
В конце 2020 года вышел мажорный релиз Apache AirFlow, основные фишки которого мы рассмотрим в этой статье. Читайте далее про 10 главных обновлений Apache AirFlow 2.0, благодаря которым этот DataOps-инструмент для пакетных заданий обработки Big Data стал еще лучше. 10 главных обновлений Apache AirFlow 2.0 Напомним, разработанный в 2014 году...

Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...

Аналитика больших данных напрямую связана с их качеством, которое необходимо отслеживать на каждом этапе непрерывного конвейера их обработки (Pipeline). Сегодня рассмотрим методы и средства обеспечения Data Quality на примере корпорации Airbnb. Читайте далее про лучшие практики повышения качества больших данных от компании-разработчика самого популярного DataOps-инструмента в мире Big Data, Apache...
Продвигая наши курсы по Apache AirFlow для инженеров Big Data, сегодня расскажем, чем этот фреймворк отличается от Luigi – другого достаточно известного инструмента оркестровки ETL-процессов и конвейеров обработки больших данных. В этой статье мы собрали для вас сходства и отличия Apache AirFlow и Luigi, а также их достоинства и недостатки,...
Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...

Сегодня поговорим про особенности перехода с локального Hadoop-кластера в облачное SaaS-решение от Google – платформу Dataproc. Читайте далее, какие 5 шагов нужно сделать, чтобы быстро развернуть и эффективно использовать облачную инфраструктуру для запуска заданий Apache Hadoop и Spark в системах хранения и обработки больших данных (Big Data). Шаги переноса Data...

Вчера мы рассматривали проблему управления накладными расходами в сложных конвейерах обработки больших данных на примере использования Apache AirFlow в агрегаторе аренды частного жилья Airbnb. Сегодня разберем, как именно инженеры компании решили проблему роста накладных расходов, отделив бизнес-логику от логики оркестрации в конвейерах Spark-заданий. Читайте далее про принципы проектирования Big Data...
Продолжая разговор про конвейеры обработки больших данных, сегодня рассмотрим пример использования Apache AirFlow в агрегаторе аренды частного жилья Airbnb. Читайте далее, в чем коварство накладных расходов при росте ETL-операций и других data pipeline’ов по запуску и выполнению заданий Spark, Hadoop и прочих технологий Big Data. Еще в этой статье разберем,...

Мы уже рассказывали про основные достоинства и недостатки Apache Airflow, с которыми чаще всего можно столкнуться при практическом использовании этого оркестратора конвейеров обработки больших данных (Big Data). Сегодня рассмотрим некоторые специфические ограничения, характерные для этой open-source платформы и способы решения этих проблем на реальных примерах. Все по плану: 5 особенностей...
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и...
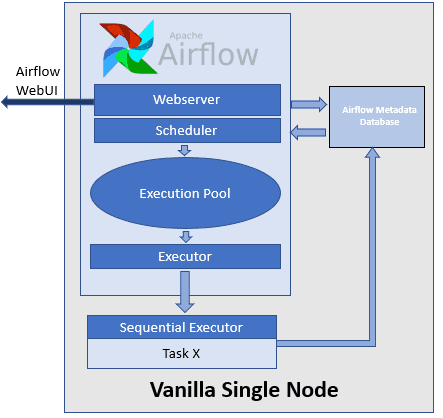
Недавно мы рассказывали про Airflow Kubernetes Executor, который позволяет выполнять задачи DAG-графа Эйрфлоу в среде Kubernetes, развертывая Docker-контейнер на отдельном пользовательском модуле (pod). Сегодня рассмотрим, какие еще есть исполнители задач в Apache Airflow, как они используются при автоматизации batch-процессов обработки больших данных и с какими проблемами можно столкнуться при их...
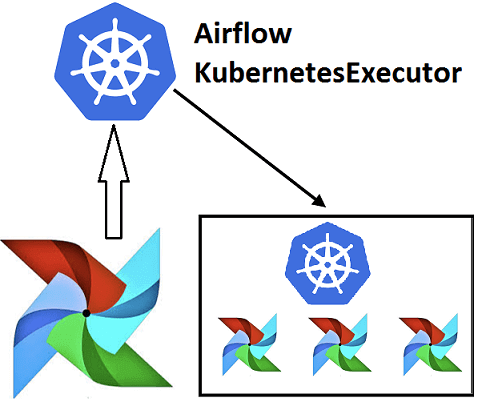
Эффективное обучение AirFlow, также как курсы по Spark, Hadoop, Kafka и другим технологиям больших данных (Big Data) также включают нюансы интеграции этого фреймворка с другими средами. Например, вчера мы рассматривали преимущества DevOps-подхода к разработке Data Flow на примере взаимосвязи Apache Airflow с Kubernetes посредством специальных операторов. Продолжая эту тему, сегодня...

Вчера мы рассказали, почему запускать Airflow на Kubernetes – это эффективно и выгодно для всех участников batch-процессов с большими данными (Big Data): разработчиков Data Flow, Data Scientist’ов, аналитиков и инженеров. Сегодня рассмотрим, что такое Airflow Kubernetes Operator и чем он отличается от подобной разработки компании Google. Как работает AirFlow Kubernetes...

Чтобы обучение Airflow было максимально приближенным к практике, сегодня мы поговорим про особенности реального внедрения этого фреймворка для разработки, планирования и мониторинга пакетных процессов обработки больших данных (Big Data) с учетом современного DevOps-подхода. Читайте в нашей статье, зачем вообще нужна связка Apache Эйрфлоу с Kubernetes и как это реализовать технически....

Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования. Чем хорош Apache AirFlow:...
В этой статье мы поговорим про Apache AirFlow - эффективный инструмент для пакетных ETL-задач при работе с большими данными (Big Data): что это такое, как работает и чем полезен для инженера данных (Data Engineer). Также рассмотрим несколько практических примеров реального использования этой библиотеки для разработки, планирования и мониторинга batch-процессов. Что...
В этой статье я бы хотел рассказать об основных концепциях Airflow и как с ним работать. Что такое Airflow? Airflow – это open-source оркестратор для управления процессами загрузки и обработки данных. Если у вас есть большое количество задач, запускаемых на cron, особенно, если между ними есть зависимости, то Airflow может...
Планируем рабочие процессы вместе с Apache Airflow Почему Apache Airflow? Большинство процессов обработки данных строятся на определении набора «задач» для извлечения, анализа, преобразования, загрузки и хранения данных. Например, последовательность обработки данных может состоять из таких задач, как чтение логов из S3, создание задания Spark для извлечения соответствующих объектов, индексирование объектов...