протокол двухфазной фиксации (2PC) используется в Citus для координации распределённых транзакций, потому что он позволяет обеспечить атомарность и согласованность изменений, вносимых в разные узлы кластера. В распределенной системе данные могут находиться на разных узлах, и для того чтобы гарантировать, что транзакция будет зафиксирована либо на всех узлах, либо не зафиксирована нигде, необходим механизм координации — именно этим занимается 2PC.
MVCC полезен для управления одновременными транзакциями на одном узле, обеспечивая изолированность и согласованность на уровне отдельных версий строк в базе данных. Но для распределенных транзакций нужно координировать изменения между несколькими узлами. Для этого нужен дополнительный механизм вроде 2PC, чтобы гарантировать, что все части транзакции зафиксированы или отменены вместе, поддерживая целостность данных в распределенной системе. Тем не менее, в Citus ранее подготовленные транзакции на отдельных узлах применяются в разное время. Поэтому последующая транзакция сможет прочитать данные, которые были применены на одном узле, но еще не были применены на другом. Фактически, это нарушает принцип атомарности, позволяя увидеть часть данных о зафиксированной транзакции. В Greenplum это невозможно благодаря работе со снапсшотами, что мы описывали здесь и здесь. Ядро MPP-СУБД отслеживает информацию об активных распределенных транзакциях, храня идентификатор распределенной транзакции в общей памяти процесса каждого бэкенда, аналогично стандартным локальным идентификаторам транзакций PostgreSQL. Координатор запросов отвечает за генерацию и назначение значения идентификатор распределенной транзакции.
Масштабирование, балансировка и быстродействие
Citus использует потоковую репликацию PostgreSQL для репликации всего рабочего узла как есть. Он реплицирует рабочие узлы, непрерывно передавая их записи WAL на резервный узел. Поскольку узел-координатор Citus похож на стандартный сервер PostgreSQL, можно использовать обычную синхронную репликацию и отказоустойчивость PostgreSQL для обеспечения более высокой доступности узла-координатора. Такая синхронная репликация помогает повысить устойчивость к сбоям узла-координатора.
Citus разбивает большие таблицы на более мелкие части (шарды), и распределяет их по нескольким узлам кластера. Это позволяет параллельно обрабатывать запросы и эффективно использовать ресурсы нескольких серверов. Так Citus может выполнять запросы параллельно на разных узлах, что значительно ускоряет операции, особенно на больших объемах данных. Это достигается за счет распределения работы над шардами между узлами. Распределение данных по узлам позволяет равномерно распределять нагрузку, что улучшает общую производительность системы.
Архитектура Citus допускает различные подходы к реализации механизмов распределения данных и балансировки нагрузки. Перекос данных не является проблемой, в отличии от Greenplum, что мы разбирали здесь. Поэтому при неравномерном распределении данных в кластере Greenplum обычно проводится перебалансировка.
В Greenplum управление ресурсами основано на группах ресурсов, чтобы распределить их между множеством корпоративных пользователей с разными задачами. Citus реализует управление ресурсами за счет многопоточности и разделения запросов на подзадачи, которые взаимодействуют с отдельными физическими шардами.
В Greenplum данные распределяются и обрабатываются параллельно на множестве сегментов, что позволяет эффективно выполнять сложные аналитические задачи. Citus позволяет распределять таблицы по узлам, но больше ориентирован на OLTP-нагрузки, чем OLAP, поскольку при сложных запросах данных сложно настроить совместно размещенные столбцы для каждого запроса. Планировщик Greenplum лучше обрабатывает сложные OLAP-запросы. Кроме того, из-за отсутствия поддержки MVCC-снимков Citus не гарантирует соблюдение видимости для зафиксированных транзакций в пределах всего кластера. Это может привести к непоследовательным или устаревшим данным, что особенно критично для аналитических задач, где необходимы точность и актуальность. Без гарантированной видимости зафиксированных транзакций сложнее обеспечить целостность данных на уровне приложения, что чревато ошибками или непредвиденными результатами в аналитических отчетах.
Таким образом, хотя установка Citus расширяет возможности PostgreSQL, она не делает его эквивалентом Greenplum, поскольку оба решения имеют разные архитектурные подходы и оптимизированы для различных типов рабочих нагрузок. Citus может повысить производительность PostgreSQL в распределенных OLTP-нагрузках. А Greenplum имеет специфические функции аналитической обработки больших данных, включая поддержку сложных аналитических запросов, инструменты машинного обучения, а также интеграцию с различными инструментами анализа и ETL/ELT-процессов.
Освойте администрирование и эксплуатацию Greenplum для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

